반응형
내 맘대로 Introduction

160대로 구성된 돔 형태의 카메라 시스템에서 8명의 배우가 100초 정도의 모션을 찍은 데이터를 공개한다. 데이터셋 공개가 주목적이고 뒤에 따라 붙는 temporal NeRF는 human이라는 특성을 딱히 쓰진 않고 Instant-NGP + time dimension으로 구현함. 데이터가 있으니 이를 활용한 복원 알고리즘 구현까지 해본 것 같다.
참고해야 할 점은 TensorRF + InstantNGP를 구현해낸 코드. 그리고 실험을 되게 한 눈에 파악하기 쉽도록 잘 했는데 정리 방식을 기억할 만 하다.
메모
 |
|
  |
전체 파이프라인은 간단하다. 1) feature volume 표현법을 InstantNGP와 같이 hash grid로 표현을 하되, TensorRF의 vector-matrix decomposition 방식을 차용해서 t-xyz, x-yzt, y-xzy, z- xyt와 같이 4가지 조합 hash grid를 동시에 학습하는 것이다. 2) 뒤에 따라 붙는 것은 NeRF MLP ------------ 대상이 Human이라는 특성을 살린 부분은 없다. |
 |
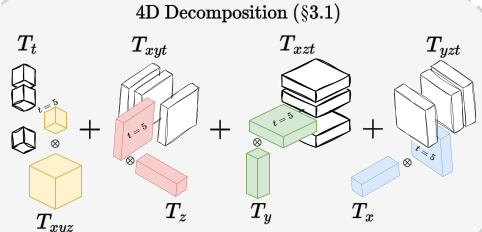 이 그림이 너무 4D feature grid 설명을 잘하고 있음. x,y,z,t가 주어지면 각 4가지 조합에서 이에 맞는 feature들을 다 뽑아서 와서 더하는 방식. |
 |
|
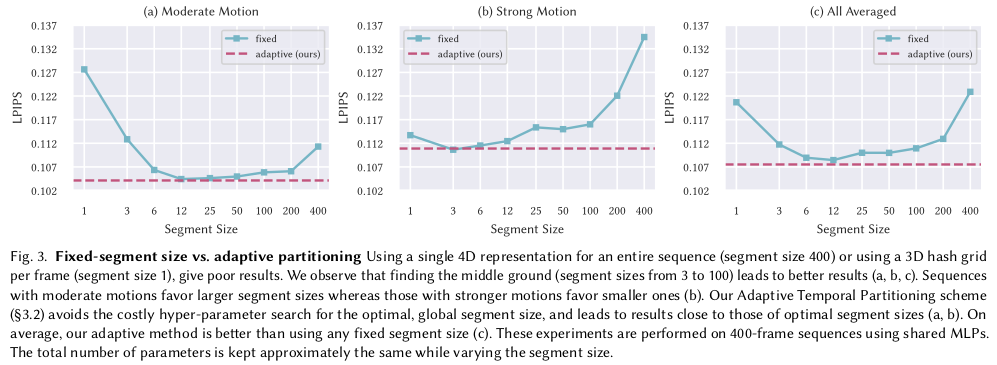
  이 부분이 실험 되게 잘했다고 생각한 부분. 위 x,y,z,t domain 중에 x, y, z는 범위가 한정되어 있지만 t는 한정되어 있지 않다. 더군다나 메모리 때문에 특정 크기의 t 이상은 동시에 학습할 수 없으므로 t dimension의 최대 크기를 지정해야 한다. 그 크기에 따라, 네트워크가 한 번에 저장해야 되는 정보량이 달라지므로 성능 trade-off가 있을 것. 그걸 분석하고 어떻게 해결했는지 적는다. 분석 결과 1) 모션이 클수록 segment가 작아야 함. 한 네트워크가 하나하나 표현에 집중하도록 해야 함. 2) 모션이 작으면 segment가 더 커야 함. 오히려 작으면 성능 하락. |
