내 맘대로 Introduction

이 논문은 2019 CVPR논문이니 나온지는 꽤 됐고 지금 보면 그렇게 신선하다고 할 순 없지만, sarlin 팬이 되어버려 찾아읽었다.
https://github.com/cvg/Hierarchical-Localization/tree/master
GitHub - cvg/Hierarchical-Localization: Visual localization made easy with hloc
Visual localization made easy with hloc. Contribute to cvg/Hierarchical-Localization development by creating an account on GitHub.
github.com
SIFT가 아닌 keypoint/descriptor로 COLMAP을 돌릴 수 있도록 작성된 hloc에서 참조하는 논문이기도 해서 읽어두면 좋을 논문이다.
내용 자체는 Large scale scene에서 localization을 잘하기 위한 단계적 접근법이다. 이 논문이 등장하기 전, 과거에는 3D map과 2D image feature를 matching하고 PnP 푸는 정도의 scope였기 때문에 자연스럽게 좁은 공간에서의 localization만 생각했다. 하지만 large scale 즉 도시 단위로 넘어가면서 2D-3D matching을 RANSAC으로 커버하기엔 무리가 생겼고 더욱이 어플리케이션까지 생각하면 더 이상 오프라인 localization만 생각할 수 없었기 때문에 이 논문이 새로운 방법론을 뚫었다.
다시 말하지만, 지금 보면 이게 당연한 접근법처럼 보이는데 이 논문으로 하여금 당연하게 보이게 되었다고 보는게 맞다. 사람들이 이 논문을 보고 그렇게 접근하기 시작한 것이니까!
핵심 내용은, 1) global descriptor를 이용한 image retrieval로 대충 영역 줄이기, 2) retrieved images로 3D matching 대상 point추리기 3) feature matching + PnP w/ RANSAC으로 localization하기다. 동시에 1)2)3) 과정을 실시간으로 하기 위해서 빠르게 global descriptor, local feature를 뽑아내는 네트워크를 같이 제안했다.
메모하며 읽기
 |
large scale localization할 때 순서도를 다음과 같이 말한다. 1) global descriptor를 갖고 database에서 query 이미지와 유사한 reference 이미지 모으기 (카메라 포즈도) 2) reference 이미지끼리 covisibility 체크해서 그룹핑해주고, 그룹마다 covisible 영역에 있는 3D point 모으기 3) 2D-3D correspondence matching + PnP w/ RANSAC으로 localization하기 |
  |
이 과정에서 global descriptor와 local feature가 매번 필요한데 이를 기존 SOTA 알고리즘들(이 당시 NetVLAD, SuperPoint)을 가져다 쓸 수도 있지만 각각이 무겁다보니 이를 실시간으로 쓰기 위해선 경량화할 필요가 있었고, 거의 성능 저하없이 global descriptor, local feature를 같이 뽑아주는 가벼운 HFNet이라는 네트워크를 디자인해서 사용했다. --- 실시간이 아니라면 SOTA 그대로 쓸 수도 있다! 실제로 hloc github에 그렇게 구현되어 있음. |
 |
 HFNet은 이미지를 입력으로 받고 각기 다른 head를 통해 global descriptor와 localfeature, keypoint까지 동시에 뱉어주는 통합 네트워크다. 학습만 잘 시켜두면 단 하나의 네트워크에서 위에 제시한 파이프라인을 태울 때 필요한 모든 정보가 나오기 때문에 속도 측면에서 이득을 굉장히 크게 가져갈 수 있다. |
  |
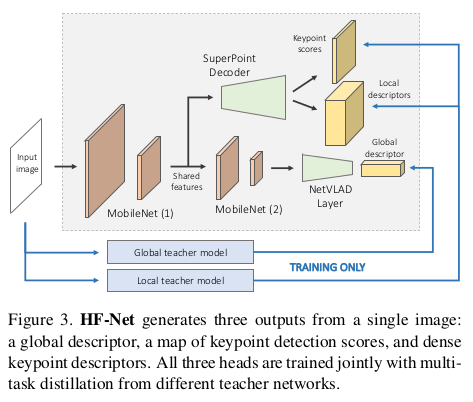 구조 자체는 mobilenet backbone에 keypoint/local feature/global descriptor heads가 붙은 형태로 간단하다. 실시간성을 목적으로 하기 때문에 최대한 가벼운 형태의 backbone을 사용했다. 후술되어 있지만, 독특한 점은 pretrained superpoint decoder와 NetVLAD layer가 붙어있다는 점인데 이는 두 알고리즘의 도움을 받아 성능을 끌어올리겠다는 컨셉이기 때문이다. 최대한 SOTA와 닮은 형태의 local feature, global descriptor를 만들어내기 위한 노력이다. |
  |
더불어 눈여겨 볼 점은 따로 GT로 학습하는 것이 아니라 SOTA 알고리즘을 teacher로 두고 pseudo GT로 학습한다는 점이다. GT가 있다면 직접 학습했겠지만 large scale scene에 맞는 데이터가 존재하지 않기 때문에 무한히 많은 데이터를 찍어내기 위한 트릭으로 teacher-student 형태를 차용했다. 2019년 이 당시 핫했던 self-supervised, self-distillation 의 컨셉을 녹였다고 보면 되겠다. ---- 이렇게 학습을 시키기 때문에 더욱 더 HFnet 결과가 superpoint, NetVLAD와 닮아있어야 했고, 그래서 superpoint decoder, NetVLAD layer가 freeze된 상태로 붙었다. ------------------------ 여기까지가 내용 전부인데, 지금 보면 너무나 당연한 이야기고 널리 알려진 트릭들이다. 하지만 2019년 당시에 large scale scene으로 scope를 확장하는 것과 동시에 self-distillation 컨셉을 가져와서 실시간성까지 확보한 형태로 구현했다는 것이 각광받았던 논문이다. 2023년 11월 기준으로 인용 수가 600회가 넘어가니 나름 기념비적인 논문이라고 볼 수 있다. |
 |
일단 SOTA 중 왜 SuperPoint와 NetVLAD를 썼는지 성능 지표로 보여준다. |
 |
|
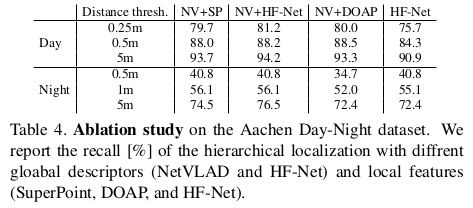  |
 |
 |
 |