반응형
내 맘대로 Introduction
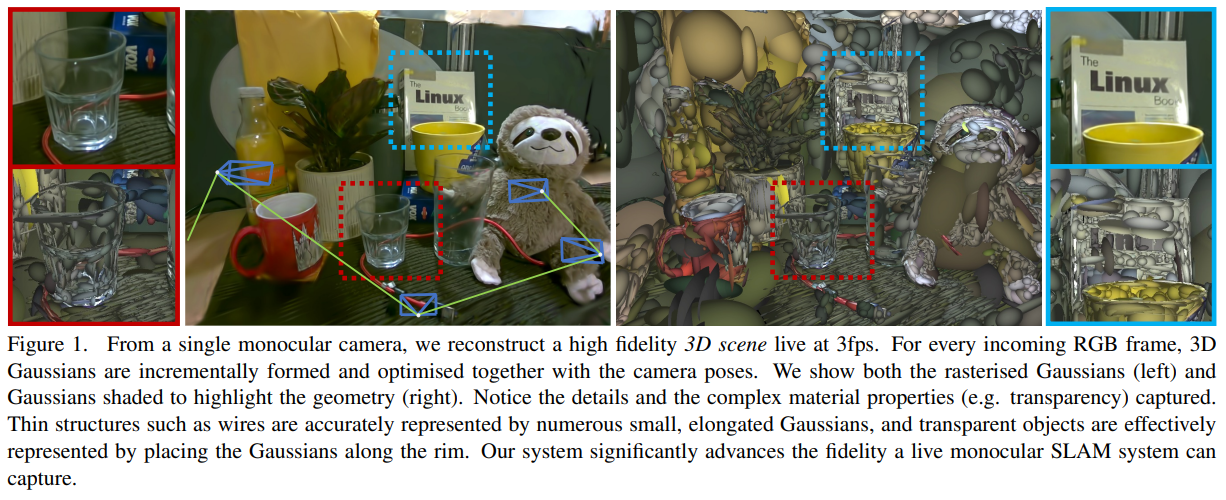
이 논문은 제목이 곧 내용이다. 이전 SplaTAM, GS-SLAM 이랑 같은 내용이다. 3d gaussian으로 view synthesis와 SLAM 두 목적 다 달성하겠다는 논문. 같은 아이디어인데 논문 게재가 되지 않았기 때문에 중복 아이디어 논문이 많다. 발 빠르게 낸 논문인데 이미 같은 아이디어 논문이 2개나 있다.
핵심 내용도 똑같이 카메라 포즈와 3d gaussian과 같이 학습시키는 방법이다. 카메라 포즈에 대한 jacobian을 직접 수식 계산했다는 점엔서는 GS-SLAM이랑 비슷하지만 큰 틀에서는 그냥 3d gaussian splatting을 SLAM에 갖다 붙이기 때문에 큰 차이 없다.
다른 논문들은 RGBD 입력을 활용하고 이 논문은 RGB만 사용한다는 차이점이 있다고 볼 수도 있지만, 결국 이 논문도 depth 입력이 있는 경우도 언급하기 때문에 이론적으로는 99% 동일하다
따라서 리뷰할 내용도 적고 그냥 단순 기록으로만 적어두고자 한다.
메모하며 읽기
 |
3d gs recap은 생략. SH 안쓰고 RGB로 변경 |
 |
|
  |
핵심 부분인 카메라 포즈를 같이 추정할 때 jacobian을 어떻게 계산할 것이냐 이다. 3d gs는 jacobian 계산하는 부분이 속도 문제로 pytorch를 쓰지 않고 CUDA 코딩되어 있기 때문에 이와 같이 최적화 대상이 변할 경우 jacobian을 별도로 계산해주어야 한다. GS-SLAM에서와 같은 방식이는 모르겠으나 (supplementary까지 보진 않아서) 수식(3) (4)가 일단 같기 때문에 어떤 방식으로 하나 효과는 비슷할 것 같다. 수식(6)과 같이 jaocbian을 계산해서 사용했다. |
 |
카메라 포즈를 찾는 부분이다. gaussian의 파라미터들 뿐만 아니라 이전 프레임 대비 SE3가 같이 파라미터로 들어가 있다. depth가 만약 이용 가능할 경우, color loss와 동일하게 alpha blending 으로 만든 rendered depth에 l1 loss를 추가해준다. (너무 반복돼서 이제 읽기도 전에 이렇게 했겠지 싶다) |
  |
SLAM 돌릴 때 설정 내용인데 모든 frame을 한 번에 최적화하느 것은 burden이 심하기 때문에 covisibility가 높은 frame끼리 묶어서 최적화 한다. |
 |
covisibility는 현재 frame,t 까지 복원된 gaussian을 대상으로 frame 마다 보이는 gaussian 안보이는 gaussian을 분류한 뒤, Gaussian IoU를 활용했다고 한다 .(직관적인 듯) |
 |
covisibility 계산할 때 opacity 0.5 이상만 추려서 IoU 계산한 것이 디테일. |
 |
초기화는 1) depth 입력 있을 경우, 해당 위치에 std 작게 생성 2) depth 입력 없을 경우, rendered depth의 median 값 + std 크게 생성 제거는 1) 과거 3프레임에서 생성된 gaussian 중, 이후 3 프레임 동안 사용 안될 경우 pruning |
 |
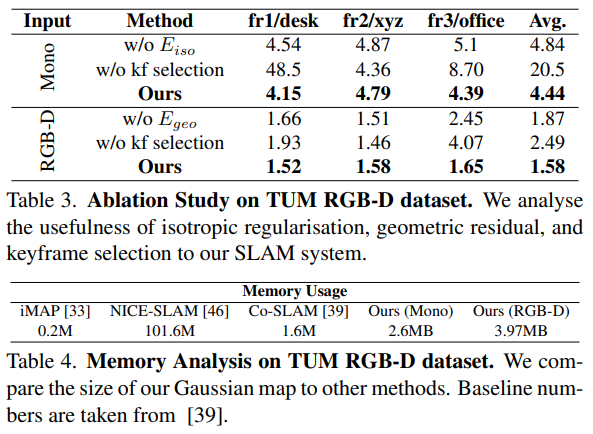
 3d gaussian의 variance들이 isotropic하게 유지한 것이 성능이 더 좋았다고 함. (다른 논문에서도 이렇게 했는데 진짜인가봄) 그래서 아예 3d gaussian 파라미터를 isotropic하게 변경하는 것은 안했고, 그냥 최대한 isotropic하도록 regularization을 추가했다. (수식(10)) |
 |
 |
 |
 |
 |
|
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Hierarchical Scene Coordinate Classification and Regression for Visual Localization (0) | 2023.12.19 |
|---|---|
| COLMAP-Free 3D Gaussian Splatting (0) | 2023.12.18 |
| Gaussian Grouping: Segment and Edit Anything in 3D Scenes (0) | 2023.12.13 |
| Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering (0) | 2023.12.12 |
| SparseGS: Real-Time 360° Sparse View Synthesis using Gaussian Splatting (0) | 2023.12.11 |