반응형
내 맘대로 Introduction
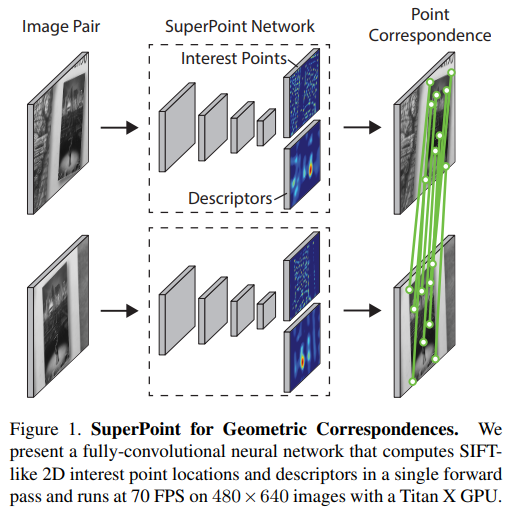
keypoint detector 중 가장 유명한 논문이 아닐까 싶다. 유명한 만큼 성능도 준수하고 직관적이다. 나온지 꽤 된 논문이긴 하지만 여전히 잘 쓰이고 있는 논문이고 superglue, lightglue 등 시리즈 논문들도 준수하기 때문에 읽어두면 좋을 기초 논문이다.
핵심 아이디어는 우리가 keypoint라고 하면 떠올리는 corner, edge 위주로 만든 synthetic dataset으로 학습을 시켜 일반 이미지에 적용할 수 있도록 확장하는 방법이다. 즉, synthetic simple dataset으로 학습시켜서 generalized keypoint detector를 만드는 논문이다.
흐름은 fully synthetic training으로 MagicPoint 먼저 만들고 이를 self-supervised로 대량의 일반 이미지에 튜닝하여 SuperPoint로 만드는 순서다.
메모하며 읽기
 |
|
 |
 기본적으로 detector는 fully conv. network이고 keypoint head, descriptor head 두 개를 갖고 있다. head에 입력으로 들어가는 부분은 shared feature다. |
  |
encoder 즉, keypoint head와 descriptor head의 입력 feature를 만드는 부분은 간다히 VGG 유사 구조다. 최종적으로 H/8, W/8 feature를 만들어 낸다. ----- keypoint head, (interest point decoder)의 경우 이 H/8, W/8 feature를 한 번의 conv. 를 통해 channel 수를 65로 바꾼다. 65인 이유는 1/8 x 1/8로 줄어든 해상도에서 온 것인데 upsample로 원본 해상도 H, W로 돌아가는 것이 아니라 channel을 가져와서 H, W로 돌아가기 때문이다. 8x8+ 1로 65다. +1은 dustbin이라고 하는데 그 의미를 해석해보길, 뒷 단에 softmax에 같이 들어가서 8x8 patch가 keypoint probability를 확실하게 갖고 있는지 아닌지 도와주는 역할 같다. 가령 8x8 patch 하나에서 keypoint가 나와선 안된다면 64개 bin에서 값이 어쩌다가 나왔더라도 dustbin 값이 커져서 softmax 시 64 bin을 억제 할 수 있을 것이다. ----------- descriptor head도 큰 차이 없으나 H/8, W/8을 dimension만 D로 바꾼뒤 이 번엔 bilinear upsampling으로 원본 해상도를 맞춘다. 여기서 D는 descriptor dimension으로 128쓰는 것 같다. |
  |
loss는 직관적이다. keypoint head loss의 경우, edge나 corner point 위치를 GT로 갖고 있기 때문에 해당 위치의 probability를 1로 만드는 Cross entropy loss다. descriptor loss의 경우, 결국 cosine similarity를 사용했다. GT homography(synthetic data라 있음) 를 이용해 대략의 correspondence 범위를 8 pixel로 한정한 뒤 후보군을 추려서, cosine similarity loss를 준다. 0 과 1로 극단적으로 주진 않고 margin을 약간 주어서 사용했고, correspondence 범위 내면 비슷하도록, 밖이면 밀어내도록 했다. |
