내 맘대로 Introduction
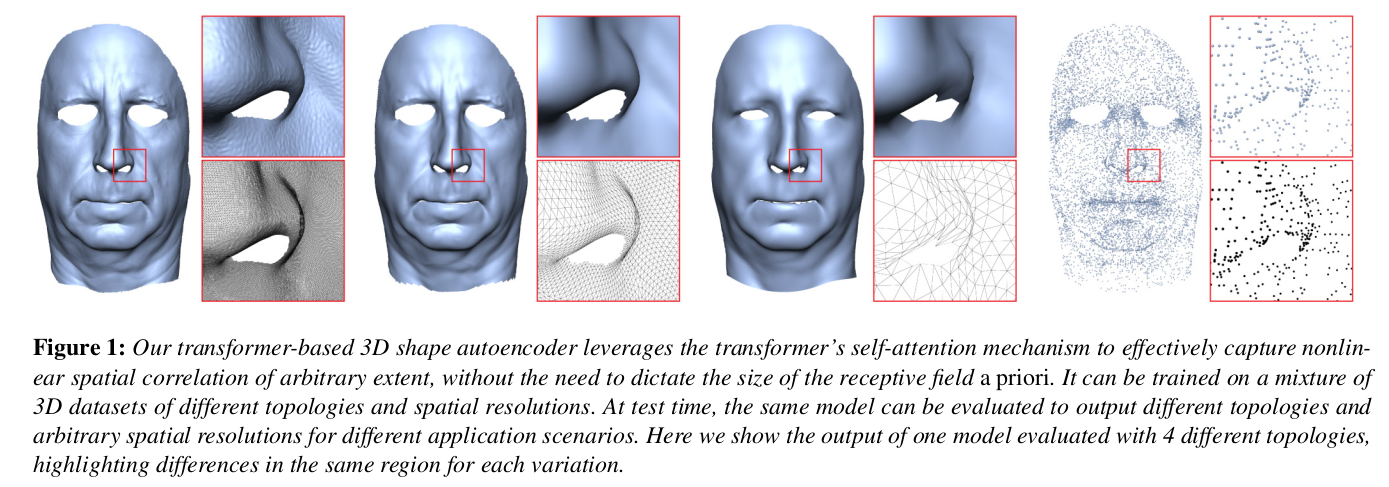
deformable mesh는 보통 template mesh에서 출발한다. 그 말인 즉, topology가 맨 처음 설계 당시에 정해지면 끝까지 모든 mesh가 같은 topology를 따라간다는 뜻이다. 한 번 topology가 고정되면 설령 같은 대상을 표현하는 mesh라도 서로 비교가 불가능해지는 문제가 있다. 예를 들어, 사람 1명 SCAN에 서로 다른 topology를 가진 mesh를 fitting했다면 결과물은 거의 동일하겠지만 topology가 다르므로 두 mesh는 비교하기가 어렵다. 어느 vertex가 어느 vertex와 대응되는지, normal을 비슷한지 비교할 수 없다.
이 논문은 이러한 문제점을 푸는 하나의 방법을 제시한다. 3D SCAN을 공통으로 표현하고자 한다는 것을 기준으로 서로 다른 topology로 표현된 mesh들을 모아 단 하나의 space로 모으는 작업을 했다. 보다 구체적으로 보면 mesh topology와 무관하게 mesh vertex를 갖고 shape code를 생성해둔다. 3d point to shape code, shape code to 3d point만 학습해놓는 것이다. 이러고 나중에 특정 topology화할 필요가 있다면 shape code만 기억했다가 해당 topolgy에 따라 결과 3d point를 다시 묶어주는 식이다.
크게 보면 implicit 하게 3D SCAN 네트워크가 들고 있고, 나중에 inference 단에 결과를 explicit하게 묶어주는 흐름이다. 이 논문 역시 아이디어 너무 좋고 구현도 간단. prashanth chandran 논문이다.
