반응형
내 맘대로 Introduction
language model 이해하려고 보기 시작한 논문 중 두번째. 이 역시 나온지 오래 돼서 지금 보면 뭐 간단해보이기만 하는 논문 같다만, 기존 GPT1 방식처럼 문장을 왼쪽에서 오른쪽으로 다루는 방식에서 양방향으로 다루는 방식이 더 효과적이라는 것을 보이고 fine tuning 시에 네트워크를 추가하거나 구조를 변경하지 않아도 그대로 적용할 수 있도록 간단히 했다.
더불어서 학습 방법론에서도 단순히 다음 단어를 예측하도록 하는 것이 아니라, masked language modeling 일명 가려진 단어 맞추기로 변경했다. masked image modeling을 먼저 알고 보니 여기서 시작됐구나 싶었다.
메모하며 읽기
 |
|
  |
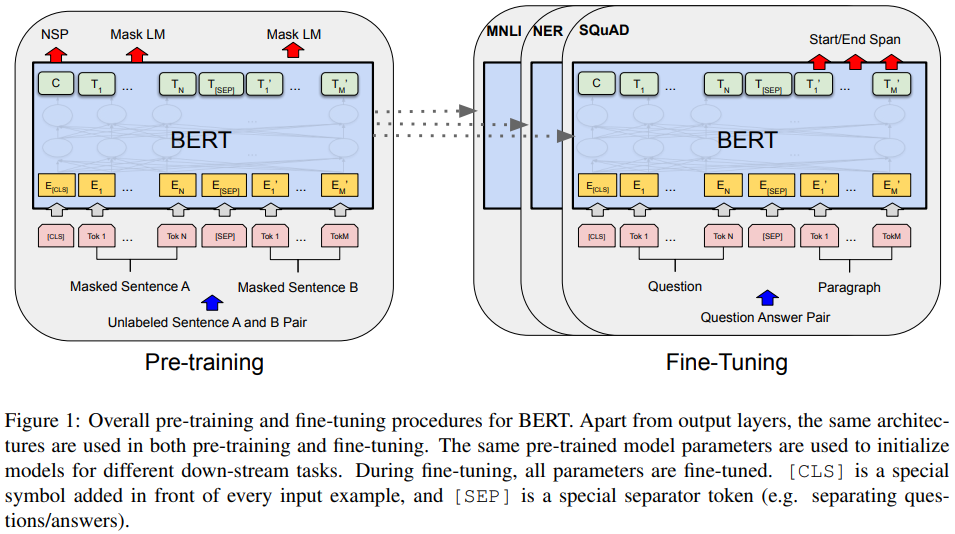
pre-training 때부터 두 문장 단위로 들어가도록 했다. 한 문장 안의 정보만 배우는 것이 아니라 연관된 문장끼리의 관계도 같이 배우도록 사전학습하니 효과가 더 좋을 것이라고 기대할 수 있겠다. task specific fine tuning 시에 GPT는 두 문장 단위로 tuning하므로 구조 변경이 필요했었는데 이 BERT는 애초에 두 문장 단위로 들어가니 변경이 필요없다는 점도 강점이다. 다른 말로, 단 한개의 layer라도 처음부터 학습되는 layer가 없다. |
 |
|
 |
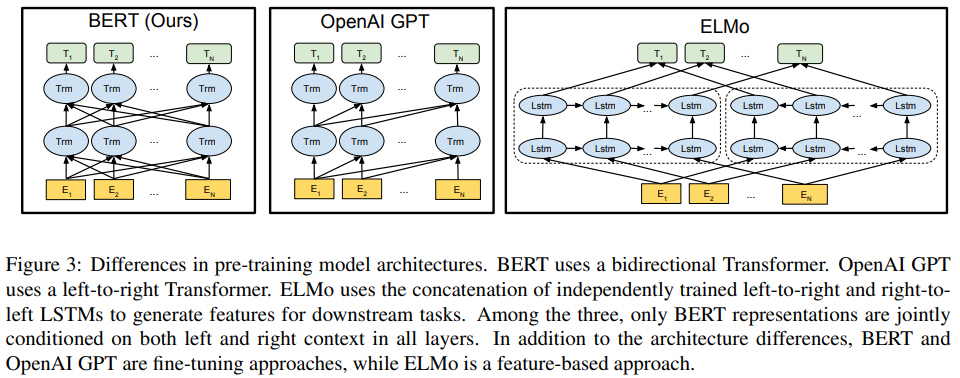
모델 구조는 ViT 사실 그대로 쓴 것에 가까워서 생략을 과감히 생략하고 디테일만 적었다. 뒤 그림을 보면 GPT1.0은 left-to-right 일방향성을 갖고 있기 때문에 token들이 섞이지 않도록 약간의 구조 변경이 필요했는데 BERT는 양방향을 다 다루기 때문에 기존 ViT를 그대로 쓰면 그 목적에 부합했다. |
 |
|
 |
입력이 애초에 두 문장 단위로 묶여서 들어가도록 변경한 점도 크게 보면 GPT1.0 fine tuning 시와 동일하다. GPT1.0에서는 문장의 시작, 분리, 끝을 표시하는 특수 token을 넣었는데 BERT는 문장의 성격(입력으로 들어온 문장의 다음 문장인지 아예 다른 문장인지), 분리를 표시하는 token을 넣었다는 점이 차이점이다. 문장은 이전과 동일하게 token embedding된 후 문장 단위로 segment embedding, position embedding이 들어간다. |
