반응형
내 맘대로 Introduction
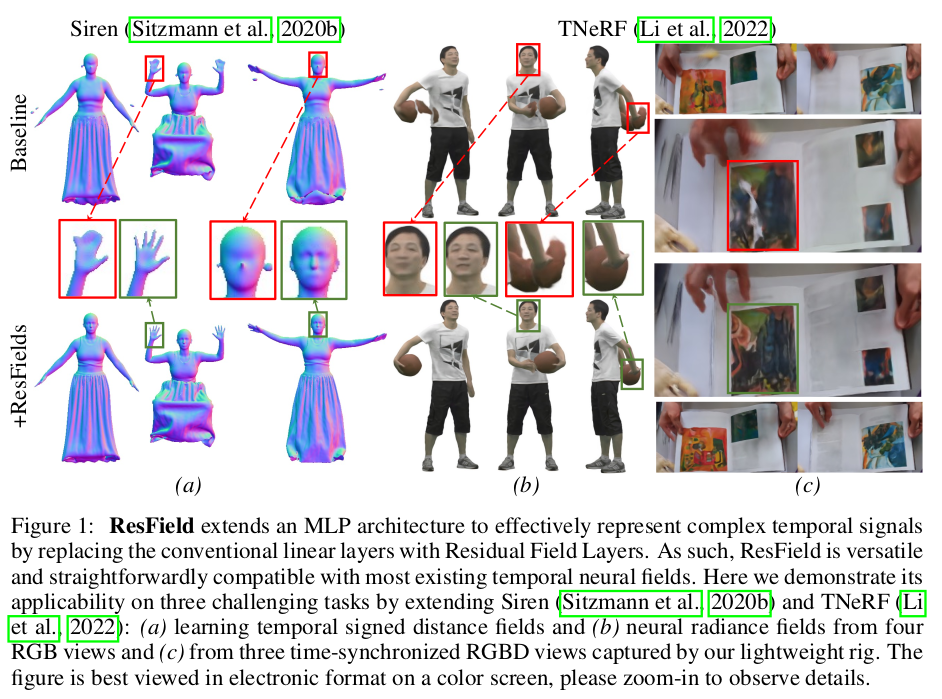
이 논문은 제목과 첫 인트로 그림만 봐서는 D-NeRF, DyNeRF HexPlane 등 time dimension을 추가한 NeRF 느낌이지만, 사실 핵심은 그게 아니다. 물론 time dimension에 대해서 주로 테스트한 것은 맞다.
핵심 아이디어는 네트워크 크기(파라미터 수)를 늘리지 않으면서 네트워크의 capacity는 늘리는 방법이다. 네트워크 크기가 커지면 학습이 느려짐과 동시에 렌더링 속도도 느려진다는 것은 이미 밝혀져있다. 하지만 네트워크 크기를 늘리지 않으면 네크워크가 표현할 수 있는 한계치가 있어 성능을 어느 정도 포기해야 한다.
이 논문에서는 네트워크 크기는 그대로 두되, 매 layer마다 residual weight를 두어 capacity를 늘리는 방법을 소개한다. 완전 새롭다기 보다 transformer 구조에서 LoRA가 큰 효과를 보여준 것과 비슷한 것 같다. MLP 구조는 그대로 두되 특정 조건에서 기존 weight에 residual weight를 더해주어 새로운 weight로 만드는 방식으로 capacity를 늘린다. 이러면 속도 저하 문제가 전혀 없다.
여기서 특정 조건이라는 것이 time이 만만하니까 time을 예시보여준 것이다. 하지만 residual weight를 사용하는 방식 자체는 다른 아이디어로 활용도 가능해보인다.
메모하며 읽기
 |
사실 전체 논문 내용은 옆의 그림 한 장으로 끝난다. 각 MLP 내부 weight에 time stamp 별로 더해질 residual을 따로 만들어둔다는 내용이다. MLP + n * W * t 개 파라미터로 늘어나지만 weight를 바꿔치기 하는 방식이라 속도 저하가 없다. |
   |
| 기존 NeRF가 위와 같이 formulation이 되는데 각 Layer에 들어있는 Wi 가 달라질 뿐이다. 매 layer마다 time stamp에 따라 Wi(t)가 Wi에 더해져서 사용된다. 아주 간단하다. 이러면 Wi가 general info를 추출하고 Wi(t)가 그 외 temporal info를 추출하는 모양으로 분리될 것 같다. |
  |
| 하나 그래도 아쉬운 점은, Wi(t)가 생각보다 작진 않다는 것인데 MLP 내부 layer마다 있으니 일단 개수가 많을 것이고 MLP가 1024내지 768 dimension을 쓰는데 이럴 경우 1024x1024xC, 768x768xC이 넘는 크기라 각각이 작다고는 할 수 없다. 따라서 모델 자체 크기나 속도와 별개로 저장 용량이 커지는 문제 때문에 기존 TensoRF에서 쓴 방식을 차용하여 matrix-vector decomposition을 사용한다. 그림 3과 같이 3D tensor로 weight를 들고있는게 아니라 효율 저하를 좀 감수하더라도 vector x matrix 형태로 나누어 들고 있도록 디자인했다. |
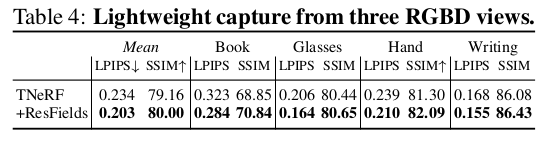
 웬만한 경우에 +@로 적용하면 성능이 올라간다는 식으로 수치를 보여줬다. |
 |
 |
|
 |
|
  |
 |
반응형