 |
|
  |
synthetic dataset은 그림과 같이 생겼다. 단순한 도형들을 무수히 많은 자유도로 augmentation한 뒤, 그 keypoint를 찾도록 학습시켰다. generalization이 되나?? 싶은데 실제로 꽤나 잘된다고 한다. |
   |
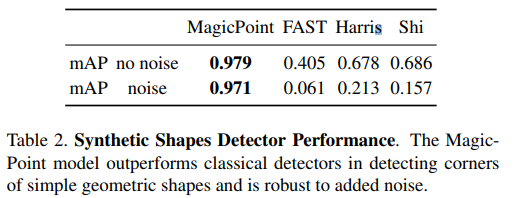 fully synthetic data로만 학습한 이 상태를 magic point라고 불렀는데 생각보다 잘돼서 놀랐고 일반 이미지에서도 웬만치 돌아간다고 했다. 단순 형상에 한해서 |
 |
|
  |
이제 실제 데이터를 활용해서 generalization에 초점을 맞춘 self-supervised 학습 방법을 적용한다. 그 방버은 homographic adaptation이라고 불리는 방법인데, 내용은 간단하다. 주어진 일반 이미지를 무작위로 N개 형태로 homography를 적용한다. 그리고 각각에서 keypoint detection (heatmap)을 한 뒤 다시 un-homography를 적용해서 한 곳으로 모아 다 합친 것을 GT로 쓰는 것이다. 직관적으로 말하면 주어진 이미지를 요리 보고 조리 봐서 못봤던 keypoint를 찾아내고, 처음 볼 때부터 그런 keypoint까지 한번에 찾아내도록 loss를 가해주는 것이다. 잘될까? 싶지만 전제 조건으로 magic point가 상당히 정확하게 corner를 잡아내주도록 학습이 되어있었다면 의미가 있을 것 같다. 어떤 loss로 학습을 시켰는지 디테일이 잘 안나와있는데 그냥 막했나 보다. |
  |
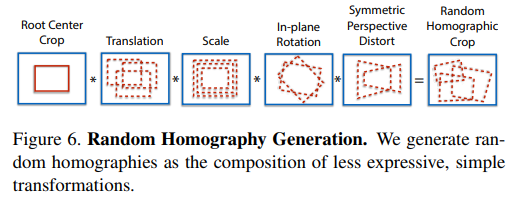 homogrpahy adaption 중간에 껴있는 N개를 형성하느 자유도는 완전 무한은 아니고 위와 같이 몇가지로 제한했다. (중요하진 않은 듯) |
  |
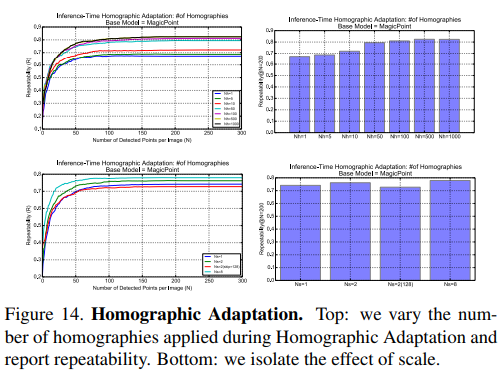
 homography adaptation은 컨셉 상 몇 번을 반복해도 가능하기 때문에 실제로 2번 반복했다고 한다. |
 |
|
 |
 |
  |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| LightGlue: Local Feature Matching at Light Speed (0) | 2023.11.06 |
|---|---|
| SuperGlue: Learning Feature Matching with Graph Neural Networks (0) | 2023.11.05 |
| 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering (0) | 2023.11.03 |
| Detector-Free Structure from Motion (0) | 2023.11.02 |
| DeDoDe: Detect, Don’t Describe — Describe, Don’t Detectfor Local Feature Matching (0) | 2023.11.02 |