반응형
내 맘대로 Introduction

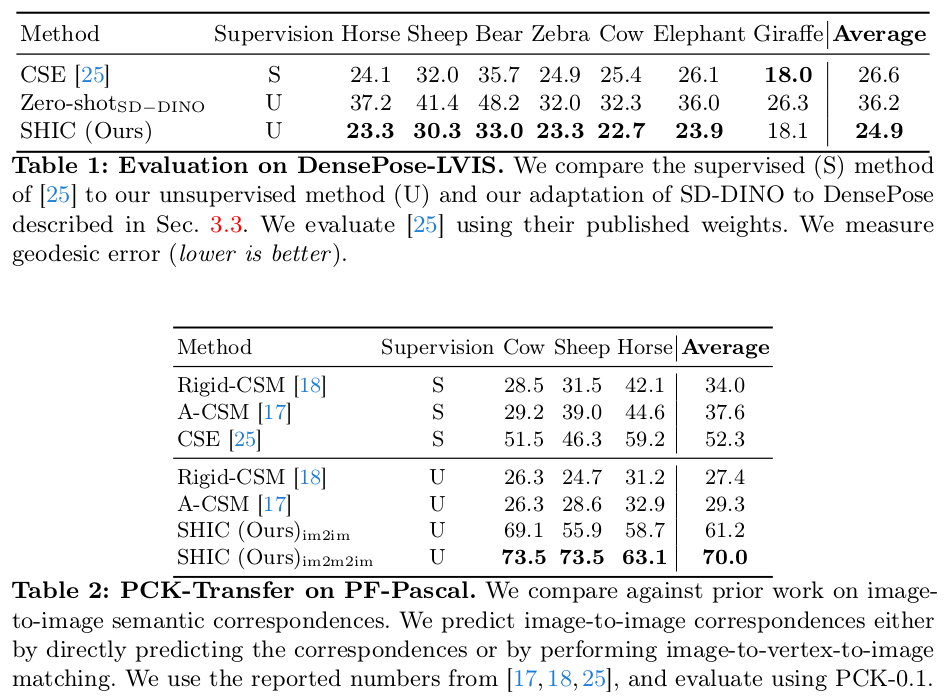
이 논문은 3D template mesh <-> image object 간의 correspondence를 찾는 논문이다. 3D-2D correspondence를 찾는 문제인데 이때 3D가 template mesh로 semantic하게만 2D와 맞아떨어지는 3D다. 예를 들어 고양이 template mesh와 모든 고양이 이미지 간의 correspondence를 찾는 논문이다.
연구적인 레벨이라서 실용성과는 아직 거리가 있는 논문이긴 한데 활용을 생각해보면, 서로 다른 고양이 이미지 간의 semantic correspondence를 찾을 때 3D template mesh를 매개로 사용하여 찾을 수 있다는 정도가 있다.
핵심 아이디어는 GT를 만들기 힘들기 때문에 이를 SD-DINO를 이용해 unsupervised로 문제를 풀었다는 것.
개인적으로 요즘 들어 face도 body도 template mesh를 query로 이용해서 이미지에서 무언갈 찾아내거나 추정하는 아이디어가 많이 등장하는 것 같다. 이것도 나름의 추세랄까.
