반응형
내 맘대로 Introduction

AnimateDiff가 맨 처음 본 논문 형태로 그대로 CVPR된 줄 알았는데, 다시 보니 reject 됐었나보다. ICLR 2024에 포맷팅 변경 + 추가 튜닝 경험들을 녹여서 다시 냈고 spot light paper로 accept됐다. (학회 별로 극과 극을 달리는 평가를 보면 진짜 리뷰의 퀄리티가 이제는 바닥을 치는 듯.)
아무튼 새로 업데이트된 내용이 좀 있길래 추가 정리한다.
메모
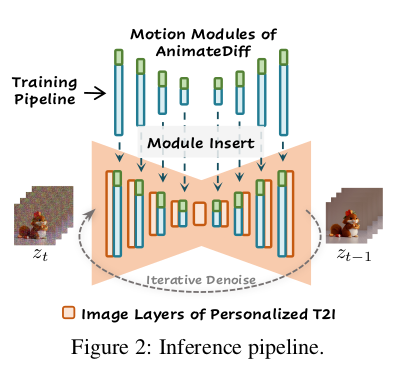 |
이전에 리뷰한 바가 있으니, 차이점 부분만 언급하면 다음과 같다. 1) 기존 motion module에 LoRa를 추가해서 fine tuning용 데이터가 있을 시 해당 데이터에 특화된 motion module로 업데이트할 수 있도록 함 2) domain adaptation용 LoRa도 추가해서 입력 이미지의 도메인에 해당하는 부분이 LoRa에 의해 encoding되도록 함. |
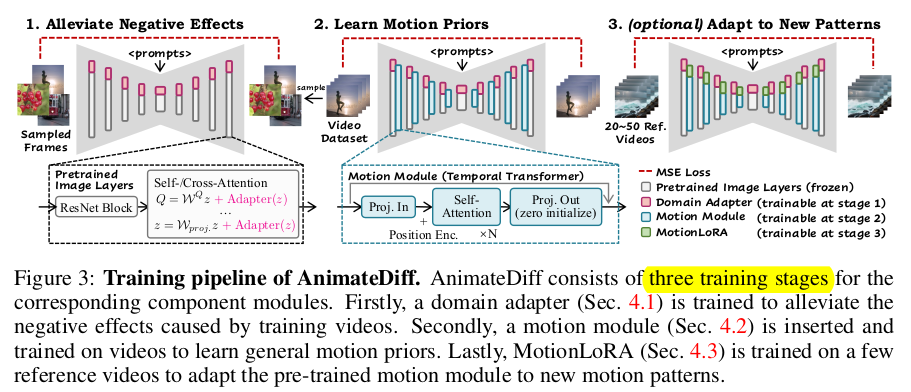 |
|
  |
입력 이미지들마다 blur 정도부터 조명 차이, 아예 그림체의 차이까지 도메인이 다양하게 다르므로 이를 커버하기 위한 domain adapter, LoRA를 추가함. 확실히 LoRa가 입력 도메인 갭을 줄이도록 마진을 배울 것이므로 효과적인 듯. (이게 새로 추가됨) |
  |
motion module은 똑같음 time dimension이 늘어서 5차원이 된 입력을 다루기 위해 (b h w ) c f 와 같이 batch 차원으로 reshape하는 트릭을 구사함 ------ spatial 정보를 아예 버리는 것 같지만, SD에서는 여전히 쓰고 있기 때문에 여기선 버려도 됨. ----- design tip self attention 전에 PE 넣을 것. 끝나고 zero init. + residual connect 넣으면 좋음. |
 |
위 작업으로 사실 끝이었는데. 튜닝용 데이터가 추가로 정해져있다면 motion module에 LoRa를 달아서 최종 튜닝 한 번 더 해주면 잘됨. |
 |
loss 자체는 diffusion loss 그대로인데 time dimension이 추가되어 N개가 존재하므로 N개 각각 다 처리해주는 방식. |
 |
 |
 |
|
 |
총평 domain adaptation용 LoRa 아이디어 매우 좋음. 잘 추가된 듯. 구현적 완성도 높아진 느낌. |
반응형