반응형
내 맘대로 Introduction
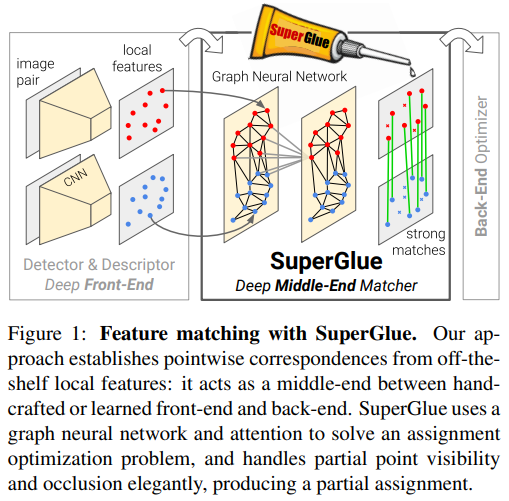
Superpoint와 시리즈물로 불리는 superglue라는 이름의 feature matcher다. 보통 keypoint는 descriptor가 존재하면 descriptor를 갖고 BF matching을 하거나 Flann matching을 하는 등 단순하게 descriptor similarity를 기반으로 matching하는 것이 기본이다. 하지만 이렇게 하면 descriptor가 유효한지 무효한지 구분력 없이 그냥 매칭하기 때문에 오매칭이 굉장히 많아 별도의 filtering이 필요하다. cross-check를 하는 것 + homography filtering이 그 예시다.
이 논문은 이러한 문제를 해결하기 위해 matching을 딥러닝에 맡긴 논문이다. 보통 SfM에서 track 형성하는 front-end, 최적화하는 back-end로 나뉘는데 이 논문은 track 형성의 후반부를 대체할 수 있는 기능을 하기 때문에 middle-end라고 하며 GNN을 이용해 keypoint+descriptor -> matching score를 내뱉는다.
메모하며 읽기
  |
keypoint는 이미지 A, B가 있을 때 일대일 대응 관계를 만족해야 하고, 일대일 대응이 안된다면 매칭이 없다고 간주한다는 사실을 전제로 한다. 따라서 문제 formulation을 하길 주어진 keypoint +descriptor 그룹 A (크기M), B(크기N)가 있을 때 두 그룹 간 매칭 확률을 의미하는 MxN 크기의 soft assignment matrix P를 추정하는 것을 목적으로 한다. 일대일 매칭을 만족해야 하기 때문에 P matrix의 row 방향 혹은 column 방향 sum은 항상 1보다 작음을 만족해야 한다. |
 |
|
 |
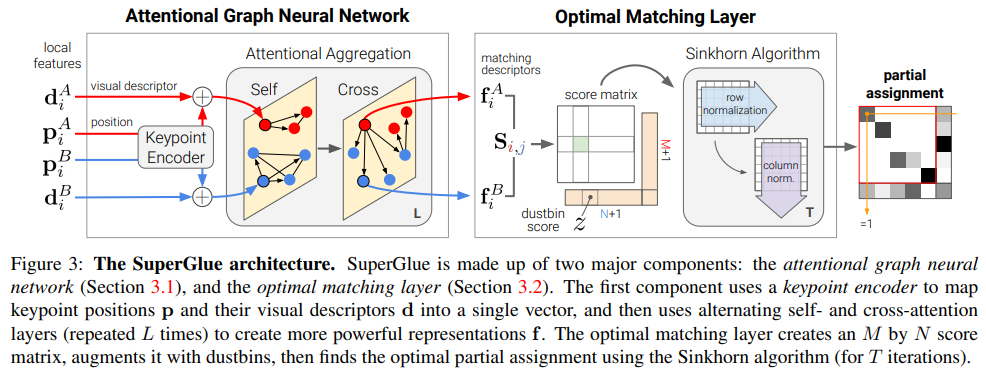
두 이미지에 존재하는 keypoint + descriptor를 입력으로 받는 attentional GNN, 그 결과로 나오는 mathicng descriptor를 받아 최종 matirx P를 출력하는 optimal matching layer로 구성되어 있다. 전자는 학습 기반이고 후자는 sinkhorn 이라는 알고리즘을 differentiable 하게 만든 것 기반이다. |
 |
keypoint는 xyz 그대로 들어가면 도메인도 너무 넓고 dimension도 3밖에 안되기 때문에 간단한 MLP를 통해 encoding 해준뒤 사용한다. sum으로 더해지기 때문에 dimensino을 descriptor dimension과 동일하다. |
 |
encoded keypoint + descriptor 를 받아 처리하는 GNN은 transformer에서 빌려와서 self-attention과 cross-attention으로 처리된다. self-attention은 같은 이미지에 있는 feature끼리 연산되고, cross-attention은 다른 이미지 간에 있는 feature 끼리 연산된다. edge 형성은 아직 이웃한 관계를 정의할 수 없기 때문에 전부 연결되어있는 fully connected graph라고 볼 수 있겠다. 학습은 self 한 번 cross 한 번으로 진행된다 여기서 keypoint 개수가 매번 다르기 때문에 sum, concat 등의 방식으로는 모든 연결 관계에서 오는 feature들을 입력으로 삼을 수 없으므로 aggregation 해서 사용한다. 뒤에 나옴. |
  |
 aggregation은 candidate keypoint feature 간의 q,k,v를 이용한 attention으로 계산한다. 각 keypoint feature를 q, k, v로 나눈 뒤, softmax(q, k) * v 계산 후 전부다 더한다. 그냥 정확히 attention mechanism 그대로다. 이렇게 aggregation feature를 만든 뒤 GNN을 다 통과하면 최종적으로 linear projection을 통해 matching descriptor가 된다. |
