반응형
내 맘대로 Introduction

기본 아이디어가 학습 잘 된 backbone에서 나오는 feature들을 고해상도로 변환할 수 없을까? 라는 질문에서 시작된다. DinoV2 같은 foundation backbone을 가져와서 사용하는 것이 흔한 요즘, 224x224로 제한된 해상도는 활용에 걸림돌이 되곤 한다. 이러한 답답함을 완화하기 위해서 뒤에 갖다 붙일 수 있는 feature upsampler를 만들고자 했다.
upsample -> down sample <-> 원본 feature 방식으로 cyclic하게 학습해서 나중엔 upsampler만 가져와서 쓰는 방식
두 가지 구현 방식이 존재하는데
1) 학습 1번 완료 후 계속 고정하고 사용하는 upsampler
2) 이미지 1장마다 overfitting시켜서 성능을 끌어올리는 per image upsampler
2)는 솔직히 조금 실망했다. 예시 사진들이 전부 2)의 결과물. 이미지 1장마다 학습 새로 해야하면 활용을 할 순 있을까. 데이터셋 1장 1장마다 새로 학습하고 feature upsample한 거 저장하는건 현실적으로 불가능한 일이라서 2) 방식은 현실성없는 접근 방법 같다. 그림에 어그로가 조금 있는 것 같다.
|
|
|
아이디어 자체는 직관적이고 간단함 1) low-res. feature를 바로 upsampling하고 다시 down sample 2) low to high to low <-> low 간의 loss 계산 3) 이 과정에서 pad, crop 같은 jitter 추가. ---------- NeRF 컨셉을 자꾸 사용했다고 하는데 잘 모르겠다. 그냥 augmentation인데 말을 그렇게 꾸며 쓴 듯함. 핵심은 upsampler, downsampler를 어떻게 디자인 했는가. |
|
|
|
downsample 1) 가장 간단하게는 gaussian blur 같이 kernel을 이용한 blur인데 kernel 파라미터를 학습으로 찾아내는 방식 2) learnable kernel로 kernel 함수 자체를 학습에 맡기는 방식. 후자가 더 성능이좋고, - 1x1 conv 이후 - NxN patch weight + bias 학습 해상도가 몇인지는 모르겠으나 중요하진 않은 듯. |
 |
|
  |
upsample 1) 이미지 1장마다 overfitting 시켜서, DinoV2 high res. feature 만들도록 하는 implicit upsampler 2) joint bilater upsampler 여러개로 조합된 범용 upsampler 2개가 있음 |
  |
2) upsampler의 핵심 joint bilateral upsampler 직관적으로 말하면 저해상도 feature + 고해상도 image를 입력으로 동시에 넣고 u, v indexing을 맞춰서 같이 kernel 통과시키는 형식임 저해상도 feature에 고해상도 이미지 정보를 껴넣어주는 것. kernel 내 거리 * 고해상도 이미지 정보 * 저해상도 feature 정보 -------------------- 이게 구현하면 속도가 느리다고 함. 그도 그럴 것이... 이미지 값을 계속 읽어야 하니까 느릴 듯. CUDA로 자체 구현함 <-이부분이 contribution이라고 볼 수 있을 것 같음. |
 |
1) upsampler 나는 내가 잘 못 이해한 부분이 있나, 그림이 잘못되거나 notation이 잘못된건가 2번 확인했다. 이 upsampler는 DinoV2같은 backbone하고 전혀 무관하다. 이미지 1장에 대해서만 DinoV2 high feature를 만들도록 feature extractor를 따로 학습하는 방식 이미지 1장마다 학습 다시 해야한다. --------------- 학습할 때 pixel by pixel implicit function 형태로 구현해서 positional encoding (fourier transform으로 표현된 것)을 바꿔주면 임의의 해상도로 upsample 가능함 |
 |
fourier transform으로 positional 표시할 때 128dimension에서 컷. feature level 에서 TV loss로 regularization |
 이거 image by image 성능임. 솔직히 어그로 성 사진... |
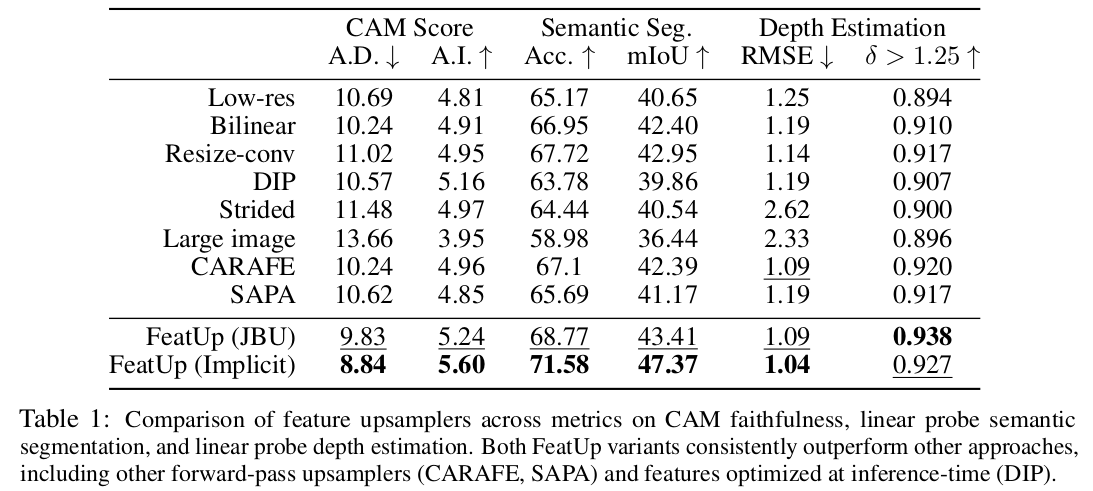 걸린 시간이 더 궁금. |
 |
 |
반응형
'Paper > Others' 카테고리의 다른 글
| SHIC: Shape-Image Correspondences with no Keypoint Supervision (0) | 2024.07.30 |
|---|---|
| As-Rigid-As-Possible Surface Modeling (0) | 2024.07.16 |
| MultiMAE: Multi-modal Multi-task Masked Auto encoders (0) | 2024.04.16 |
| Learning Transferable Visual Models From Natural Language Supervision (a.k.a CLIP) (0) | 2024.02.06 |
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2024.01.05 |