반응형
내 맘대로 Introduction

이름에서도 알 수 있다시피 superglue의 후속작이다. 같은 저자가 쓴 논문이고 풀고자 하는 문제도 여전히 feature matching으로 같다. 핵심 내용은 사실 상 superglue에서 성능과 속도 trade off를 만드는 요소를 분석해서 이를 대체한 것이다.
연산량이 많은 들어가면 sinkhorn 알고리즘을 대체한 것, iterative refinement를 정해진 횟수를 다 돌지 않고 중간에 중단할 수 있는 logic을 만든 것이 속도 상승의 핵심이고 feature similarity에만 의존하던 correspondence 선별을 matchability라는 개념을 추가해서 보강하는 것이 성능 상승의 핵심이다.
메모하며 읽기
 |
일단 성능은 둘째치고 iteration 중단 컨셉은 왜 등장했냐면, 사람도 좌우 이미지를 비교할 때 view point 차이가 심해서 한 눈에 같은 장소인지 인식이 안될 경우, 좌우 이미지를 번갈아 보는 횟수가 늘어난다. 따라서 시각적으로 overlap이 많으면 적게 보고, 적으면 많이 보는 것이 직관적인 형태라는 것이다. 이미지를 더 관찰해야 하는지, 덜 관찰해야하는지 결정하는 로직을 추가해서 이러한 직관을 알고리즘으로 구현했다. |
 |
|
 |
전체적은 과정은 superglue와 크게 다르지 않다. 애초에 시발점이 superglue의 design choice를 분석한 것이기 때문이다. 1) keypoint position 정보가 더 이상 absolute positional encoding (MLP based)로 이루어지지 않고 rotary encoding으로 변경된 것 : 이제 keypoint 간 상대 거리가 주요 encoding 대상이 됨. 2) 중간 중간 keypoint feature 마다 confidence를 평가한 뒤, 이미지 단위로 평균을 내어 refinement iteration을 중지할 것인지 평가함 3) sinkhorn으로 하던 것을 MLP 기반 similiarity + new matchability로 변경함. |
  |
attention 개념은 이전과 동일하다. 이미지 내 혹은 이미지 간 feature aggregation을 통해 m 을 만들어 사용하는 구조 그대로다. local feature는 q, k, v로 projection 된 뒤 attention mechanism을 통과하고 모든 correspondence 경우에 대해 sum된 형태로 m이 된다. 여기서 저 q,k 의 곱으로 표현되던 attention이 self와 cross 각각 약간 변형이 되어 있다는 점이 차이일 뿐이다. 단순 q,k matrix multiplication으로 구현하지 않고 rotary encoding을 더하고, bidrectional attentetion으로 구현했다. |
  |
이전에 superglue는 keypoint encoder를 통해 position feature를 만들어 더해주는 식을 사용했는데, 이러한 absolute positional encoding 범주에 속하는 방식은 분석을 해보니 iteration을 거듭할수록 그 의미가 사라졌다고 한다. 따라서 absolute 보다 relative positional encoding을 사용하기로 했고, 이는 self-attention에 반영되었다. ( keypoint의 절대적 위치는 언제든 변하니까 keypoint 간의 간격이 더 큰 의미를 갖고 있다는 것이 직관적으로도 맞는 것 같다. 더불어 cross attention에 반영하지 않은 것은 view point 차이에 따라 relative 값이 너무 크게 바뀔 것이므로 absolute 와 비슷한 이슈를 겪을 것 같으니 self에 가해주는게 맞는 듯) d dimension feature를 rotary encoding할 때 d dimension 그대로 사용하면 수식(4) matrix가 0 filled region이 적고 dense 해지므로 연산량이 늘어난다. 기존 rotary positional embedding에 하듯이 2차원 단위로 끊어서 넣어줬다. |
 |
cross attention은 원래 q, k, v 중 q만 다른 이미지에서 가져와서 사용하는 것인데 이렇게 되면 A -> B, B->A 두 번 계산해야 하므로 연산이 2배다. 이를 간소화하기 위한 방법으로 bidirectional attention이라는 개념이 있는데 수식(5)와 같이 두 이미지에서 온 k만 곱해서 attention으로 사용하는 것이다. 이렇게 되면 연산량이 1/2로 획기적으로 줄어든다. |
  |
