반응형
내 맘대로 Introduction

pose, shape 파라미터 넣으면 naked human body는 얻을 수 있다. SMPL이 대표적인 예. 여기서 detail 파라미터가 만약 존재한다면 clothed human body까지 얻을 수 있지 않을까?
위 질문으로 시작한 논문 같다. 3D SCAN 데이터 대량을 활용해서 SMPL 위에 얹은 deformation (cloth) 파라미터를 학습시킨 내용이다.
결과적으로 pose, shape, detail 파라미터를 넣으면 clothed human body mesh가 나온다.
메모
|
|
|
1) detail 파라미터 + shape 파라미터 넣으면 Canonical volume (3D) 상의 occupancy랑 normal을 뱉어주는 네트워크를 학습시키는 것이다. 2) canocnial volume 상의 canonical human은 T-pose의 SMPL이다. 3) detail, shape 파라미터로 만든 mesh를 forward skinning + pose 변화 이후 3D SCAN과 supervision, rendered normal 과 2D supervsion을 통해 학습한다. |
|
Canonical 3D representation은 위 그림과 같다. 1) shape 파라미터 (SMPL꺼 아님)를 받으면 정해진 3D voxel에 T- pose Occupancy를 채워준다. (T pose smpl일텐데 shape 파라미터 없이 그냥 body size independent T pose SMPL인 듯) 2) voxel 하나 하나마다 nerf 처럼 occupancy, normal 예측. occupancy feature가 normal 예측에 들어가는건 VolSDF류랑 같음. |
 |
canonical 3D -> deformed 3D로 변형하기 위해선 skinning weight가 필요함 (SMPL bone으로 조종하기 위한) canonical point -> skinning weight 추정하는 네트워크 학습하는 식. |
  |
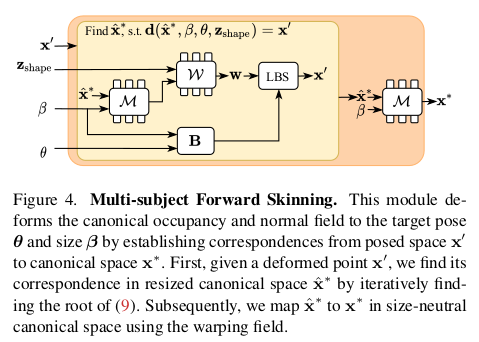 구체적인 입력은 다음과 같음 1) skinning weight deform(canonical point, smpl shape) + shape 파라미터 smpl bone을 이용해 skinning하는 것이므로 smpl shae 파라미터와 풀어야 한다. 근데 기존 갖고 있는 shape 파라미터는 smpl shape 파라미터와 다름 따라서 M (warping field) 모듈을 이용해 canonical point -> smpl point로 옮겨주고 skinning weight 계산 smpl bone, smpl pose 파라미터로 LBS 해서 최종 deformed point 생성 |
 |
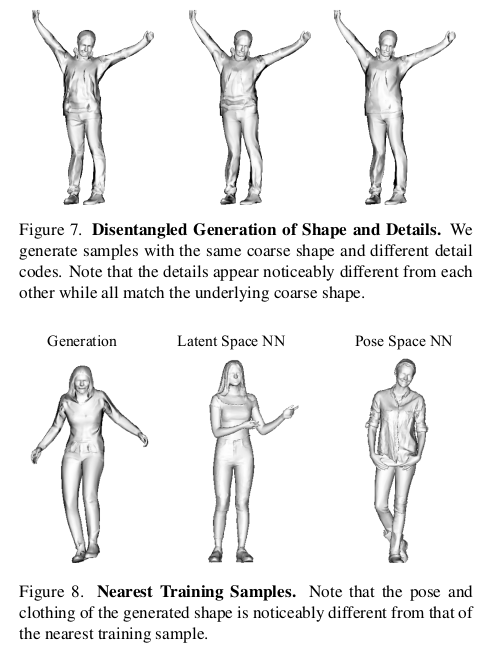
deformed point 와 3D SCAN 간의 비교를 해야함. nearest point 찾아서 correspondence로 지정 후에 loss 계산 |
  |
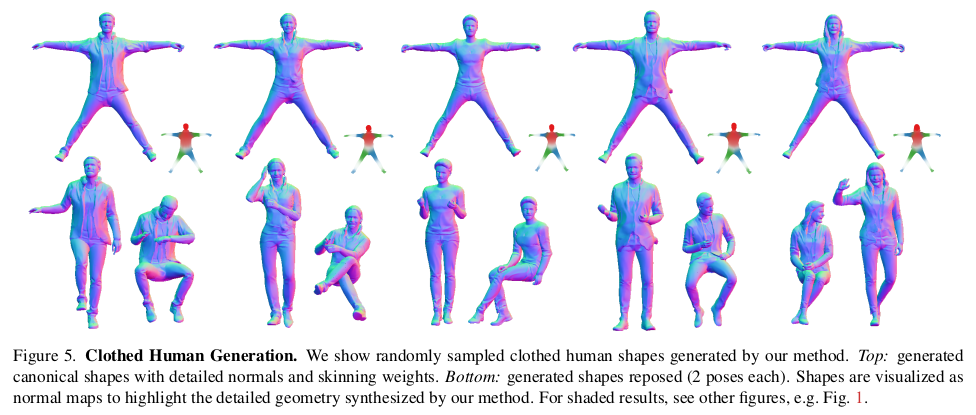
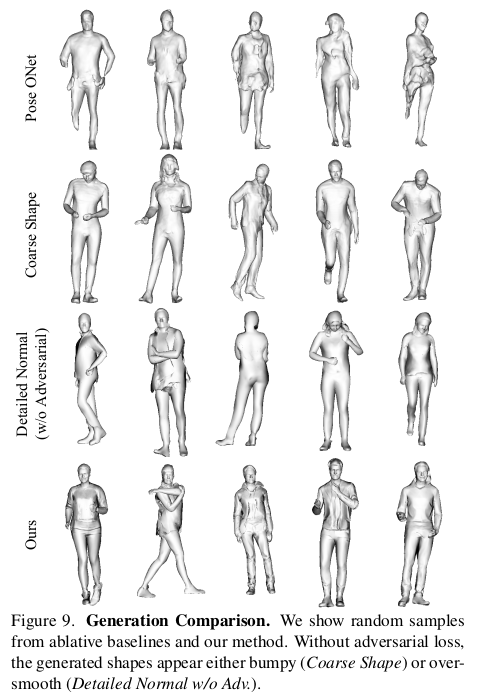
이렇게만 했을 때 학습이 잘 안됐나봄. 2D rendered normal을 만들어서 adversarial loss로 보강. |
 |
|
 |
|
 |
  |
 |
 |
반응형