반응형
내 맘대로 Introduction

이 논문은 제목에서는 indoor 공간으로 한정했지만 컨셉 자체는 MVS와 neural rendering을 합쳐서 surface reconstruction 속도/성능을 끌어올리는 것이다. MVS를 돌릴 때 초기화에 neural rendering 현상태 값을 쓰고, neural rendering 학습시킬 때 MVS 결과를 쓰는 식으로 상호 보완적인 형태를 구현했다.
MVS와 neural rendering 각각에서는 기존 SOTA를 가져와서 사용했기 때문에 contribution이 명확하지 않으나, 엮어서 학습하는 파이프라인 자체가 contribution이다. 또한 MVS를 학습 중간에 쓸 수 있는 형태로 재구현했다는 점이 의미가 있다. 논문을 읽어보면 ACMP를 기본으로 하는 것 같은데 이걸 재구현해낸 것만으로도 충분히 가치있는 연구였다고 생각한다.
이름에 들어있는 Helix는 알고리즘 상의 어떤 특징 때문에 붙여진 것은 아니고 위 그림의 curve를 보면 다른 curve 대비 확 줄어든 curve 모습에 빗대어 붙여진 것이다.
메모하며 읽기
 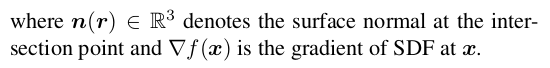 |
 |
| neural rendering 쪽은 NeuS를 차용했다. | MVS 쪽은 patchmatch MVS+ planar prior 즉, ACMP를 차용했다. |
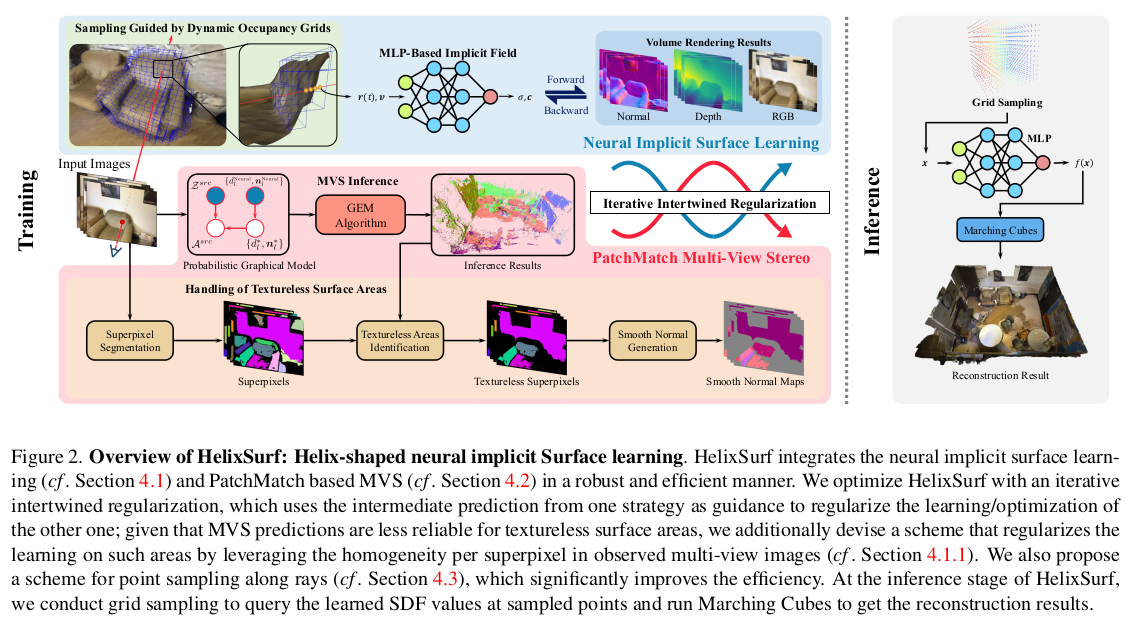 |
|
   |
neural rendering은 러닝 기반이다 보니 smoothness에 강점을 갖고 있다. 즉 공간 안에서 예측값들이 continuous하게 변화하게 만드는 장점이 있다. 다만, 이미지 단위로 보기 때문에 global 정보는 학습되길 기대하는 것이지 명시적으로 담겨있지 않아 piece-wise한 특성이 있다. 