반응형
내 맘대로 Introduction

이 논문은 제목에서 짐작할 수 있다시피 3D gaussian과 SLAM을 엮은 것이다. 기존 SLAM이 camera pose랑 scene point cloud를 동시에 획득해나가는 과정이었다면 camera pose와 scene gaussian을 동시에 획득해나가는 과정을 담았다. 하나 아쉬운 점은 제목만 봐서는 Visual SLAM이니 RGB 이미지만 쓰는 것 같지만 까보면 RGB-D SLAM이다. 센서에서 들어오는 Depth 정보를 전적으로 신뢰하면서 이런저런 보정을 해나가는 방식이라 기대에는 살짝 못미치는 내용이었던 것 같다.
핵심 아이디어는 Depth 정보를 이용해 3d gaussian의 유효성을 판단하는 기준을 넣었다는 것이다. 내가 평소에도 생각했던 것이 3d gaussian을 제거하는 logic이 약하다는 것인데 이를 depth 정보를 가지고 logic을 만들어 "제거"에 더 힘썼다.
rendered color와 rendered depth와 RGBD 입력을 비교하면서 3d gaussian을 수렴시키고, 이를 이용해 카메라 포즈를 잡고 하는 과정을 반복한다.
메모하며 읽기
 |
|
 |
intrinsic 알고있는 1개의 카메라로 쭉 훑어서 얻은 RGBD video를 입력으로 가정한다. 1) 한 프레임씩, RGBD 이용해서 3D gaussian 초기화 2) 3d gaussian이 surface 주변에만 있도록 억제하면서 수렴 3) 다음 프레임 가져와서 카메라 포즈 + 기존 3d gaussian 추가 수렴 4) 반복 ---- 기술적으로 2)에서 3d gaussian 억제하는 방법 (+ 추가하는 방법), 3) 에서 안정적으로 수렴시키기 위한 coarse-to-fine strategy를 소개한다. |
  |
3d gaussian recap에 가깝다. 3D GS 논문에서는 카메라 포즈에 대한 notation이 W로 적혀있었지만 여기선 더 직관적으로 P=[R|t] 라고 적었을 뿐이다. P.Inv로 적힌 이유는 P가 camera-to-global 방향이기 때문. ---- 추가적으로 gaussian을 갖고 depth를 렌더링하는 컨셉을 수식(5)와 같이 사용했다. gaussian 중점 위치를 opacity에 따라 적분한 값인데 왠지 살짝 불안한 느낌이 든다. 불투명한 영역의 gaussian이 실제로 opacity 1을 갖는지, gaussian이 실제 물리적 geometry랑 맞아떨어지게 생성되는지 확인이 안된 상태이기 때문에 약간 불안한 것 같다. 그래서 인지 SLAM 대상 공간을 갇힌 방으로 한 것 같기도...? |
 |
학습에 사용하는 loss는 rendered color, rendered depth를 이용한 L1 loss다. RGBD 입력을 갖고 있으니 두 가지 supervision이 가능하기 때문이다. ----------- 학습 과정은 depth가 있기 때문에 3d gaussian의 초기화도 더 쉽고, 유효성을 판단하기도 더 쉬워졌다. 예를 들어, 그냥 backprojection해서 초기 위치 잡아주기도 쉽고, 생성될 때 depth point에서 멀어지면 지워버릴 수 있기 때문이다. ---------- 초기화는 앞서 예를 든 것과 같이 RGBD w/ intrinsic이니 back projection해서 얻는다. 다만 너무 촘촘하게 back projection될테니 H/2, W/2 총 1/4 pixel만 back projection 한다. 논문에서는 새로 생성될 공간을 두기 위해서 그랬다는데 굳이 안그래도 됐을 것 같다. 뒤에 제거하는 logic이 잘 동작한다면 알아서 없앨 것이기 때문이다. |
 |
먼저 새로 생성하는 logic이다. 일단 기존 position gradient를 thresholding해서 생성하는 logic은 버렸다. Depth가 있기 때문에 rendered depth가 sensor depth와 차이가 큰 경우, 해당 pixel에 맺히는 gaussian이 부족해서 그렇다는 logic으로 rendered depth 위치에 추가 생성하는 방식이다. pixel 단위로 보면서 pixel frustrum 내에 1개씩 더 생성해주는 걸 반복하는 모양이다. 웬만하면 rendered depth가 이상한 영역은 관찰이 안되어있는 영역일 것이라는 전제하에 이런 식으로 생성했다고 한다. ---------- 이런 방식이 좋을 수 있다고 생각한 부분은, 어찌 됐든 rendered depth와 sensor depth를 맞추도록 생성을 하니 geometry에 더 가깝게 위치가 잡혀나갈 것 같긴 하다. |
