반응형
내 맘대로 Introduction

제목에서 볼 수 있다시피 view가 부족할 때 학습시키는 방법론을 제시한 논문이다. 360도라고 해서 object centric이 아닌 이미지나 omnidirectional 이미지를 생각했는데 아니었다. 그냥 object centric으로 360도 뱅뱅 돌면서 찍었다는 이야기로 360도 자체가 의미를 갖진 않는 논문이다.
겉으로 드러나는 핵심 아이디어는 pretrained mondepth prior를 사용한 것이다. 하지만 적용하는 방법에 있어서 조금 더 디테일했다. 다른 논문들은 monodepth 이미지의 scale을 주어진 SfM point를 갖고 1개 찾아내고 끝인데, monodepth는 원래 부분적으로 scale이 다를 수도 있음을 지적하면서 patch base로 비교하는 식이다.
더 나아가 diffusion model을 활용해서 SDS loss로 training view에 없었던 시점에 대해 추가 보정을 해준다 (의미는 잘 모르겠음)
테크닉적인 것은 pruning인데, rendered depth와 one dominant gaussian depth를 이용해서 gaussian을 소멸시킨다.
디테일한 내용들이 참고하기 좋음
메모하며 읽기
 |
|
 |
1) rendered depth 로 patch 단위 supervision 2) SDS loss로 unseen view 보강 3) color loss 4) rule based pruning |
  |
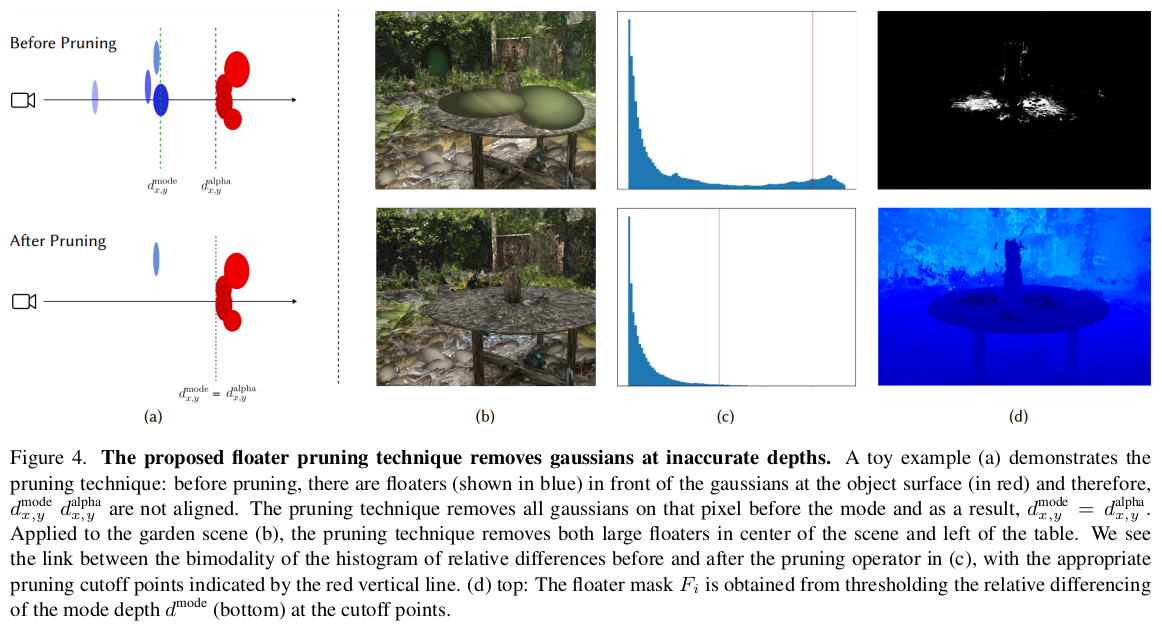
 이 논문의 테크니컬 핵심이라고 할 수 있는 pruning이 rendered depth와 one dominant gaussian depth(mode depth)를 비교하는 것으로 시작하기 때문에 depth를 정의하고 시작한다. rendered depth를 알다시피 gaussian depth들을 alpha blending해서 얻는 값 mode depth는 가장 alpha blending에 기여도가 큰 gaussian 값이다. w가 가장 큰 gaussian ---------- 그림으로 보면 rendered depth는 alpha blending결과 "average"되는 느낌이기 때문에 녹색 점선 위치로 계산되는데 mode depth는 가장 기여도가 큰 gaussian 위치로 확정되므로 빨간색 점선 위치가 된다. |
 |
depth supervision에 사용할 gt는 monodepth (scaleless)를 사용했다. |
  |
depth supervision은 여느 monodepth GT 사용한 논문들과 다르게 patch 단위로 사용했다. monodepth output이 단일 scale, shift를 적용한다고 모든 영역에서 mm 단위로 환산되지 않는다. 이미지 구역 별로 왜곡이 있듯이 서로 다른 scale을 갖고 있을 수 밖에 없다. 따라서 이미지 전체를 갖고 loss를 비교하는 것이 scale을 맞추는 것도 불가능할 뿐더러 맞추더라도 왜곡이 있어서 효과가 떨어진다. 저자들은 이 문제를 해결하기 위해 일단 이미지를 patch 단위로 랜덤하게 쪼갰고 patch 안에서도 scale에 무관하게 depth correlation으로 loss를 계산했다. 이렇게 되면 scale ambiguity이 다른 문제는 correlation 형태로 극복, 이미지 영역마다 scale이 다른 왜곡 문제는 patch로 해결된다. |