attention layer를 반복한 뒤 나오는 feature x는 이제 score matrix로 바뀌어야 한다. (superglue의 matching descriptor와 같음) 근데 단순히 cosine similiarty로 계산하는 것이 아니라 MLP로 한 번 projection한 다음에 사용한다. (왜인지는 나와있지 않으나 아마 design search를 이리 저리 해보니 이게 제일 좋아서 그랬지 않을까 싶다.) 각각을 linear mapping한 뒤 similiarty를 계산한다. 추가적으로 linear mapping 된 feature에 sigmoid를 취하여 나오는 0~1 값은 matchability라고 정의했고 이는 feature가 matching에 관여할 것인지 안할 것인지 평가하는 값이다. 이 값이 낮을 경우 버려진다. 다시 말하면 matching descriptor를 matching feature(denormalized matchability) 로 바꾸고, matching feature로 score를 계산한다. 최종적으로 correspondence는 개별적으로 matchability도 높아야될 뿐만 아니라 모든 연결 관계를 고려한 score에서도 높아야 한다. |
 |
추가적으로 matching descriptor(linear mapping 전)을 입력으로 받아 이번엔 confidence를 예측하는 모듈을 추가했다. 어떻게 보면 matchability랑 동일한 개념 같은데 matchability는 수식(8)에 의해 update되므로 암묵적으로 연결 관계에 대한 신뢰도를 배우게 된다. 하지만 이 confidence 값은 어디까지나 matching descriptor만 갖고 이 point가 유효한 point인지 아닌지 candidate에 올라도 되는지 아닌지만 평가한다. 좀 더 point 단위에 집중한 신뢰도라고 할 수 있겠다. 더불어 이 값은 학습이 완료된 이후에 별도로 post processing으로 학습되는 기능이므로 point 단위의 신뢰도를 갖도록 강하게 학습된다. ----------- 이걸 추가하면 매 iteration마다 연산량이 늘어나니 속도 저하에 영향을 주는 것이 아니냐? 라고 할 수 있는데 이 confidence를 이용해 iteration 중단을 하거나 candidate 수를 줄이기 때문에 극단적으로 어려운 scene이 아니면 웬만해서 빨라진다고 한다. |
  |
 confidence 값이 존재하면, iteration 멈추기, point 솎아내기가 가능하다고 했다. 간단하게 hyper parameter lambda를 지정해서 confidence가 이것보다 낮을 경우 point를 솎아내고, 전체 평균을 냈을 때 일정 비율 이하로 내려오면 iteration을 중단한다. 여기서 hyper parameter는 iteration이 진행됨에 따라 낮아지도록 설정했다고 한다. 왜냐면 iteration 초반에는 confidence가 전반적으로 낮게 추정되는 경향이 있었기 때문이다. 그래서 자신없게 말할 때는 강한 기준선으로, 자신있게 말할 때는 덜 강한 기준선으로 걸러내서 신뢰도 높은 point만 골라냈다. |
 |
loss는 역시나 GT correspondence가 있기 때문에 superglue와 동일하게 correspondence에 대응되는 P matrix 값을 최대로 만들도록 구성되어 있다. 추가적으로 match가 존재하지 않는 keypoint의 경우, matchability를 0으로 만들도록 강제했다. 나머지는 자동학습 되는 듯? ---- confidence 계산하는 MLP의 경우, 앞선 학습이 완료된 이후에 별도로 학습된다. freeze된 상태에서 이 MLP만 학습한다. 학습 loss는 매 iteration마다 같은 keypoint 에 대해 confidence를 계산하고 이들끼리 서로 같도록 강제했다. 의미를 보면, matching descriptor (noisy할 때부터 정확할 때까지) 를 보고 항상 강건한 point confidence를 내뱉도록 하는 것이다. 이 confidence를 이용해 filtering 한 뒤 발생하는 loss(11)이 수렴을 더 도와준다. |
  |
1) absolute PE << rotary PE 2) matchabitliy 추가하면 score의 역할 부담이 줄어듦 3) sinkhorn 연산량이 줄어듦. |
  |
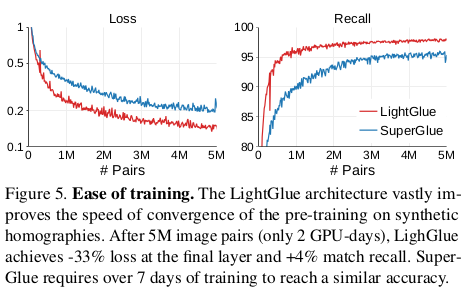 1) homography augmentation으로 사전학습 2) depthmap, camera pose, epipolar constraint 이용해서 데이터 추가 정제 3) feature dimension은 256이 좋았음 (꽤 크네...) |
  |
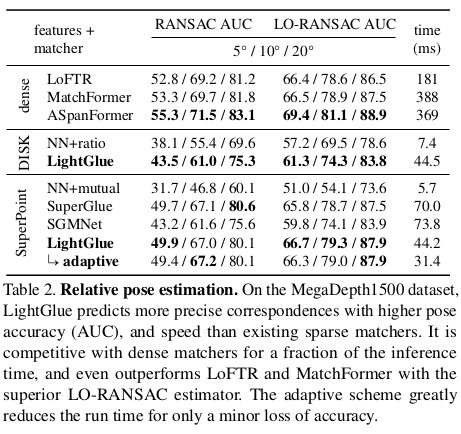  |
 |
 |
 |
 |
 |
 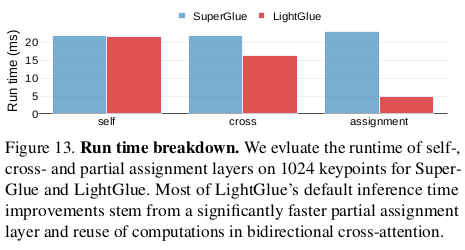 |
반응형