 |
 개인적으로 3D GS 제일 중요하다고 생각하는 제거 logic이다. 모든 3d gaussian의 위치를 보고, surface와 특정 threshold 이상으로 떨어져있을 경우 opacity를 0에 가깝게 강제 초기화하는 방식을 사용했다. surface를 어떻게 아냐고 할 수 있지만 sensor depth가 맺히는 점은 물체든 공간이든 geometry 표면이라는 가정 때문에 각 이미지로 내려찍어서 depth를 비교해보면 쉽게 판별할 수 있다. 한 시점의 surface 뒤에 있는 gaussian은 다른 시점에서 또 다른 surface를 만들 수 있으므로, surface "앞"으로 특정 거리 이상 떨어진 gaussian만 제거한다. 앞뒤 양방향이 아니라 --------- 이런 방식 취하면 공중에 떠있는 noisy gaussian은 확실히 걸러질 것 같다. |
  |
이제 카메라 포즈를 업데이트하는 방법이다. 기존 3D GS에서는 카메라 포즈가 고정되어 있기 때문에 rendering 과정에서 카메라 포즈에 대한 jacobian 계산을 포함되어 있지 않다. 따라서 loss야 rendering loss 밖에 없으니 수식(10)처럼 간단하지만 별도의 jacobian 계산식을 찾아냈어야 했다. 수식(11)과 같은데 chain rule로 color <->camera pose에 관여하는 변수별로 모든 gradient를 계산한 것이다. 하이라이트한 2줄에서 언급하듯이 중간에 view-indepedent color 즉, NeRF와 달리 3d gaussian이 그냥 들고 있는 색상으로 렌더링하기 때문에 color는 camera pose와 직접적으로는 independent하므로 constant가 되는 term이 하나 있고 수식 상 constant는 아니지만 camera pose가 결정되면 항상 같은 수식으로 결정되는 deterministic term이 있어서 이는 무시했다고 한다. ---------- *** 마지막 So we simply ignore the backpropagation of ~~~ 여기 수식 오타인 것 같다. 저 d(JP어쩌구)가 들어갈게 아니라 d(KPX어쩌구)가 들어갔어야 할 것 같다. |
  |
보다 안정적인 카메라 포즈 추정을 위해서 추정 과정에 사용할 gaussian 선별에 조금 힘쓴 느낌이다. 먼저 coarse scale로 이미지를 H/2, W/2로 렌더링을 먼저 해본다음 1) 이 때 사용된 gaussian 중 2) surface와 가깝게 있는 gaussian만 사용했다. 저해상도일 때 굵직굵직하게 기여하는 gaussian만 사용하고 그마저도 surface 근처있는 애들만 쓰겠다는 컨셉이다. 이렇게 선별된 gaussian만 가지고 원래 해상도로 이미지 렌더링해서 loss를 먹인다. |
 |
모든 프레임을 다 registration했든, 아니면 하는 중간이든 현재까지 등록된 프레임에 대해서 계속 BA를 돌아줘야한다. SLAM이니까. 위 과정과 이론적으로는 완전히 동일하지만 candidate이 현재 프레임, 다음 프레임 수준이 아니라 N개 프레임이라는 것이 다르다. 주어진 대상 프레임들 전체를 돌리면 메모리가 터질 수 있으니 일단 K개만 뽑아서 했다. stochastic하게. 뽑아진 K개 카메라 포즈에서 color, depth loss를 다시 계산해서 전부 동시에 최적화하는 방식이다. ---------- 실험해보니 총 iteration 중 절반은 3d gaussian만 절반은 3d gaussian이랑 카메라 포즈 다 업데이트하는 것이 안정적이었다고 한다. |
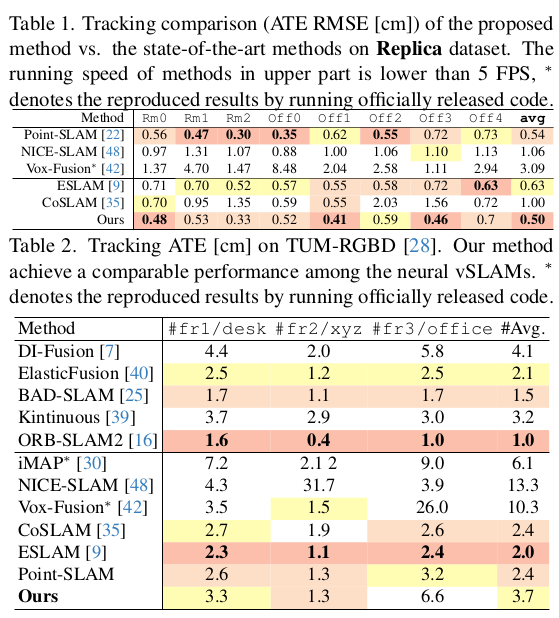 |
 수치가 향상되었다고는 하나, 비교군들 Neural SLAM들이고 RGBD를 쓴 것이기 때문에 일반화되는 성능인지는 모르겠다. |
 |
|
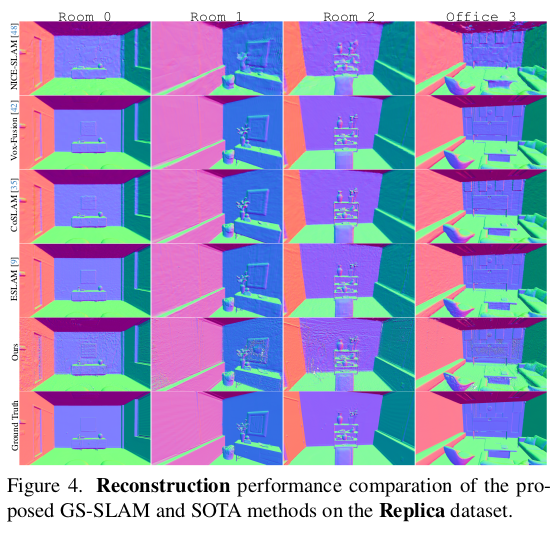 |
 |
 |
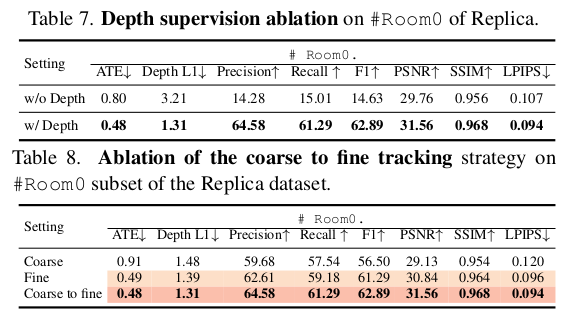 |
반응형