반응형
내 맘대로 Introduction

FLAME 다음으로 동양인 버전 parametric face model이다. 생성 방식은 똑같이 3D SCAN 뜨고 나서 template model, non-rigid ICP -> PCA 순서지만, 뒤에 StyleGAN을 붙여서 detailed mesh로 업그레이드 할 수 있도록 했다. 다시 말하면 기존 모델 + 업그레이드 네트워크를 같이 제공하는 셈. 따라서 요구 정확도에 따라 기존처럼 그냥 PCA 기반 모델로 끝내도 되고 더 필요하다면 뒤 네트워크까지 통과시키고 쓰면 된다.
개인적으로 생성 방식에 contribution이 있다기보다 동양인을 이용해 만든 모델이라는 것이 의미가 있고 생각한다. FLAME이나 BFM 같은 모델들이 서양일 얼굴 스캔으로 만들었다 보니 동양인 얼굴 표현력이 떨어지는 문제가 있는데, 이 모델은 아예 동양인 얼굴로 만들었기 때문에 표현력에서 훨씬 뛰어나다. 게다가 만들 때 사용한 데이터 양이 중국이다보니 어마어마해서 latent space도 더 정확할 것 같은 기분.
메모
  |
 일단 3DSCAN + PCA 조합으로 기본 모델을 만드는 단계는 기존 방식 그대로 RGBD 스캔을 이용했다. 5대 6만 촬영 point cloud 얻은 뒤 template non rigid ICP ----- 연령 분포는 젊은 세대가 많고, 성비는 여성이 더 많음 나도 이런 촬영해봤지만, 피실험자 지원자 중에 여자가 압도적으로 많다. 나이 드신 분들은 오히려 남자가 많은 것도 특징. 중국도 똑같은 듯. |
 |
 detail 버전 (StyleGAN 붙여서 보강할 버전) 데이터는 따로 찍는다. 같은 사람을 장소 이동시켜서 촬영한 것이기 때문에 base model - detail model SCAN 간에 매칭이 가능함. -> non rigid ICP할 때 base model 활용 함. -> 수렴 훨씬 빨리하고 성능 좋을 듯. DSLR 128대, 6000x4000 해상도, 110명+18명 |
 |
|
  |
base model 생성방식은 기존 SMPL이나 FLAME과 동일함 shape parameter 100 +20 texture parameter 200 <-texture까지 파라미터화 한것은 차이 expression parameter 64 shape paramter +20개는 detailed model (3D SCAN from DSLR + non rigid icp +PCA)로 만든 것의 가장 큰 eigenvalu 20개 뗘온 것. -> 이게 하나 의문인게, 같은 시점에 RGBD랑 DSLR로 찍은게 아니라서 분명 약간 차이가 있을텐데 그냥 뗘다 붙였다. -> 같은 사람한테 같은 무표정 지으라고 한 거니까 그냥 퉁치는 건가. -> 왜 붙이는게 더 낫다고 판단했는지 설명이 안되어 있음. |
  |
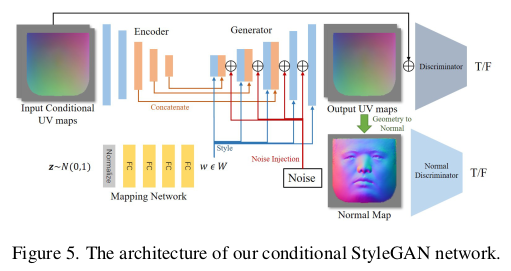 base model에서 detail model로 더 나아가고 싶다면 styleGAN을 통과시킨다. 