 모션이 크고 작음을 일단 분간하기 위해서 score 개념을 정립함. 1) 사전에 mask 갖고 복원에 사용되는 모든 voxel을 셈. (visual hull로) 2) 사용되는 모든 voxel 대비 현 시점 복원에 사용되는 voxel 비중을 계산함 (전체/현재) 3) 이 값은 대략, 현재 자세가 얼마나 다이나믹한지 표현하는 지표가 됨. (변화가 크다면 값이 커지고, 변화가 작다면 값이 작아짐) |
  |
매 프레임 score가 정해지면 segment 크기를 정할 때 첫번째 프레임부터 score를 누적해가다 특정 threshold (1.25)가 넘으면 분할. 또 넘으면 분할 하는 식으로 나눔. -------------- 이러면 모션이 작을 때는 segment 크기가 커지고 모션이 클 때는 반대로 segment 크기가 작아짐. 이는 위 그림에서 분석한 내용과 일치함. |
 이 부분은 그냥 NeRF 설명이랑 중복이라 생략. |
 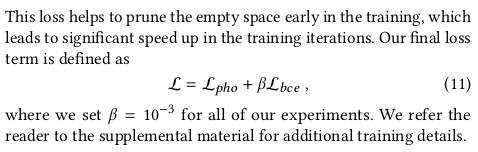 |
 |
 배우 남4 여 4 카메라 12 메가 픽셀 160대 25fps RealityCapture로 복원한 결과도 있음. 32 actions |
 |
|
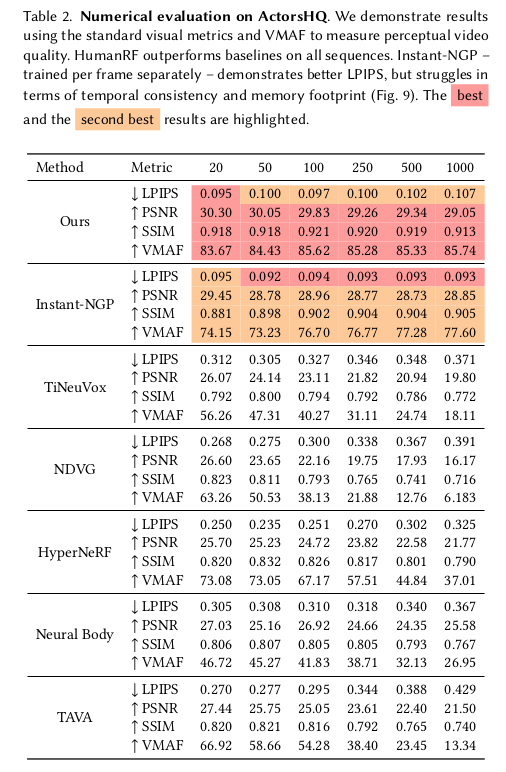 |
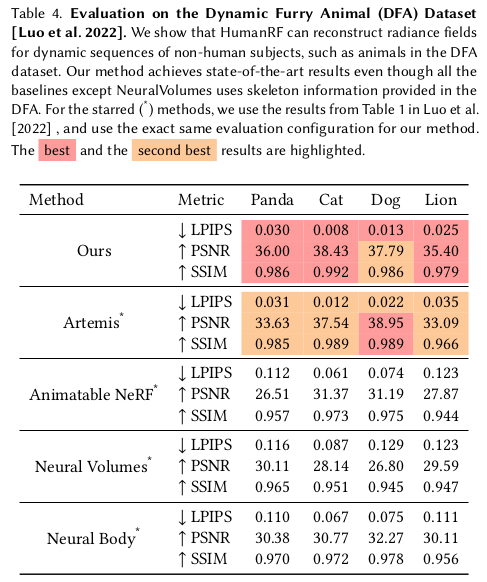
 이건 카메라 세팅의 힘이 가장 큰 것 같음. |
 |
 |
 |
 |
 |
 |
반응형
'Paper > Human' 카테고리의 다른 글
| gDNA: Towards Generative Detailed Neural Avatars (0) | 2024.05.30 |
|---|---|
| Neural Cloth Simulation (0) | 2024.05.28 |
| 3D Face Reconstruction with the Geometric Guidance of Facial Part Segmentation (3DDFA v3) (0) | 2024.05.17 |
| Towards Metrical Reconstruction of Human Faces (a.k.a MICA) (0) | 2024.05.10 |
| Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction (0) | 2024.05.08 |