 |
matching feature로 전부 계산이 완료되면 soft assignment matrix P를 계산하는 과정이다. 먼저 mathicng feature 간의 score matrix를 구하는 것을 먼저 한다. 대부분의 알고리즘들은 여기서 끝. score는 내적(cosine similarity)로 정의해서 계산하면 되고 특이점은 M x N matrix가 나올텐데 마지막 row, 마지막 column을 dust row, clumn으로 추가해주는 것이다. superpoint에서 dustbin을 추가해주는 것과 비슷한데 매칭이 없을 수 있음을 더욱 분명하게 만들어주기 위해서 일종의 helper row, column이다. 설령 similairty가 0이 아니더라도 이 dust row와 dust column이 0일시 무시하는 식으로 구현할 수 있어서 오매칭에 효과적일 것으로 보인다. |
  |
  sinkhorm 알고리즘은 깊게 들어가지 않고 직관적 이해만 한다면, optimal transport system solution을 구하는 알고리즘으로 비용을 최소로 하는 이동 경로를 얻어내는 알고리즘이다. 가령 빵집 a, b가 학교 c, d에 빵을 납품한다고 했을 때 a-c, a-d, b-c, b-d 경우의 수는 각각 비용이 다를 것이다. 빵집과 학교와의 거리, 빵의 가격 등등 이런 경우 사용하는 알고리즘인데 입력 (a,b), (c,d) 그리고 abcd 간 score가 주어지면 (a,b),(c,d) 간 연결 관계를 출력으로 내준다. ------- 우리 경우에 대입해보면 지금 matching feature fa와 fb가 있고 score가 있으니 딱 맞는 설정이라고 볼 수 있다. score matrix S가 있으니 그냥 row 방향이나 column 방향으로 softmax를 취해서 매칭 값 구하면 안되나? 할 수 있는데 이렇게 하면 일단 기존 BF matching이랑 다를게 없고 M의 크기, N의 크기에 bias 같은게 생길 뿐만 아니라 row 위주로 볼때 bias, column 위주로 볼 때 bias 같은게 생길 수 있다. 따라서 공평하게 bias 없이 계산하는 방법으로 sinkhorn을 사용한 것이다. ---- 이걸 differentiable 하게 구현해서 사용했다고 한다. |
 |
loss는 일단 GT correspondence가 있기 때문에 해당 위치의 P matrix 값이 최대가 되도록 해주었다. 추가적으로 correspondence i, j가 있으면 i에 가능한 많은 j candidate가 생기고, j에 가능한 많은 i candidate가 생길 수 있도록 (즉 recall이 일단 높아질 수 있도록) 각각 row, column 방향으로 line 단위의 확률도 높아지도록 했다. |
 |
요건 그냥 참고. transformer에서 가져온 개념이 많은데 왜 transformer 안쓰고 GNN 썼냐 이런 질문들을 예상했는지 아예 FAQ를 논문에 삽입해둔 것 같다. |
   |
 |
  |
|
 |
|
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| PatchMatch Stereo - Stereo Matching with Slanted Support Windows (0) | 2023.11.07 |
|---|---|
| LightGlue: Local Feature Matching at Light Speed (0) | 2023.11.06 |
| SuperPoint: Self-Supervised Interest Point Detection and Description (0) | 2023.11.05 |
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2023.11.03 |
| Detector-Free Structure from Motion (0) | 2023.11.02 |