반응형
내 맘대로 Introduction
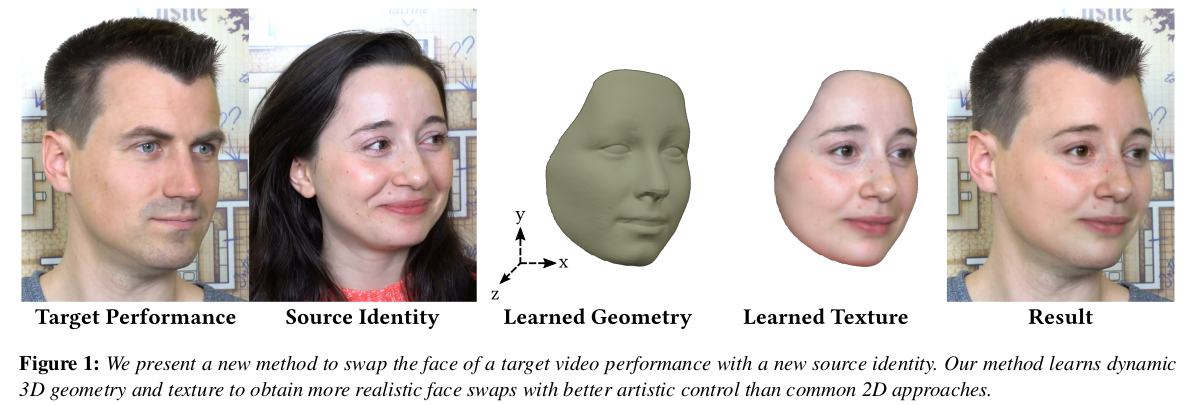
디즈니에서 만든 face swap 논문. face swap이라는 문제 자체는 워낙 오래되었고 레드오션이기 때문에 문제를 조금 확장해서 풀었다. face swap을 2D image level에서 벗어나 3D geometry 획득까지 엮어서 풀었다. 그리고 기존 방식들은 generalized model이었는데 이 경우, generalized model로 만들 수는 있으나 N=2로 한정함으로써 두 사람 간의 swap에 집중하도록 설계했다.
결과적으로 두 사람 간의 face swap 이미지만 얻어내는 것이 아니라 3D geometry까지 얻어내서 추후 다른 작업들의 가능성을 열었다. geometry를 늘리거나 수축시키는 변형이나 texture editing 같은 것이 기존 디자이너들의 도움을 받아 그대로 이루어질 수 있도록 했다.
같은 문제지만 훨씬 활용성 좋게 풂과 동시에 성능도 만족시킨 논문. 이 역시 방법론은 심플하고, 생각할 법 하나 application까지 고려해서 아이디어를 잘 짜낸 논문.
메모
 |
학습은 1명씩 한다. Auto encoder 구조로 identity에 상관없이 정보를 뽑는 encoder, 이를 identity specifi 형태로 복구하는 decoder . encoder는 따라서 shared weight이고, decoder는 사람 수만큼 존재한다. 알고리즘 결과물인 3D geometry와 texture는 전부 UV mapping된 2D 형태로 나오고, 나중에 이를 3D 로 복원하는 방식. 복원된 3D를 렌더링해서 이미지에 블렌딩하면 FACE SWAP 이미지가 만들어지는 순서 -------------- 학습 데이터는 두 사람의 2~6분짜리 비디오 Sequence다. |
  |
각 사람 별 영상은 1) 눈, 코, 입 keypoint를 갖고 영상 중앙으로 옮기고, 512 512 사이즈로 resize하는 전처리 2) 3DDFA를 활용해서 FLAME 모델 피팅 결과를 뽑아 두기 -> 이게 알고리즈 성능에 정말 핵심적인 초기값인데, 기존 것을 그대로 쓰진 않았을 것 같다. -> 갖고 있는 데이터로 자체 3DDFA 학습해서 쓰지 않았을까 싶다. 3) BiSeNet 이용해서 face mask 따두기 |
 |
|
  구조는 위와 같이 1 encoder 2 decoder 형태의 Auto encoder다. 1 encoder는 사람 전체에 공유되는 1개 (shared weight) decoder 1은 사람 1명마다 있는 geometry 예측 용 decoder 2는 사람 1명마다 있는 texturemap 예측 용이다. |
 geometry는 scratch부터 맞추도록 하면 당연히 성능이 작살나고 topology도 없기 때문에. 3DDFA 결과를 초기값으로 하고, residual을 계산하도록 했다. -> 따라서 3DDFA가 엄청 잘되어있다는 가정임 -> 그리고 uv unwrap되어있는 형태. xyz, rgb 둘 다. uv domain ---------- 빛은 명시적으로 다루지 않는다. 그냥 encoder에 의해 implicit하게 담기도록 했다. 여기서 N=2 밖에 안되므로, 그냥 촬영된 두 영상의 빛을 담고 있게 됨. 근데 N이 커지면 빛이 어떻게 될지는 미지수.. -> 사실 상 신경 안 쓴 것. |