반면 MVS 같은 경우, 예측값은 discrete하고 noise도 심하지만 consistency를 기준으로 global context를 보며 수렴한다는 장점이 있다. 따라서 MVS <-> NR 사이에는 상호보완적인 면모가 존재한다는 뜻이다. --------- 위 그림에서 살펴보면, NR과 MVS가 병렬적으로 진행되는데 (물론 매 iteration마다 돌진 않겠지만) 서로가 서로를 초기화하고 constrain하는 구조로 되어있다. |
  |
먼저 MVS가 NR을 도와주는 방법이다. 수식(5)는 NR의 color loss 그대로 이고 수식(6)이 핵심이다. MVS에서 신뢰도있게 depth, normal을 찾아낸 pixel에 한해서 (indicator가 있는 이유) NR로 만든 depth, normal과 l1 loss를 걸어주는 방식이다. 단순히 l1 loss를 걸어주는 것보다는 현 상태의 weight를 계산해주는 것이 안정적으로 수렴하는데 도움이 될 것이므로, 현 NR color가 gt color와 얼마나 비슷한지를 weight로 사용해서 weighted l1 loss를 걸어주었다. ---- 이렇게 걸어주면 NR이 MVS 결과에서 크게 벗어나지 못하도록 억제됨과 동시에 MVS값을 초기값으로 사용할 수 있게 된다. |
  |
수식(6)의 아쉬운 점은 MVS가 성공한 영역에 대해서만 NR을 도와줄 수 있다는 것인데 조금 더 보강하기 위해 patch 개념을 도입한다. (약간 ACMP에서 2d triangulation으로 만든 삼각형 단위로 같은 plane을 할당하는 것처럼 여기선 superpixel마다 같은 plane을 할당하는 느낌이다. ) 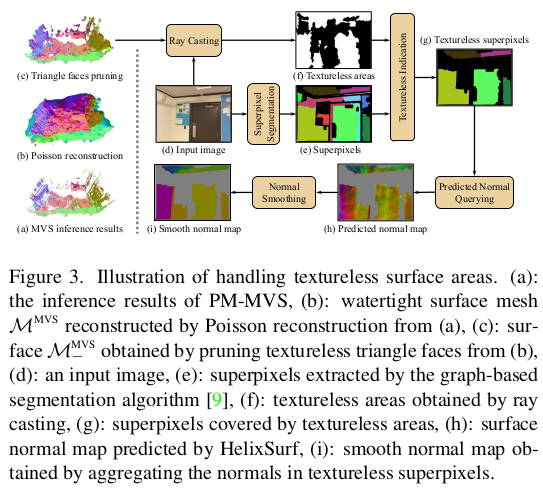 이미지를 superpixel로 나눠보면 texture-less region은 크게 texture-rich region은 작게 형성될 것인데 이 영역은 대충 비슷한 geometry를 가진다고 가정해서 같은 depth, normal을 갖는다고 가정할 수 있다. 