반응형
내 맘대로 Introduction
 |
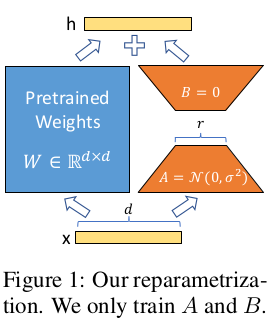 |
LoRA도 워낙 유명한 논문이라 읽지 않았더라도 내용은 알고 있었다. 위 그림 한 장으로 모든 것을 설명할 수 있는 간단한 알고리즘인데, 초거대 모델을 downstream task 별로 fine tuning하는 공수가 만들다 보니 이를 간소화하기 위해 제안된 adapter다. downstream task 별로 fine tuned 모델을 따로 두는 것이 아니라 original model + tuned adapter를 여러 개 보유 하는식으로 분리해서 저장 용량도 줄이고 연산 병렬화에도 유리하도록 했다.
original model 한 번 forward할 때 가벼운 adapter만 여러개 forward 같이 하고 연결만 해주면 많은 downstream task 처리가 가능해지는 시나리오다. 더불어 original model weight는 건드리지 않는 형태이므로 학습 시간도 단축될 것이다.
adapter의 핵심 아이디어는 origianl model weigth matrix에 residual weight를 계산하는 방식이지만 sequential하게 붙이는 것이 아니라 parallel하게 붙이는 것이다. 추가적으로 residual matrix를 low rank decomposition해서 훨씬 적은 파라미터로 계산할 수 있도록 설계해서 연산량 조절에 더 유리하도록 했다.
메모하며 읽기
  |
| 문제 정의부터 확실하게 시작하는데, 기존 논문들을 fine tuning을 한다고 하면 original model의 weight를 초기값으로 시작해서 통째로 새로운 weight로 만드는 방식을 사용했다. 이러면 매번 전체를 업데이트해야 하고, downstream task마다 거대한 모델이 새로 존재해야 한다는 문제가 생긴다. 이는 이론적으로는 문제 없지만 보관하고 서비스해야 하는 기업 입장에서는 비용 문제로 이어지는 상황이다. original model은 고정해두고, residual weight만 업데이트하는 방식으로 접근하면 거대한 부분인 original model은 단 1번 존재하고, residual model만 여러개 존재하면 되므로 문제가 해결된다. LoRA도 이런 문제 해결 방식에서 시작한 알고리즘이다. |
 |
| 기존에는 이런 문제를 풀고자 하는 접근법이 없었냐? 그건 아니다. residual weight만 두면 유리하다는 아이디어는 역시 존재했는데 original model 내부에 adapter layer를 끼워넣는 방식이 있었다. 추가적으로 입력 prefix에 손을 대는 방식도 있다. 각각 내용은 다음과 같다. |
 |
| 첫번째로 모델 중간 중간 adater layer를 끼워넣는 방식인데, 이는 컨셉 상 완전히 LoRA와 동일하다. residual weight를 얻는 방식이기 떄문이다. 하지만 구조 상 sequential하게 모델 중간에 끼워넣어져 있기 때문에 서비스할 때 병렬 처리가 불리하다. 병렬 처리가 가능하려면 original model forward 한 번 콜 되었을 때 downstream task 별로 결과를 활용할 수가 있어야 하는데, 이는 직렬적이기 때문에 구간 별로 끊기는 문제가 있다. 다시 말하면 (forward 조금 한 다음 adapter layer 별로 통과 ) 과정을 계속 반복해야 하므로 latency 문제가 있다. |
 |
| 실제로 batch size가 클 때는 batch size에 의한 latency 감소 때문에 조금 가려지는 듯 하나 1일 때를 보면 20%나 latency가 늦어지는 문제가 있다. |
 |
| prefix에 손을 대는 방식은 조금 다른 접근이지만, 입력 길이나 형태를 통제하는 방법인 만큼 downstream task 자유도가 제한받는다는 치명적인 문제가 있다. |
 |
| 그래서 LoRA는 residual weight를 계산하는 컨셉을 유지하되 병렬적 구조를 취한다. 그림 1과 같이 original model block 1개 통과할 때 같은 입력을 받아 병렬적으로 residual weight를 계산한다. 더불어 residual weight도 original model weight dimension 그대로 다루면 용량 문제가 있으니 low rank decomposition을 통해 rank가 낮은 matrix 곱으로 쪼개질 수 있도록 했다. 핵심 가정은 original model weight가 이미 충분히 많은 능력을 보유하고 있을테니 fine tuning 시에는 minor한 업데이트만 필요할 것이라는 내용이다. low rank 즉 intrinsic하게 대략적으로만 업데이트 해줘도 충분히 tuning될 것이라는 이야기다. 그래서 low rank matrix로 분리했다. |
 |
| rank, r을 적게 사용하면 tuning 능력이 줄어들고, original model dimension에 가깝게 쓸 수록 기존 full fine tuning 기능에 가까워지는 모양이 되므로, tuning 정도를 조절할 수 있는 자유도가 생기는 장점까지 있다. |
  |
| latency 문제도 latency를 가장 크게 먹는 original model 부분이 1번만 forward되고 엄청 작은 규모의 LoRA만 병렬적으로 forward되는 형태이므로 거의 문제가 없다. |
 |
| 실제로 transformer에 적용해보아쓸 때 VRAM 사용량이 2/3 이상 줄어들었고 모델 사이즈는 10,000배 이상 감소, 학습 속도는 25% 이상 향상 되었다고 한다. 그나마 단점이라고 하면 한 batch 안에 여러 downstream task 입력이 섞여있는 경우에는 대응할 수 없다는 것인데 이런 경우가 몇이나 있겠나... |
 |
 |
 |
 |
 |
 |
 |
 |
반응형