메모
  |
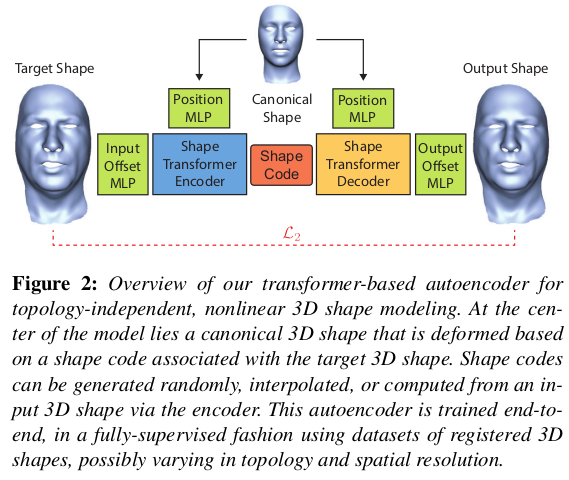 그림 보면 이해하기 쉬움. 1) mesh model registered on 3D SCAN <-> 2) mesh model in canonical 대응 데이터가 있어야 함. 1) - 2) offset을 입력으로 넣고, 대응되는 canonical mesh point를 position encoding해서 넣어줌 shape code 생성 shape code로부터 앞선 position encoding값 똑같이 넣어 다시 offset을 생성하는 일종의 VAE를 학습 ------------------ 학습할 때는 topology 정보를 사용함. SCAN <-> canonical tracking이 되어야 하니까. 하지만 결국 입력을 3d point query이기 때문에 학습만 된다고 하면 topology 정보는 inference할 때 전혀 쓸모없음. implicit하게 배우는 것. |
 |