이렇게 가정해버리면 특히나 texture-less region에는 MVS 실패 pixel들이 많을텐데 이 부분이 그냥 채워져버리고 NR을 돕는데 같이 기여하는 형태가 되버린다. 수식(7)을 보면 superpixel 내부 normal의 평균 + multiview 로 비교하면서 평균 만들어서 현재 normal 값과 비교하는 방식이다. ----- 한 이미지 superpixel 안이라면 같은 normal을 갖도록 + multiview 에서 해당하는 superpixel 안에서도 같은 normal을 갖도록 보조한다. 다시 한 번 짚지만 texture-less region 즉 MVS가 실패하는 pixel도 NR을 돕는데 기여하도록 만들기 위한 loss다. |
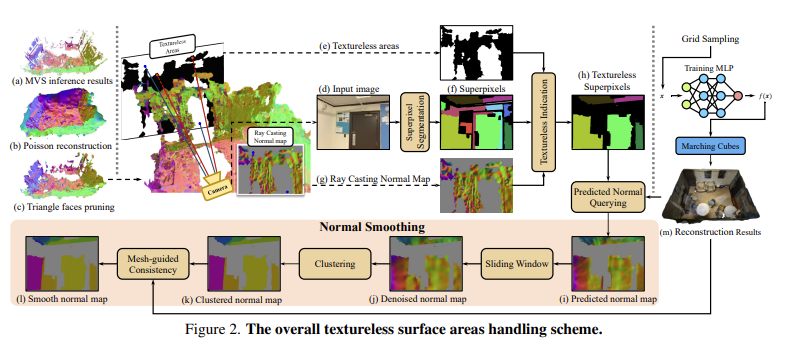 |
|
 |
이제는 반대로 NR이 MVS를 돕는 방식이다. 직접 돕는다기 보다 초기화를 돕는다. MVS가 patchmatch 기반이므로 맨 처음에 pixel마다 depth,normal을 완전 random initialization하는데 NR이 어느정도 학습을 거쳤다면 완벽하진 않지만 꽤나 준수한 depth, normal을 pixel 단위로 뽑아줄 수 있을 것이다. 따라서 depth, normal을 random값으로 쓰는 것이 아니라 NR에서 계산한 값으로 초기화한 뒤 MVS를 돌리는 방식이다. |
 |
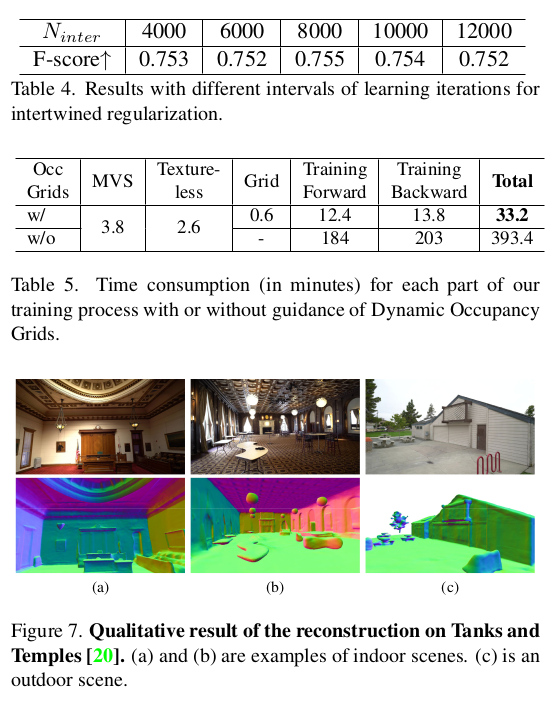
이부분은 잡다한 팁으로 ray 상에서 point sampling하는 것이 어디서나 성능, 연산량과 직결되는 문제다 보니 여기서도 고민했고, 나름의 방법을 찾은 듯 하다. 지금 다루고 있는 공간을 voxel grid로 쪼개서 occupancy를 계산해본 뒤, occupied voxel 위치 내부에서만 point sampling이 이루어지도록 했다. (효율이야 좋아지겠다만 voxel grid를 잡아야 되는 순간부터 공간 크기가 제약되므로 별로 좋진 않은 방식 같다. 그래서 indoor로 제한해서 실험한 것이 분명하다.)  supplementary를 보면 64x64x64 썼는데... indoor밖에 못할 사이즈긴 하다. |