네트워크는 앞선 base model uv map (256 to 1024 upsampled)이랑 같은 사이즈 texturemap을 입력으로 먹고 업데이트된 texture와 uv map을 내뱉는다. (형상 보정+텍스처 보정) 이 때 latent z와 noise를 추가해서 condition으로 넣어주는데 이는 학습 단계에는 그냥 gaussian z, random noise로 들어가지만 학습이 완료되면 이 각각이 의미하게 되는건 z : 보정의 방향성을 제시하는 latent noise : 안경, 수염 같은 마이너한 변화를 제시하는 latent가 된다. ---------------- 나중에 학습 완료된 이후에 base <-> detail model 간에 model freeze 해두고 z와 noise를 최적화로 역추정해내서 사람 별로 latent z와 noise 를 찾아두고 사용함. --------- loss는 base model과 크게 달라지지 않도록 하는 regularization을 기본으로 하고 GAN loss |
  |
지금까진 shape에 대한 업데이트만 진행한 것. expression (표정)에 의한 변화도 detail하게 업데이트가 가능함 -> 사람마다 같은 표정이라도 미세한 움직임이 다른 걸 모델링 가능 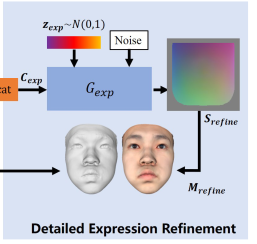 똑같은 구조의 StyleGAN을 한 번 더 붙이는데 이 때는 texture는 안 들어간다. uv map 만 들어가서 표정에 대한 uv offset을 뱉도록 학습. 이 때도 마찬가지로 latent z와 noise가 들어가는데 이 두 값은 학습 완료된 이후에 역 최적화로 사람마다 expression latent z를 찾아놓음. |
  |
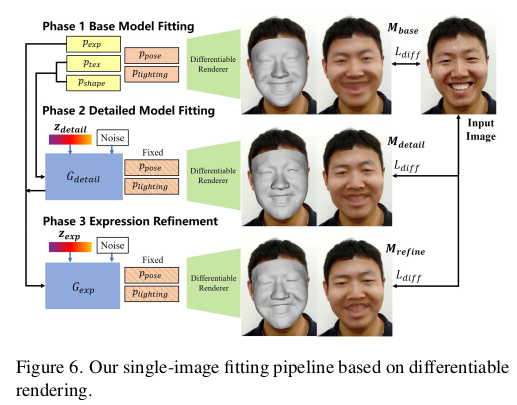 모델을 만든 것으로 끝내면 논문이 아쉬우니, 마지막에 만든 모델을 이미지에 fitting하는 파이프라인도 제공함. differentiable render, photometric loss를 기본으로 landmark랑 같이 fitting하는 순서인데 base model shape refine expression refine하는 순서로 앞서 설계한 모듈 하나하나 순서대로 최적화 하면 된다. ----------- 이게 중요한 내용이 아니니 굳이 크게 안봐도 될 듯. |
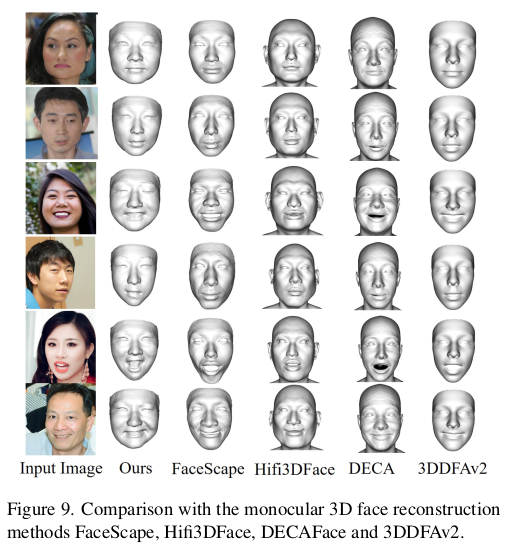
 동양인 데이터여서 그런지 진짜 표현력 하나는 끝내주는 듯. |
 |
 |
 |
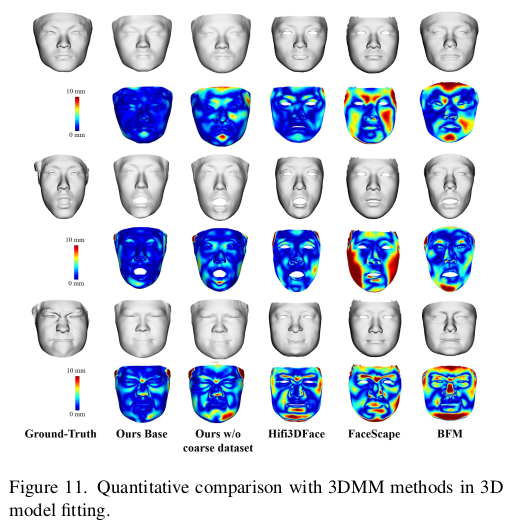 |
  |
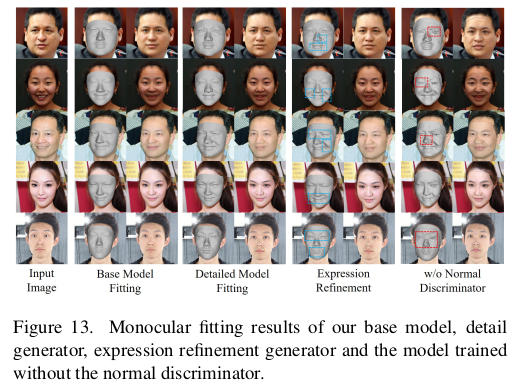 |
  limitation이라고 적은 것은 사실, 모델 잘못이라기 보다 데이터가 커버하지 못한 부분 같다. 게다가 저런 수염이 굵은 건 수염 뿐만 아니라 서양인이 그런 사람이 많은 영향도 있을 듯. 14번 그림 texture만 봐도 동양화 된게 보임. |
반응형
'Paper > Human' 카테고리의 다른 글
| Continuous Landmark Detection with 3D Queries (0) | 2024.06.28 |
|---|---|
| Anatomically Constrained Implicit Face Models (0) | 2024.06.27 |
| 3D Gaussian Blendshapes for Head Avatar Animation (0) | 2024.06.19 |
| gDNA: Towards Generative Detailed Neural Avatars (0) | 2024.05.30 |
| Neural Cloth Simulation (0) | 2024.05.28 |