내 맘대로 Introduction

디즈니 리서치에 있는 chandran 이라는 사람 논문. 이전 Anatomically Constrained Implicit Face Models 논문 보고 되게 자유롭게 생각하는 능력도 뛰어나고, 구현력도 뛰어난 사람이라는 생각이 들었는데 다른 논문들도 아이디어나 완성도가 엄청 빛나는 논문들이라서 반했다. 2023년, 2024년 논문을 폭발적으로 쏟아내고 있는데 이 속도로 이 정도 완성도 논문을 쓴다는 것이 경이로울 정도다. 앞으로 이 저자의 논문 전부를 읽어볼 예정인데, 가장 먼저 잡힌 논문
이 논문의 아이디어도 엄청 빛난다. face keypoint detection은 고일 대로 고인 분야여서 더 이상 연구 분야로 잡기엔 정말 박터지는 분야인데, 성능을 끌어올리는 것과 별개로 face keypoint annotation이 데이터셋마다 다른 문제와 실제 찾고 싶은 keypoint가 기존 annotation에 없을 경우 찾아낼 수 없는 문제를 짚어서 새로운 방법을 뚫어냈다.
3D face model에서 query point를 뽑아온 다음, 해당하는 위치의 2D keypoint를 찾아내도록 설계하는 방식. 이렇게 하면 3D face model의 어느 위치를 뽑느냐에 따라서 2D keypoint를 원하는 대로 찾아낼 수 있다. 기존처럼 68개면 68개, 70개면 70개 정해진 위치의 keypoint만 찾을 수 있는게 아니다.
따라서 위 그림 (b)처럼 엄청 dense하게 뽑을 수도 있고, (a)처럼 기존 keypoint도 당연히 찾아낼 수 있다. 게다가 3D mesh vs image 간의 dense correspondece를 찾아내는 셈이기도 해서 model fitting을 시도할 시 (g)처럼 fitting할 수도 있다.
아이디어 자체가 엄청 좋은데, 구현한 방법도 그냥 CNN 하나, MLP 하나로 엄청 간단해서 감탄이 나온다. 아이디어가 좋다는 느낌의 논문을 오랜만에 본다.
메모
 |
기존 방식은 image feature extractor F + keypoint estimator P로 구성되어 있어서 정해진 개수 (68개)의 2d keypoint를 heatmap으로 찾아낸다. 전체 구조를 아주 약간만 바꿔서 keypoint estimator P에 feature를 넣어줄 때 3D canonical mesh model 상의 위치를 같이 넣어주는 방식으로 했다. 어떤 3d point를 넣어주면 그에 대응되는 2d keypoint가 이미지 상에 어디 있는지 찾아내도록 함. ----------- 데이터셋이 sparse keypoint여도 학습 가능 dense keypoint여도 학습 가능.. 기존 모든 데이터셋을 다 활용 가능해서 데이터 승부에도 압도적으로 유리함. |
  |
일단 데이터를 전처리 하는 방법은 off-the-shelf predictor를 이용해서 눈, 입 keypoint를 대략 찾고 이 위치가 이미지 중앙에 대략 오도록 normalization하는 것으로 끝. 이후에 ConvNext로 768 feature를 뽑는다. 이게 image feature extractor, F 끝. |
 |
3D query point encoder는 간단한 2겹의 MLP임 3d point xyz -> 64 feature로 encoding 끝. ------------- 3d query point 뽑을 때 꼭 mesh surface에서만 뽑을 필요 없다. 만약 mesh 안에 뼈 위치를 알고 있고 그 뼈 위치가 이미지 상에 어딨는지 correspondence를 알고 있다면 query point를 뽑아도 된다. 이러면 나중에 뼈에 해당하는 keypoint detection도 되는 것.. 진짜 열린 방법론이라 데이터만 있으면 다 가능. |
  |
수식도 설명할게 없다. 너무 간단함. query point 1개 -> keypoint 1개 찾는 네트워크니까. 찾는 keypoint가 N개 면 N번 병렬도 돌리면 됨. keypoint 개수에 따라 네트워크가 무거워질 일도, 재학습이 필요할 일도 없음. 활용성 굳. image feature는 한 번 뽑아두고 query point만 바꿔가면서 batch로 돌리며 되기 때문에 시간 오래걸리는 것도 큰 문제는 아니다. |
 |
image feature extractor 는 ConvNext query point encoder는 MLP2개 혹은 transformer 가능 transformer면 query point 여러개를 한번에 넣을 수 있음. self attention으로 인한 효과를 기대할 수도. (supplementary에 비교 실험이 있다는데 굳이 확인할 필요는 없을 듯. 이 논문은 아이디어 논문이니까) |
 당연히 기존 hand-labeled keypoint 데이터셋은 다 씀. |
 DatasetGAN을 활용하여 찍어낸 synthetic face도 활용 가능 |
  |
기존 데이터셋은 보통 sparse keypoint이고, sparse keypoint 사이 공간에 dense keypoint 추정 능력을 보강해줄 dense keypoint 데이터셋은 스튜디오 세팅에서 촬용한 데이터를 사용했다. 25000장 정도의 3D SCAN 시 촬영했던 데이터를 활용함. -> 이게 이 논문 성능 향상의 핵심재료.  약간의 AUGMENTATION으로 데이터 뻥튀기 효과 조금 첨가. |
 |
  |
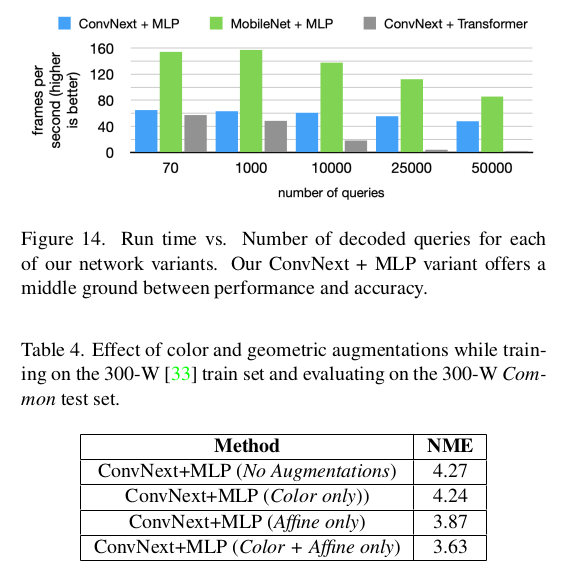
 성능은 Transformer가 조금더 압서긴 함. 이건 데이터 규모 차이도 조금 있을 것 같은데, 데이터가 디즈니 만큼 많지 않다면 MLP가 더 좋은 방식일 것 같다. |
 |
 난 특히 이부분이 맘에 든다. 3D query point - 2D keypoint correspondence를 찾는 네트워크일 뿐이지만 활용하기에 따라 semantic mask를 얻을 수도, image editing에 활용할 수도 있다는 점. |
 데이터만 있다면 뼈같이 mesh surface가 아닌 영역의 keypoint도 찾아낼 수 있다는 점...  모든 데이터셋에서 다 찾는 눈에 대해서는 특히 잘 되나 봄. |
 fitting gt로 써도 될만큼의 성능... 이 간단한 네트워크로 얼마나 많은 문제를 한 번에 푸는거지. |
 |