shape code를 만들 때 그냥 learnable shape code를 SCAN마다 부여하고 최적화하는 식으로 구현할 수도 있었을 것. 하지만 굳이 3D point query offset을 입력으로 받는 경우를 만든 이유가 있음 1) 임의의 3d point를 다룰 수 있어야 함. -> shape code to N point의 N을 조절할 능력이 최적화로 찾으면 없음 2) local region 표현력을 가질 수 있도록 하기 위함 -> 만약 최적화로 찾았다면 shape code는 무조건 global code임 -> mesh의 일부만 사용하기 싶다하면 선택지가 없음. |
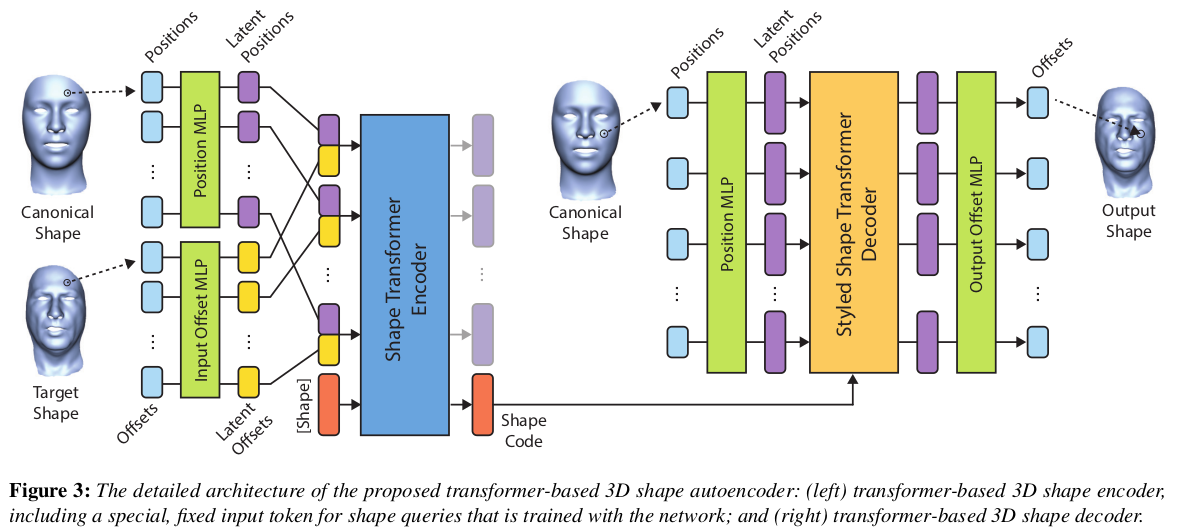 |
|
  |
구조는 위 그림을 보면 이해할 수 있으니 설명 생략. transformer를 쓴 이유는 몇 번을 설명하지만, 임의의 N point 입력을 받을 수 있도록 자유도를 열어주기 위함 + global/local 둘 다 가져갈 수있는 아키텍처임 shape code는 encoding transformer 결과에 MLP 달아서 뽑아내는 방식 아니고 token을 추가해서 넣어주고 결과로 나오는 해당 token을 사용함. 나머지 token은 버림. |
