반응형
내 맘대로 Introduction

SMPL + garment mesh sequence가 주어졌을 때, garment의 변형을 학습해서 unseen pose에서의 garment deformation을 예측할 수 있도록 하는 논문. SMPL pose 파라미터에 의존적으로 변형 가능하도록 하므로 SMPL + Garmet binding이라고 보면 된다.
옷마다 따로 학습해야 하는 것이고, SMPL sequence + Garment mesh sequence가 주어져있어야 한다. 다른 말로 모든 vertex가 추적 가능한 상태여야 한다. garmet vertex, x가 매시점 tracking되어 있다는 것을 전제로 하기 때문이다.
사실 상 vision task라기 보다는 graphics task다.
메모
|
문제를 정의하길 옷 vertex의 현 상태는 사람의 자세, 그리고 이전 옷 vertex의 위치 그리고 그 속도에 의해 결정된다. (합리적인 듯.) 이전 옷 vertex 위치는 또 역시 그 이전의 사람의 자세, 그리고 그 이전의 옷 vertex위치, 속도에 의해 결정되는 recursive한 구조 -> 네트워크를 RNN을 쓴 이유 따라서 옷의 변형을 계속해서 recursive하게 따라가다보면, 결국 옷은 초기 static shape에 사람 자세가 더해진 변형이라는 결론. -> 따라서 static 옷 한번 풀고 사람 자세에 대해서만 풀면 된다. |
|
옷의 현 상태는 옷의 초기 상태 + 사람의 자세가 결정한다는 위 가정을 그대로 수식으로 표현하면 수식(3)과 같을 것. 이 때 옷의 현 상태를 표시하는 subspace(latent)가 있다고 생각함. (subspace의 가장 큰 구심점은 static 옷 상태일 때 latent.) 옷 latent는 위 가정에 의하면, 사람 자세를 보면 알아낼 수 있을 것. |
|
|
  |
네트워크의 구조는 recursive한 가정이기 때문에 RNN 추가적으로 static 옷 상태는 매 시점의 옷상태와 독립적으로 존재하며, 매 시점 옷 상태에 영향을 주는 공통 요소로 존재해야 하므로 static encoder와 dynamic encoder가 나뉘어지도록 디자인함. |
 |
매시점의 옷 변화를 표현하는 값은 z_t 임. (매시점 옷 latent 값) 근데 이 값은 사람의 자세 theta_t로부터 만들어지는 것이니 시작부터 말하면 body motion을 표현하는 descriptor는 사람 자세 sequence다. (추후 encoder 통과하면 z_t가 됨) body motion은 모든 sequence를 넣지 않고 sliding window 식으로 현 시점 기준으로 구간을 나눠서 사용함 (현 시점과 먼 자세는 사실 현 옷 상태를 결정하지 않으므로 잘라내도 됨) |
 |
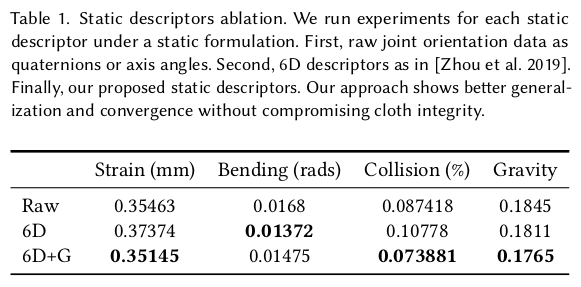
사람 자세를 표현하는 theta_t를 입력으로 넣을 때 그냥 넣지 않고 전처리를 조금 해줌. 1) relative rotation을 표시하는 theta_t를 6D rotation representation으로 바꿔서 사용함 (periodic, continuous 성질을 갖도록 해서 네트워크가 다루기 쉬움) 2) relative rotation이다 보니, global 정보를 놓침. 게다가 local gradient가 조금씩만 누적되도 global gradient가 엄청 커질 수 있으므로 안정성도 구림 -> 따라서 global descriptor 추가. 다름 아닌 중력 방향. 현 joint global coordinate 상의 중력 방향. 총 static encoder에서 나온 값을 위와 같이 처리하면 9차원 static descriptor 완성 |
  |
dynamic descriptor는 일단 static descriptor와 같은 방식으로 9차원 만들고. global descriptor(중력 방향으로 추가했던 3차원)의 2차 미분, 가속도를 추가해서 총 12차원으로 구성함. |
  |
1) static encoder 입력 : 1static pose 출력 : 9차원 joint 개수만큼 z_t (옷 latent) 2) dynamic encoder 입력 : N sequence * pose 출력 : 12차원 joint 개수 * N 개수 만큼 z_t (옷 latent) ----------------- 특징 dynamic encoder는 weight, bias 중 bias가 없다. 따라서 곱셈으로만 이루어진 encoder라서 zero 입력이 들어가면 zero 출력이 나온다. -> static pose (0값) 이 들어가면 dynamic latent는 무조건 0 나오도록 보장됨 -> static latent를 더해도 영향이 없음. -> dynamic latent가 static latent의 나머지만 맞추도록 유도됨. |
  |
1) cloth model loss mass-spring model 이라는 개념이 있다는데 모르겠음. 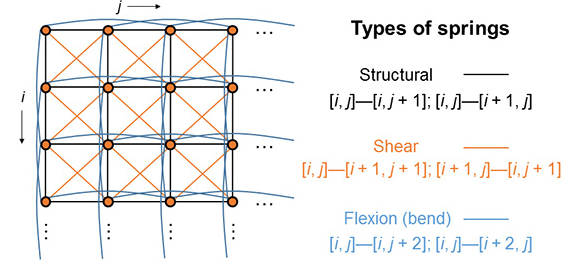 옷을 구성하는 vertex마다 mass가 존재하고 edge에는 탄성이 있는 spring으로 연결되어있다고 가정하는 것 -> mass + 탄성에 의해 서로 간의 변형이 물리적으로 유지되도록 강제하는 무언가 인듯. 2) bending loss 이웃한 face 간의 angle(normal)이 비슷하도록 하는 loss. |
  |
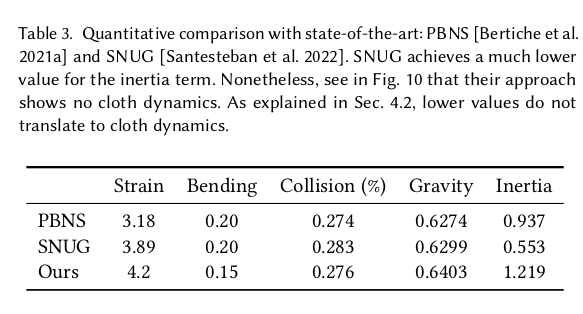
3) collision loss 옷 point의 sdf를 계산해보았을 때, 양수 (외부) 가 나오도록 강제함 4) inertia loss 옷 vertex의 현 위치는 이전 시점 옷 vertex + 속도로 계산한 값이 같도록 강제함. 주의점은 이전 시점 옷 vertex + 속도로 계산할 때 gradient를 끊어줘야 한다는 것. 미래 옷 상태가 과거 옷 상태에 영향을 주는건 말이 안됨. 5) gravity loss 옷 vertex가 매 시점 별로 변형이 없다고 해도 외력이 1개 존재한다. 바로 중력. 사람 자세에 의해 변형이 없다 해도 중력에 의해 항상 땅으로 끌려가도록 유도하기 위해서 추가 함. (이게 되게 매력적인 loss인 듯) |
 |
 |
 |
 |
 |
|
 |
 |
 |
|
 |
|
 |
 |
반응형