    1) color는 SSIM loss로 (with mask) 2) mask loss (전체 라인 잘 맞도록) 3) geometry가 부들부들하도록 laplacian smoothing |
  regularization은 두가지 geometry 예측값이 residual을 의미하므로, 일단 3DDFA 피팅 결과를 깔고 가는 상황에서 예측값이 크면 안된다. -> 학습 초기에는 아예 예측값이 0에 가깝도록 함. 3DDFA 결과에 의존해서 Feature를 잘 뽑도록 일단은 학습 -> 이후에 geometry residual 예측값을 무표정 FLAME vs fitted 3DDFA FLAME 간의 차이와 유사하도록 한다. -> 무슨 말이냐면 현재 geometry 상태를 FLAME 모델만 갖고 최대한 표현했을 때 displacement와 크게 다르지 않도록. -> 3DDFA 결과에서 크게 벗어나지 않도록 억제.  학습 때는 N=2를 주거니 받거니 1번씩 업데이트. 동시에 학습하는 방식 encoder가 shared니까 당연. |
 |
regularization이 복잡했나보다. 아무래도 diff.rendering만 사용하다보니 그런 듯. normal이 있는 것도 아니고. |
 결과 geometry에 texture를 입혀서 렌더링하면 하면 됨. |
 같은 FLAME 모델인데 모양이 다른 이유는, 3DDFA 알고리즘에서 visibility 체크를 한 것 같다. |
 |
|
  |
 |
 |
 |
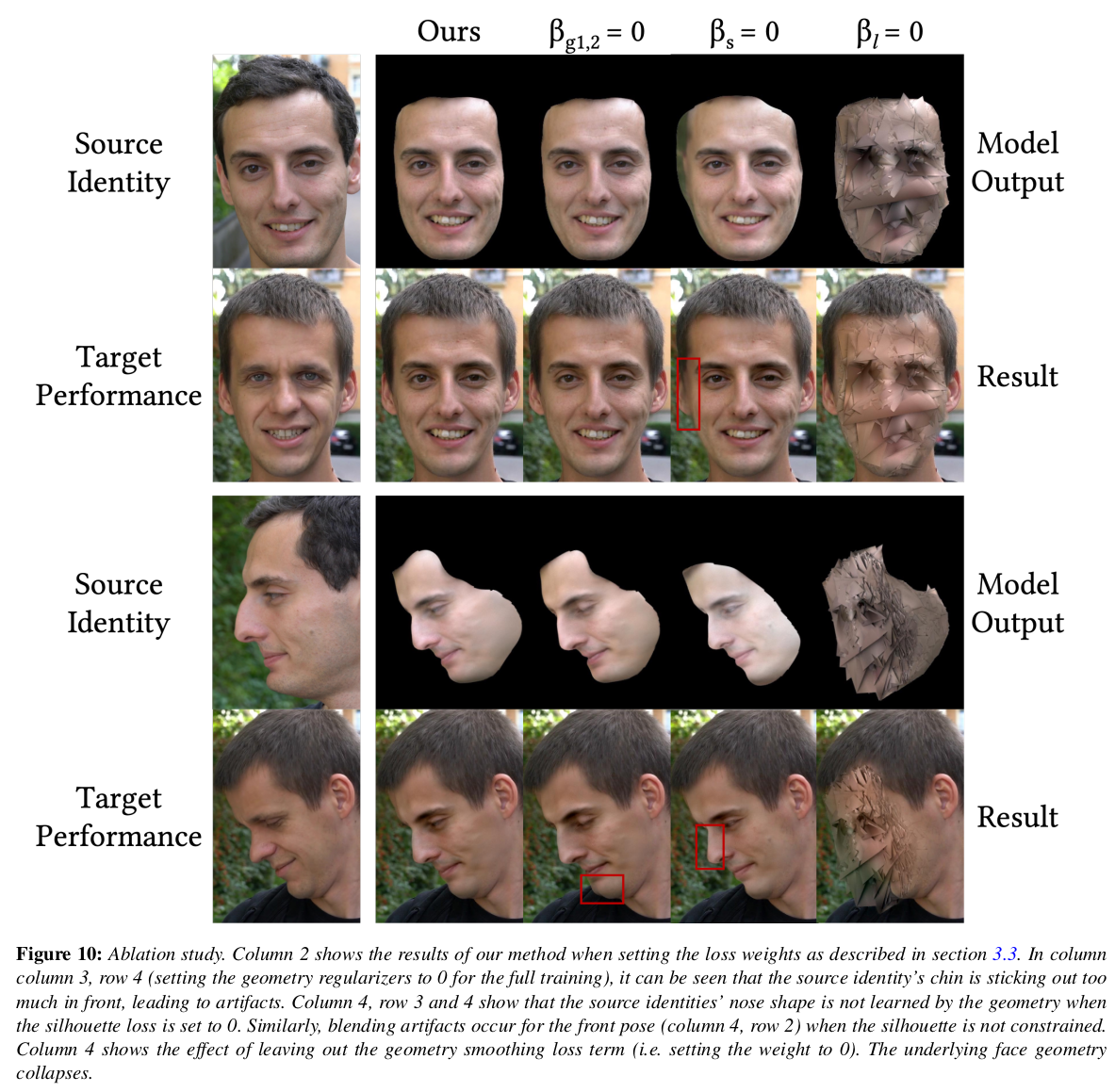 regularization을 뺐을 때는 턱모양이나 얼굴 컨투어가 좀 뭉개지는 문제. smoothing이 없으면 그냥 망함. |
|
 |
치아와 눈동자는 사실 FLAME에서 명시적으로 안 다루니까 할 수 있는 내용이 아닌 것 같다. |
반응형
'Paper > Human' 카테고리의 다른 글
| Local Anatomically-Constrained Facial Performance Retargeting (0) | 2024.07.02 |
|---|---|
| High-Resolution Neural Face Swapping for Visual Effects (0) | 2024.07.01 |
| Shape Transformers: Topology-Independent 3D Shape Models Using Transformers (0) | 2024.06.28 |
| Continuous Landmark Detection with 3D Queries (0) | 2024.06.28 |
| Anatomically Constrained Implicit Face Models (0) | 2024.06.27 |