  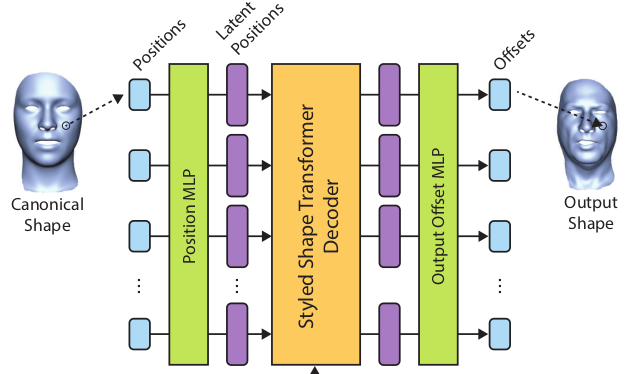 |
decoder에 shape code를 넣어줄 때는 왼쪽 그림처럼 input token에서 들어가지 않음. 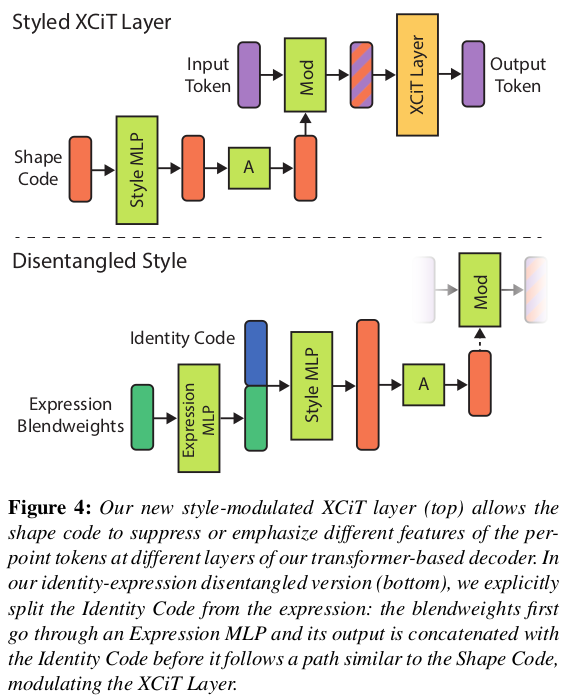 아래 그림처럼 shape code를 MLP 통과시켜서 token dimension을 맞춰준 다음 (encoder에선 query + PE라서 dimension이 큼, shape code 원래 해상도는 query + PE dimension이라서 decoder에선 query dimension으로 줄이긴 해야함.) decoder token에 "곱해주는" 형태로 들어간다. (cross attention도 좋았을 텐데 22년도라 그런지 그냥 이렇게 한듯) |
  |