  |
다음은 pretrained diffusion model을 활용한 SDS loss다. 길게 적혀있지만 unseen view를 augmentation하기 위한 방법을 길게 적어놨을 뿐 핵심은 그냥 unseen view에서 렌더링한 이미지에 noise를 추가하여 diffusion model을 통과시키는 과정에서 발생하는 gradient를 사용한다는 것이다 정확히 SDS loss 그대로 사용하는 것 introduced noise와 predicted noise를 비교한다고 막 새롭게 적혀있는데 이건 원래 SDS loss 수식보면 안에 eps 끼리 빼는 term으로 적혀있는 내용을 글로 다르게 쓴 것일 뿐이다. |
 |
|
   |
 pruning 부분이다. pruning의 주요 타겟은 floater (공중에 구름처럼 떠있는 노이즈)인데 양상을 보면 앞서 정의한 mode depth와 rendered depth 간의 차이가 크다는 것이다. 그도 그럴 것이 갑자기 형상과 관계없이 공중에 큰 놈이 떠있으면 mode depth는 그 형상과 관계없이 공중에 있는 큰놈으로 잡힐 것이기 때문이다. 그래서 이 mode depth - rendered depth가 차이가 큰 픽셀에 대해서 pruning을 적용한다. ------------------- 방법은 좀 heuristic한데 픽셀 별로 dip-test라는 것을 적용한다. (잘은 모르겠지만 분포가 주어졌을 때 peak가 하나인지 1개 이상인지 score를 뱉어주는 같다.) 이 score와 mode depth - rendered depth 차이가 특정 기준 이상이면 제거 대상 픽셀이 되고 해당 픽셀에 존재하는 gaussian 중 mode depth보다 가깝게 있는 것들은 제거된다. dip test에서 score를 뽑아낼때 사람이 정하는 파라미터 a와 b가 있는데 이는 다양한 데이터에 대해서 3d gs를 복원해보고 사람이 대충 때려 맞췄다고 한다. |
 |
종합 loss는 이렇게 + pruning 가끔하고 재학습 |
 |
|
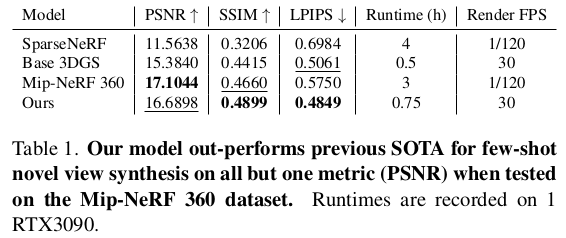  |
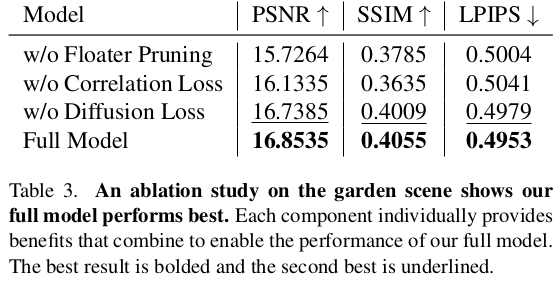 ablation 보면 SDS loss는 그 정도 연산량을 감당하고 쓸 가치가 있는지 의문이 든다. |
 |
|
 |
|
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Gaussian Grouping: Segment and Edit Anything in 3D Scenes (0) | 2023.12.13 |
|---|---|
| Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering (0) | 2023.12.12 |
| SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM (0) | 2023.12.11 |
| Mip-Splatting: Alias-free 3D Gaussian Splatting (0) | 2023.12.07 |
| LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS (0) | 2023.12.05 |