반응형
내 맘대로 Introduction

신선하고 결과물이 좋은 생성형 모델 논문들은 알리바바가 요즘은 꼭 껴있는 것 같다. 알리바바가 대형 온라인 마켓을 갖고 있다보니 이런 commercial object 사진들을 보유하고 있는 거대기업이라서 그런 것 같기도. 알고리즘보다 데이터 규모에서 따라갈 수 없을 것 같다는 격차를 느낀다... 알고리즘 성능 속에 데이터 힘이 차지하는 부분이 얼마나 될까.
이 논문은 이미지에 box, contour 등을 그리면 해당 위치로 원하는 object를 옮겨 inpainting해주는 논문이다. object teleporation의 영역이기 때문에 활용하기에 따라 virtual try on 부터 scene editing, shape editing 같은 것이 가능해지는 범용적 알고리즘이라고 할 수 있겠다.
핵심 아이디어는 1) object ID, detail feature를 뽑는 법 2) 위치 정보를 어떻게 넣어줄지 3) SD decoder까지 튜닝 범위에 넣은 것이다. 다른 것들은 무시하더라도 3) SD decoder의 튜닝을 직접 시도했다는 것은 알리바바 급 데이터가 있었기 때문에 가능한 것 같다. 기존 SD 모델을 건들기 시작했다는 점이 다르다.
메모
 |
|
 |
전체 구조는 영역 정보랑 사물 정보를 합치고 controlnet 구조로 SD에 넣어주는 구조다. 1) 영역 정보랑 사물정보를 어떻게 뽑는지 2) SD 넣어주고 decoder까지 포함해서 튜닝하는 것이 핵심 |
  |
ID 정보를 뽑는 것은 DINOV2를 차용했다. DINOV2 + 1 MLP로 구성함. 이유는 DinoV2가 semantic information을 잘 뽑아주는 네트워크임이 밝혀졌기 때문. 데이터를 많이 먹은 네트워크여서 범용적이기 까지 하니까 차용한 듯. token dimension이 1536인 것은 patch가 48x32개, 각 patch가 16x16 pixel로 구성되어 있어서 그런 것 같다. 입력 이미지를 768x512로 썼지 않을까 싶다. |
  |
ID token도 사물정보를 뽑는 영역이지만 semantic info. level에 집중했으므로 사물의 디테일 형상 정보는 담고 있지 않다. 따라서 별도로 사물 디테일 형상 정보를 담을만한 feature를 추가함. 바로 High frequency map 이미지를 흔히 아는 sobel filter 통과시켜서 high frequency 영역만 추출해서 이를 입력으로 같이 넣어주도록 했음. 이걸 안하면 영역 지정해줬을 때 영역 모양에 너무 형상이 고정되는 부작용도 있었기 때문에 여러모로 좋았다고 함. ----------------- 영역 모양 타는 문제도 있었으므로 box, contour가 주어졌을 때 확률적으로 30% box를 무시하게 하거나 mask를 erode해서 사용하거나, aspect ratio를 변경해주는 식의 augmentation도 섞어주었다고 함. mask가 계속 바뀌니까 mask를 너무 믿지 않고 생성하게 학습하므로써 생성 자유도를 높여주는 방식 최종적으로 만들어진 feature들은 ControlNet처럼 SD에 연결.  |
  |
SD에 앞선 feature들을 ControlNet 방식으로 연결한 이후에 수식(2)처럼 "image level" loss로 학습을 한다. 이 방식이 기존 LDM의 noise, eps level loss로 학습하는 것과 다르다. -> 결국 결과물의 detail이 살아나는 것이 중요하므로 image level에서 loss를 사용한듯 -> 더 나아가서 SD decoder도 튜닝하기 때문에 가능한 접근인 듯. SD decoder의 각 feature에 detail map feature를 concat해서 튜닝에 사용하도록 함 ----------- 이부분 개인적으로 image level loss로 회귀한 것 괜찮은 듯. |
  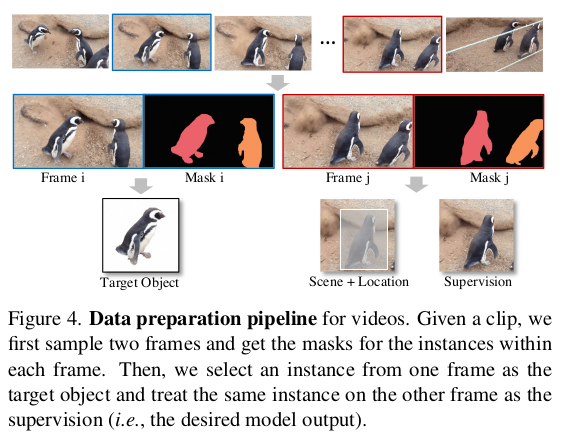 |
 같은 물체가 다른 위치에 등장하는 데이터를 구하기가 힘들긴 하니까, 비디오 데이터셋을 활용했다. 한 물체를 지속 촬영한 비디오라면 같은 물체가 다른 위치에 등장하니까 말이다. 왼쪽 그림처럼 i <-> j frame을 묶어서 데이터로 생성해서 사용함. |
 |
학습 디테일. (이런 부분 상당히 맘에 든다.) LDM 논문을 보면 early step에서는 low freq 정보를, late step에서는 high freq 정보를 복원해낸다는 분석이 있다. 따라서 데이터를 활용할 때 비디오는 보통 화질도 안 좋고 모션 블러도 있으니 low freq 정보 (대충 형상) 배울 때 많이 쓰이게 하고 이미지는 화질도 좋고 모션 블러도 없으니 high freq 정보를 배울 때 많이 쓰이게 했다는 것이다.  이 수식을 사용해서 loss를 계산할 때 저 t가 1000 step이라고 해서 1000번 계산하면 메모리 터질 테니까 몇개의 t값을 뽑아서 loss를 계산할텐데 이 때 비디오는 500~1000 구간에서 50% 이상, 이미지는 0~-500 구간에서 50% 이상 뽑도록 했다. (0 쪽이 이미지에 가깝고, 1000 쪽이 gaussian noise에 가까운 것) |
 |
 |
 |
 |
 |
 |
 |
  |
반응형