 |
total loss는 수식(9)와 같다. 몇번 마다 MVS를 새로 돌려주는지가 안나와있어서 코드 봐야할 것 같다. occupancy grid는 16 iteration마다 재계산했다고 한다. 이걸 보면 MVS도 cuda로 구현해서 꽤나 자주 업데이트해주었을 것 같음. |
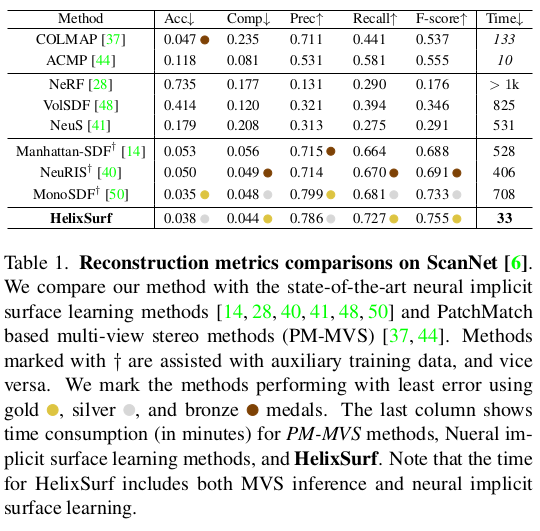 |
 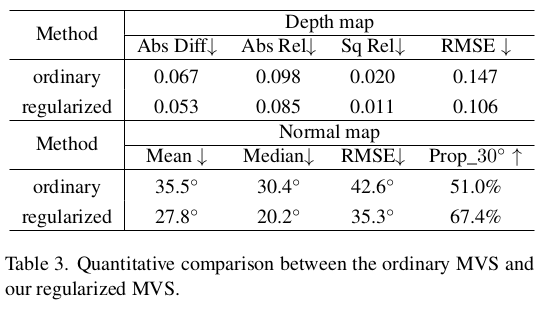 |
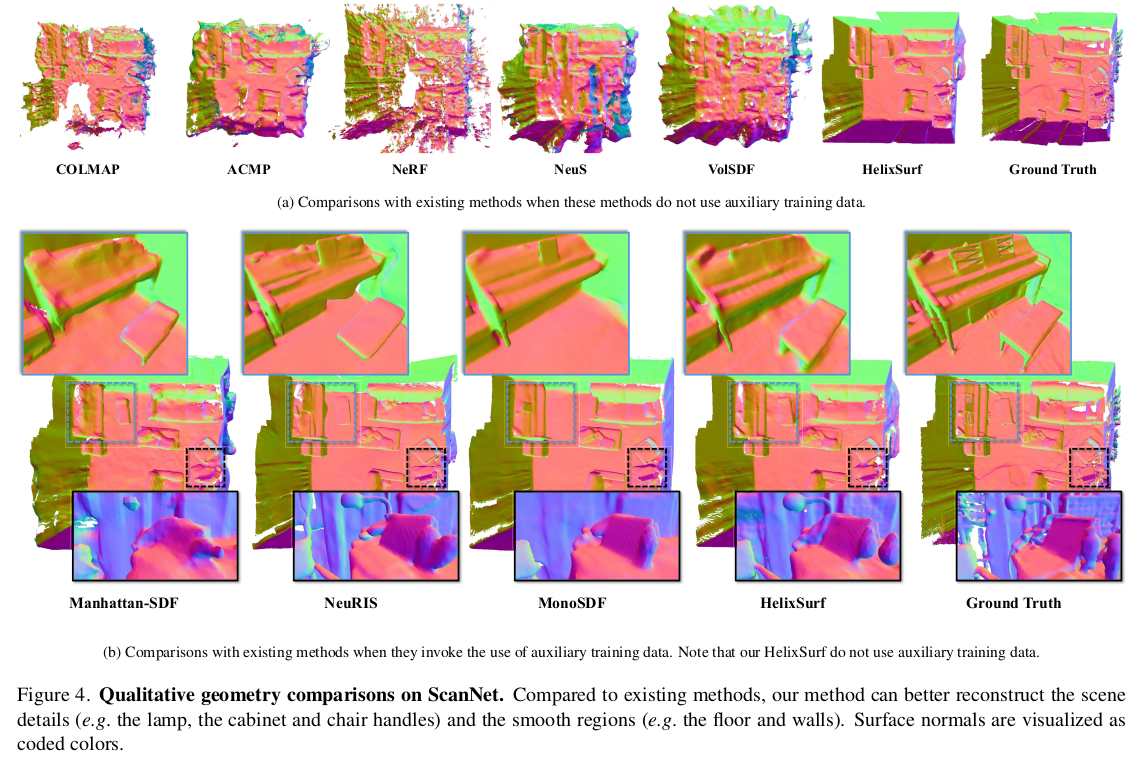 |
|
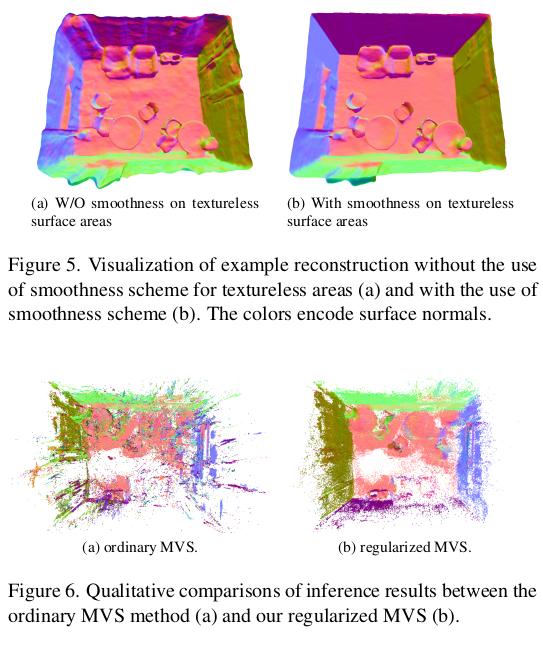 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| From Coarse to Fine: Robust Hierarchical Localization at Large Scale (0) | 2023.11.21 |
|---|---|
| ResFields : Residual Neural Fields for Spatio-temporal Signals (0) | 2023.11.17 |
| K-Planes: Explicit Radiance Fields in Space, Time, and Appearance (0) | 2023.11.14 |
| HexPlane: A Fast Representation for Dynamic Scenes (0) | 2023.11.14 |
| Dynamic 3D Gaussians : Tracking by Persistent Dynamic View Synthesis (0) | 2023.11.14 |