메모
  |
핵심 네트워크는 이미지 pixel-> template mesh vertex 를 추정한다. vertex to pixel이 아니라, pixel to vertex임 (visibility check가 이미지에서만 가능하기 때문에 이런 방향으로 한듯 |
 |
|
 |
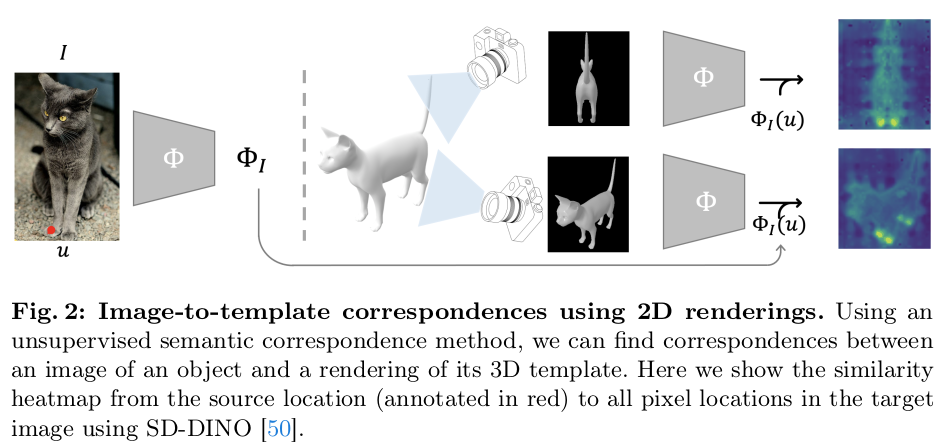
이 논문의 발단을 생각해보면 위 그림과 같다. SD-DINO feature를 보니, 그냥 rendered mesh 이미지에서도 semantic info.를 잘 뽑더라. 이걸 발견해서 아마 이런 연구를 고민한 것 같다. 상당히 다른 입력 도메인임에도 SD-DINO가 같은 semantic을 뽑아주는 것을 보고 이미지와 template mesh 간의 correspondence 해결 실마리가 생겼다고 생각한 것 같다. ------------------------------------------------------- 이미지 feature와 rendered 이미지 feature 간의 cosine similarity를 찾는 것만으로도 대략의 correspondence를 찾을 수 있었다. --------------------------- 하지만 중복 문제(왼쪽 오른쪽 같은)나 visiblity 문제가 남아있기 때문에 SD-DINO를 그대로 쓰는 것 대신 약간의 변형이 필요했다. |
 |
|
 |
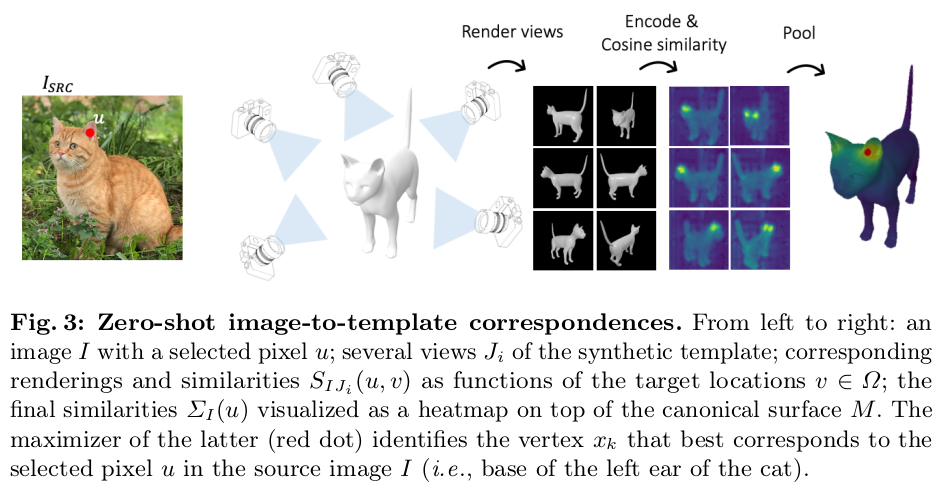
일단 첫번째 변형은, 시점을 늘리는 것이다. 반복이나 visibility는 시점이 늘어나면 구분이 쉬워진다. 몇개가 잘못 매칭되어도 다른 시점과 비교하면 걸러낼 수 있으니까 따라서 사아 시점을 K개 만들어내고, K 시점과의 cosine similarity를 전부 다 계산, pooling해서 최종 스코어를 매겨 correspondence를 계산하는 식으로 구성했다. |
 |
참고로 rendering된 mesh 이미지 대신 rendered normal을 써도 효과가 좋다. ----------------------- 그냥 template mesh가 sphere여도 될텐데 굳이 해당 카테고리 형상의 template mesh를 쓴 이유는?? 결국엔 이미지 feature이기 때문에 대략의 형상정보가 도움이 되기도 하고 나중에 사람이 작업할 때 도움이 되기 위해선 대략의 형상이 있긴 해야된다고 함. |
 |
|
 |
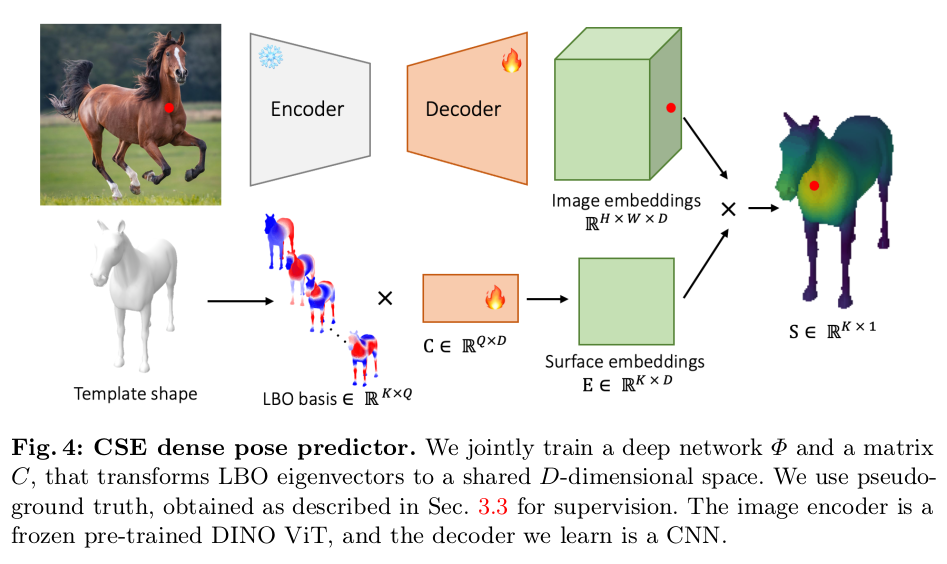
