반응형
내 맘대로 Introduction
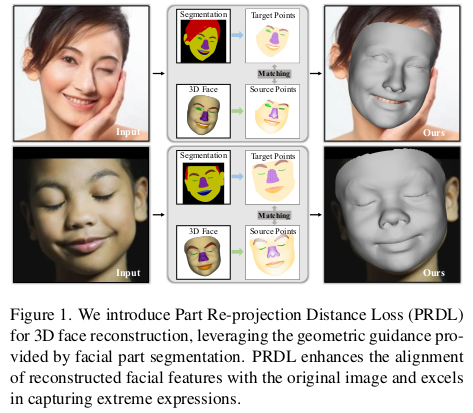
3DMM (여기선 FLAME 안쓰고 BFM, FaceVerse 씀, 아마 서양인 데이터 bias 때문이지 않을까.) 을 이미지에 fitting하는 논문. HMR의 face version인데, 3DDFA version3인 셈이다.
핵심 아이디어는 기존 논문들이 keypoint에 집중하던 걸 확장해서 segmentation mask를 이용한 fitting이다. segmentation mask를 사용하는 아이디어 자체는 흔하지만 기존 방식과 다르게 단순히 렌더링 결과만 놓고 pixel by pixel로 비교하는 것이 아니라, 새로운 loss를 제안해서 풀었다.
(2d segmentation -> 3d lifting ) <-> (segmented 3d model)
mesh geometry가 segmentation mask에 더 직접적으로 반응하도록 설계된 loss 덕에 detail까지 표현할 수 있는 모델 파라미터가 잘 찾아진다.
개인적으로 흔하디 흔한 문제를 다뤘고 흔하디 흔한 source를 갖고 풀었는데, 새롭지 않다고 포기하지 않고 새롭게 생각해서 접근했다는 점이 좋다. 자기만의 연구 느낌이 나서 좋은 듯.
메모
  |
모델은 FLAME 안 씀. BFM과 FaceVerse 사용. (서양인 데이터 bias 때문으로 생각함.) 카메라는 fixed perspectivep projection. 카메라 포즈랑 intrinsic을 대충 고정함. texture도 찾아내는데, texture는 albedo(diffuse) + SH(specular) |
 |
|
 |
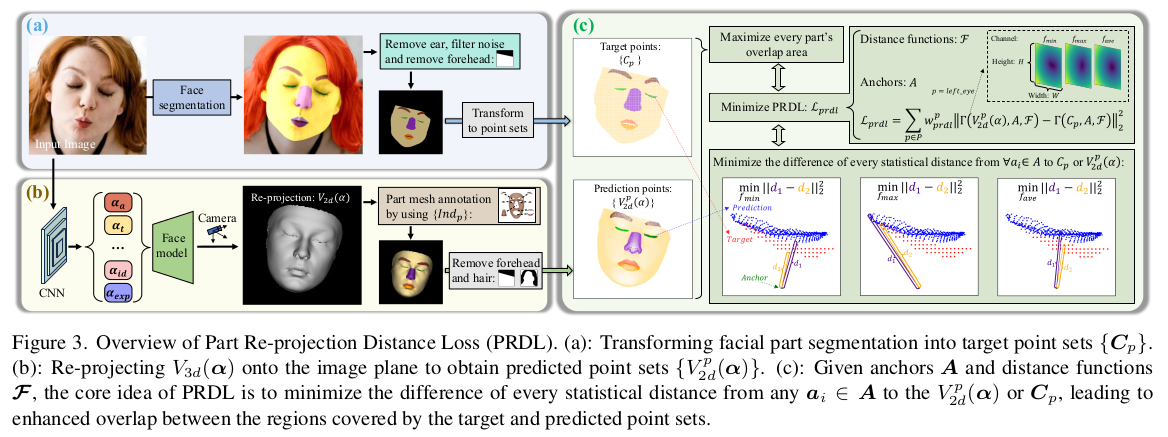
시작은 이미지 part segmentation, 1) 양쪽 눈썹 각각 2) 양쪽 눈 각각 (표정 표현에 가장 중요하다고 생각해서 그런 듯) 3) 코 4) 입술 5) 얼굴 피부 (여집합) 알고리즘은 DML-CSR 이마는 의도적으로 눈썹 위로 잘라냄 ( 이마가 앞머리에 의해 가려지는 일도 많으니 오히려 방해됨을 걱정해서 잘라낸 듯.) |