임의의 N query point를 다룰 수 있긴 하지만 웬만해서 N을 mesh 전체를 덮을 수 있도록 크게 넣어야 한다. 이러면 NxN self attention complexity가 엄청 커지므로, 조금 줄일 필요는 있음. 이건 XCiT 에서 쓴 노하우를 썼다고 함(여기선 생략) |
 |
학습 데이터 준비가 핵심인데 앞서 말한대로 Registered mesh vs canonical mesh 있어야 한다. |
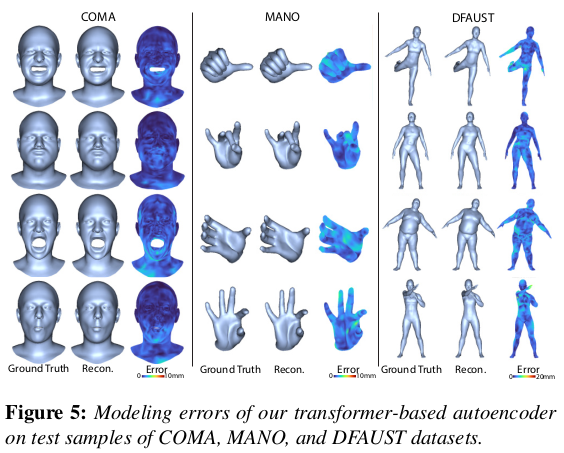 |
topology에 상관없이 shape 정보를 들고 있는 모델이기 때문에 mesh가 어떤 것이든 상관없음 얼굴, 손, 바디 전부 다 가능. |
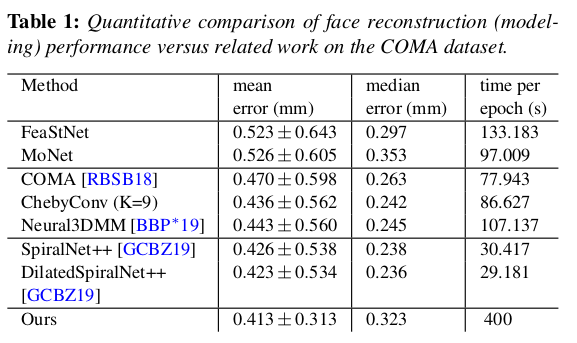 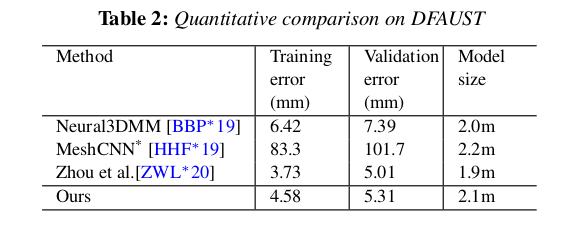 |
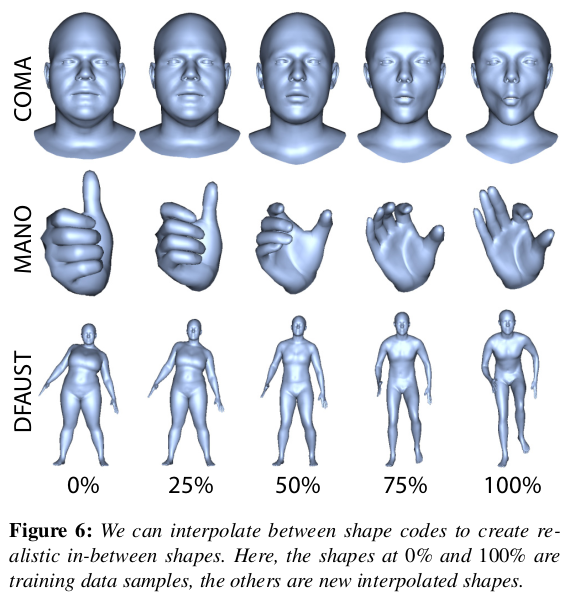 |
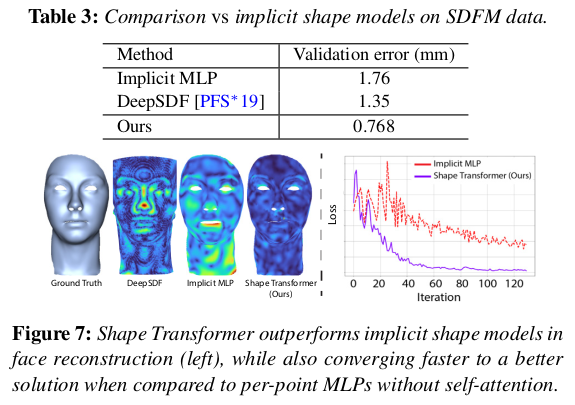 깡으로 네트워크가 통째로 들고있는 implicit 방식보다는 explicit 하게 query point 넣어주는 이 방식이 성능이 좋다고 함. |