이미지 feature는 SD-DINO 그대로 써도 좋지만 (도메인이 같으니까) rendered는 SD-DINO가 기능은 한다만 그래도 아쉽긴 함. 그래서 얘만 Learnable vertex feature로 대체. 네트워크 떼고 아예 vertex feature 부여. ------------------ vertex 개수가 워낙 많으므로 메모리가 터질 수 있으므로, KxD feature를 decomposion해서 KxQ basis QxD coefficient로 분리해서 학습했다. Q가 K보다 훨씬 작기 때문에 메모리 효율이 좋아짐. 앞의 KxQ basis는 learnable 아니고, manifold harnomic 계산할 때 쓰는 basis임. laplace bletrami operator로 만듦. |
 |
loss는 크게 4개 1) pseudo GT가 있을 때 (synthetic 데이터 쓸 때) cosine similarity가 pixel-vertex GT match일 때 높도록 2) 1) 앞에 distance 곱해서, 멀면 확 떨어지게, 주변과 분별력있게 3) pixel-vertex-pixel 다시 찾았을 때 제자리로 오는지, feature vector 간 cosine sim. 이므로 vertex | pixel이나 pixel|vertex가 똑같음. 4) 좌우 반전 시켜도 결과가 같은지. |
 |
|
  |
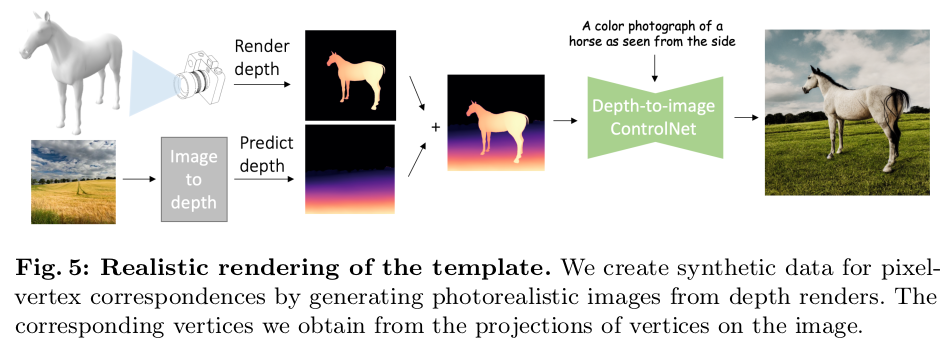
unsupervised라면서 pseudo GT는 어떻게 만들었는가? template mesh rendered depth로부터 diffusion model로 이미지 찍어내서 만듦. --------------- diffusion은 이제 GT 생성용으로까지 쓰이는 수준이구나.... |
 |
 |
 |
|
 |
반응형
'Paper > Others' 카테고리의 다른 글
| Improving 2D Feature Representations by 3D-Aware Fine-Tuning (0) | 2024.09.11 |
|---|---|
| XCiT: Cross-Covariance Image Transformers (0) | 2024.08.06 |
| As-Rigid-As-Possible Surface Modeling (0) | 2024.07.16 |
| FeatUp: A Model-Agnostic Framework for Features at Any Resolution (0) | 2024.05.13 |
| MultiMAE: Multi-modal Multi-task Masked Auto encoders (0) | 2024.04.16 |