 |
이젠 BFM, FaceVerse의 vertex segmentation 카테고리는 위 5개 종류와 동일하게. 직접할 수도 있지만, 데이터셋이 있으니 2d seg.를 보고 반복적으로 일치하는 vertex를 같이 3d seg.함. 후에 약간 손질. 역시나 이마 위는 배제됨. 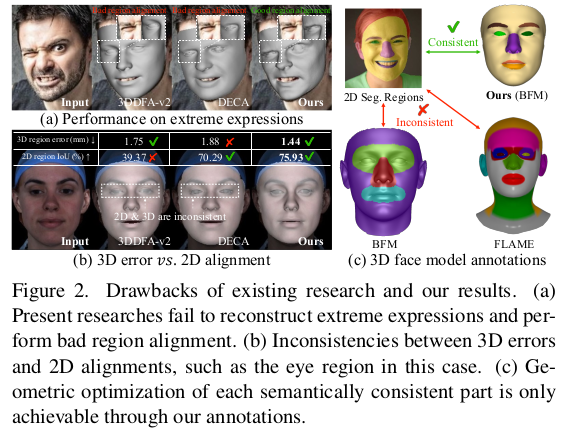 직접한 이유는 기존 segmentation 영역이 너무 대충이기 때문. |
   |
핵심은 여기. 2d seg <->projected 3d seg를 비교하는 loss 단순히 IoU를 계산하는 방식은 효과가 떨어진다고 함. 그래서 직접 Vertex-to-pixel loss를 계산하는 방식으로 변경. 이 때 vertex수와 pixel 수가 다르고 correspondence를 계산할 수 없다. 따라서 anchor를 활용하는 방식으로 변경 ------------------------------- 1) pixel 마다 anchor 생성 (3d point 형태) - 아마 특정 거리에 3d plane 형성하는 형태 2) 영역 별로 각 anchor point와 back-projected 2D seg. point anchor point와 3d seg. vertex 거리를 계산함 d1, d2 그 중 min, max, avg 3개 거리 값을 줄이도록 강제 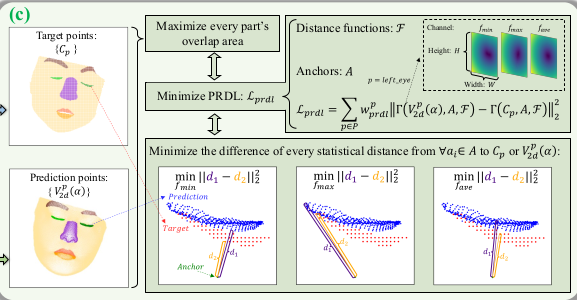 여기서 back-projected 2d seg.는 현재 추정된 3DMM 파라미터로 vertex들을 만들고 그대로 입힌 것. |
 |
위 PRDL loss와 더불어 landmark, photometric loss, perceptual loss로 학습함. regularization은 파라미터가 0에 가깝도록 유지. |
 |
 좀 뜬금없지만, segmentation가 같이 제공되는 데이터셋도 같이 만들었다고 함. 학습할 때 쓴듯? |
  |