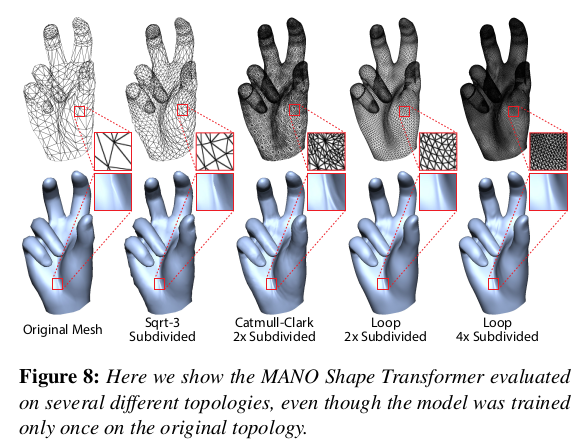 inference할 때 던져주는 query point를 새로운 topology vertex 순서대로 넣어준다면 위와 같이 topology 변경도 가능 |
 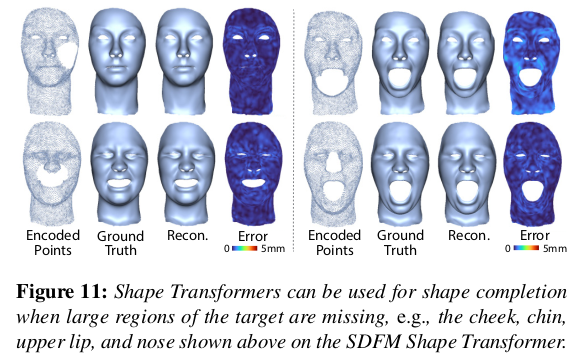 |
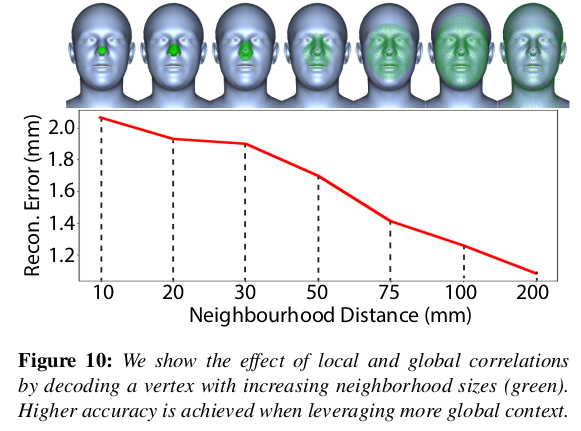 학습할 때 query point가 mesh 전체를 보도록 넓게 넓게 많이 많이 넣어주는게 좋음 -> 당연할 것이 전체를 봐야 좋지, 볼만 보고 눈을 어떻게 맞추나. |
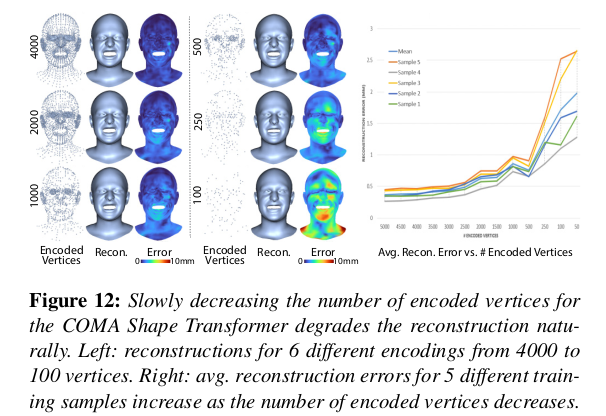 |
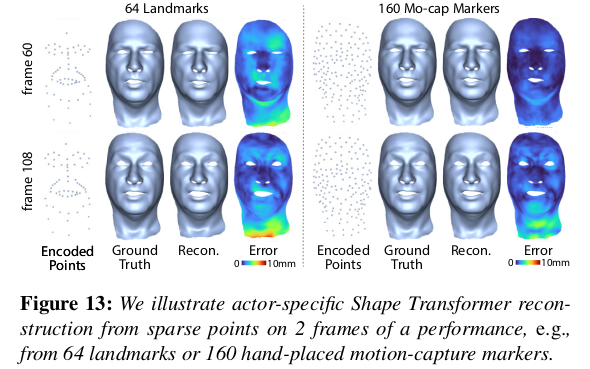 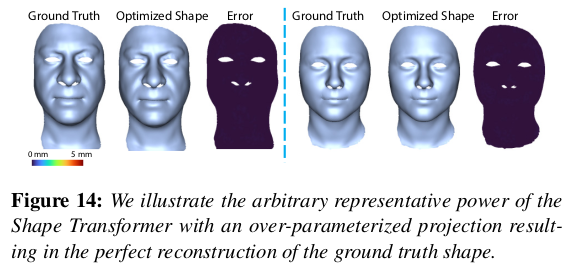 unseen도 잘하더라. |
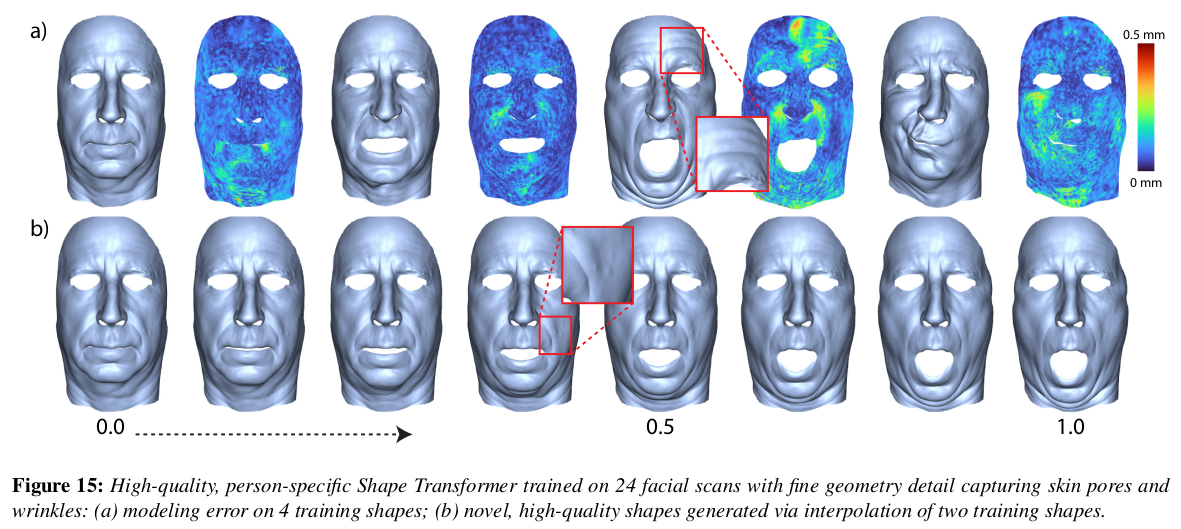 |