  |
사전학습의 핵심 아이디어는 크게 2가지인데, 첫번째는 MLM이다. 두 문장 단위로 연결되어 준비된 token들 중 일부 (15%)를 일부러 가리고 네트워크가 이 가려진 단어를 맞추는 식으로 학습했다. 이렇게 하면 주어진 두 문장 자체의 내용 + 관계를 이용하여 가려진 단어를 추론하는 방식을 학습해서 효과가 좋을 것이란 기대다. 하나의 문제는 학습 시 masked token만 맞추도록 구조를 잡으면 실제 사용할 때 masked token이 있을리 만무하므로 동작하지 않는다. 따라서 masking을 하는 것은 동일하지만 네트워크가 masked 되어있는지 아닌지 구분 못하도록 했다. 다른 말로, 학습은 의도한대로 하지만 네트워크가 masked token인지는 모르게 해서 모든 단어를 다 추론할 수 있도록 만드는 것이다. 그 방법은 실제로 MASKED token을 15% 전체에 부여하는 것이 아니라 15% 중 일부만 True MAKSED, 일부는 Fake MAKSED를 넣어주는 식이다. 이러면 네트워크가 MASKED token만 잘 맞추려고 학습되지 않는다. 그 중에 틀린 것도 있으니 진짜 추론하는 능력을 기르게 된다. |
  |
사전학습의 두번째 핵심은 NSP token이다. languague task 중에 성격이 다른 것들이 많은데 모두 공통된 pre-trained backbone을 쓰기 위한 trick이다. 일례로 입력으로 들어온 문장을 분석/요약하는 것과 입력으로 들어온 문장에 대한 답변을 하는 것은 다르다. 후자의 경우, 전혀 다른 문장이 나와야 하므로 이 둘을 분리하는 기능 필요했다. 그래서 기존 start token이 들어가던 위치에 NSP token을 넣어 출력으로 나온 문장이 입력의 다음 문장인지 아닌지 구분토록 했다. 학습 시 비중은 NSP 1 50% 0 50%다. |
 |
사전학습 데이터 리스트 |
  |
사전학습 방법이 주고 fine tuning을 부이므로 설명이 크게 필요없다. 게다가 입력을 애초에 두 문장 단위로 받으니 크게 달라질 것도 없어서 내용이 간단하다. 약간의 특수 token 차이가 있다는 점을 설명함. |
 |
|
 |
 |
 |
 |
 |
 |
반응형