이 PRDL이라는 방식이 효과가 좋은 이유는 단순히 그냥 그렇게 한 것이 아니라 실제로 gradient 계산을 해보면 유의미하게 vertex 단위로 정확한 방향으로 이동시키기 때문임. 수식(11)이 핵심인데, anchor 대비 현 추정 결과 vertex 위치가 이동해야할 방향을 정확히 표현하고 있음.  min, max가 boundary vertex들을 움직여주고, avg가 centroid를 움직여주는 모양이며 주변에 anchor가 엄청 많기 때문에 boundary 전체, centroid 반복 강제하는 모양이 된다. 더 특별한 점은 segmentation mask 영역 밖의 anchor도 기여를 크게 한다는 점. (기존 방식에서는 해당하는 영역만 개입함) |
  |
이 방식의 장점을 한 번 더 강조해주는데, 이렇게 명시적 거리 기반 loss로 하면 mask 외 영역 pixel들도 loss 계산에 관여하기 때문에 수렴 속도와 퀄리티가 훨씬 좋아짐. |
 |
|
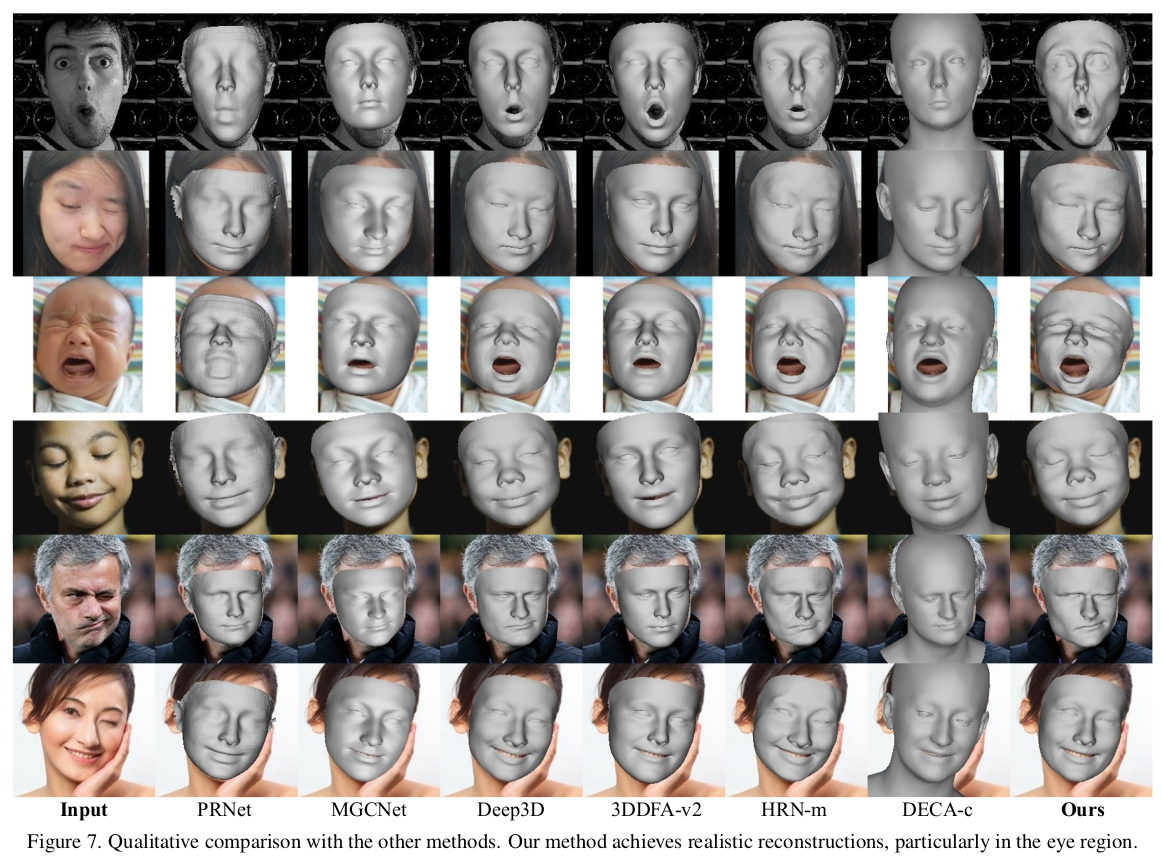 결과가 기존 논문들은 잘되는게 맞나 긴가민가 싶은데 확연하게 잘되는게 보인다. |
 |
 |
 |
 |
 |
  극단적인 표정은 당연히;; |
반응형
'Paper > Human' 카테고리의 다른 글
| Neural Cloth Simulation (0) | 2024.05.28 |
|---|---|
| HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion (a.k.a Dataset ActorHQ) (0) | 2024.05.28 |
| Towards Metrical Reconstruction of Human Faces (a.k.a MICA) (0) | 2024.05.10 |
| Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction (0) | 2024.05.08 |
| POCO: 3D Pose and Shape Estimation with Confidence (0) | 2024.05.07 |