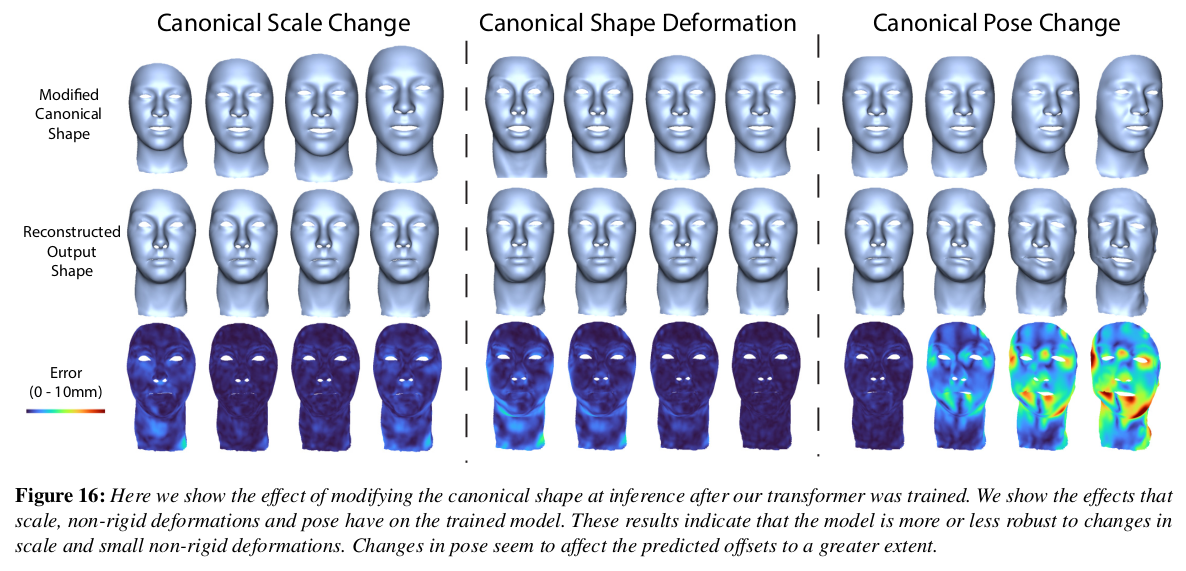 |
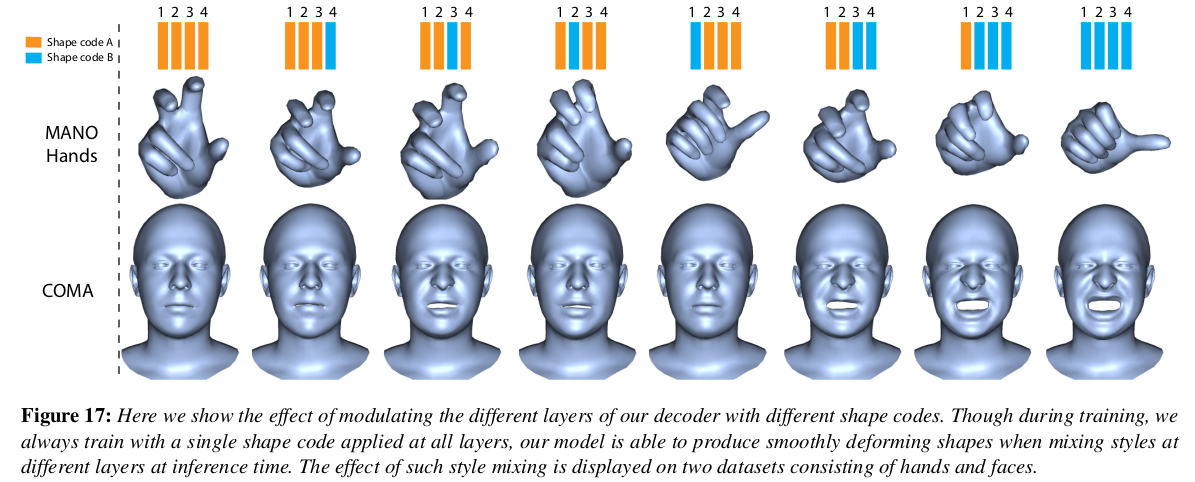 |
 |
'Paper > Human' 카테고리의 다른 글
| High-Resolution Neural Face Swapping for Visual Effects (0) | 2024.07.01 |
|---|---|
| Learning Dynamic 3D Geometry and Texture for Video Face Swapping (0) | 2024.07.01 |
| Continuous Landmark Detection with 3D Queries (0) | 2024.06.28 |
| Anatomically Constrained Implicit Face Models (0) | 2024.06.27 |
| FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset (0) | 2024.06.20 |