반응형
내 맘대로 Introduction

바로 나올 것 같았다. 3D gaussian의 dynamic scene버전이다. NeRF에서도 time 축을 추가해서 dynamic NeRF가 바로 한 흐름을 가져갔는데 이것도 같은 컨셉을 3D gaussian splatting에 추가한 논문이다. 아이디어의 novelty는 그저 그런 편인 것 같고, deformation field를 구현할 때 그냥 3D grid 쓰는 것이 아니라 TensoRF처럼 6개의 평면으로 구현해서 연산량을 줄였단 것 정도가 자체 contribution으로 보인다.
deformation field를 Hexplane으로 표현하더라도 결국 특정 voxel 공간을 잡고 시작하는 것인데, 3D gaussian splatting 자체가 열린 공간에 대한 표현력을 자유롭게 가질 수 있는 알고리즘이기에 뭔가 모순적인 접근 방법 같긴 하다. 열린 공간 표현력을 굳이 다시 닫힌 공간으로 가져오는....? 다른 방법이 있을 것 같은데 NeRF 아이디어를 그대로 가져오는 것을 우선 시 한것 같아 아쉽다.
결과는 훌륭하다 어쨌든
메모하며 읽기
  |
 |
| 파생-짬뽕 논문이 그렇 듯, 핵심 래퍼런스 논문 내용으로 칸 채우기 한 번 해줬다. | |
 |
|
   |
 일단 3d gaussian이 time stamp마다 어떤 deformation을 해야 하는지 표현하는 deformation field는 NeRF에서 나온 개념인데, 3D gs에 적용하기 더 적합한 구조라는 점을 짚어준다. 위 그림에서 보다시피 defomration field를 이용해 canonical-to-reference mapping을 하면 ray가 어떻게 휘어야 되는지 표현되었었는데, discrete point들로 하여금 continuous ray를 휘도록 네트워크가 배워야 하므로 난이도가 높다. 하지만 3d gs의 경우, 정말 직관적으로 discrete 3d gaussian을 discrete 하게 옮기면 끝이다. 그래서 난이도가 더 낮다고 한다. 3d gaussian 마다 time stamp에 따라 position, scale, rotation residual을 계산하도록 하면 끝이란 소리다. |
  |
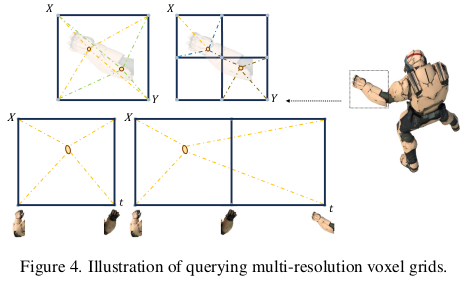 deformation field는 보통 feature grid + MLP로 구성하는데 일단 multi-resolution feature grid + MLP로 확장하는 것에서 더 나아가 multi-resolution grid를 multi-resolution orthogonal planes으로 분리했다. 내가 볼땐 연산량 때문인 것 같다. 3d gaussian의 position과 time stamp를 갖고 각 plane에서 feature를 읽어와 MLP로 decoding 하여 residual들을 계산한다. 학습을 뺑뺑이 돌다 보면 3d gaussian 위치가 canonical space에서 잡힘과 동시에 canonical-to-reference에 대한 정보가 이 plane들에 기록되는 것이다. -------------------- 하나 여기서 중요한 것이 canonical space에 존재하는 3d gaussian을 scale과 rotation을 추정하지 않는다. 왜 그랬냐면 학습이 완료되면 어차피 작은 3d gaussian이 엄청 생기기 때문에 사실 scale 차이가 무의미해보인다는 것이다. 괜히 학습 난이도를 높이기보다 scale, rotation은 timestamp에 묶어 residual로 커버한다는 접근을 한 것 같다. canonical space는 최대한 단순하게 찾고 변형에서 나머지를 커버한다는 컨셉. |
 |
그래서 canonical space 3D gaussian에는 scale, rotation이 없지만 (0이겠지?) residual이 나오면 이걸 더해줘서 3d gaussian at time t는 scale과 rotation이 있다. |
 |
|
 |
논문을 읽으면서 이거 canonical space 먼저 초기화 잘해주지 않으면 절대 수렴 안 할 것 같다는 걱정이 들었는데.. 역시였다. 그래서 canonical space를 먼저 조금이라도 잡아주기 위해 deformation field는 고정해두고 주어진 video frame들을 넣고 일단 static 3d gs를 돌려준다. 이렇게 하면 동적 물체에 대한 영역은 복원이 망할테지만, 적어도 정적 물체 혹은 배경은 상당히 잘 초기화 될 것이고, 모션만 크지 않다면 동적 물체도 대충을 위치를 잡을 수 있을 것 같다. 이렇게 한 3000번 정도 돌리고 나서는 모든 gradient를 켜고 한 번에 최적화를 돌린다. loss를 rendering loss가 주다. TV Loss는 image smoothness loss라고도 불리는데 그냥 image[1:, :, :] - image[:-1, :, :] 과 같이 한 칸 shift한 이미지와 차이를 줄이는 식의 helper loss다. |
 |
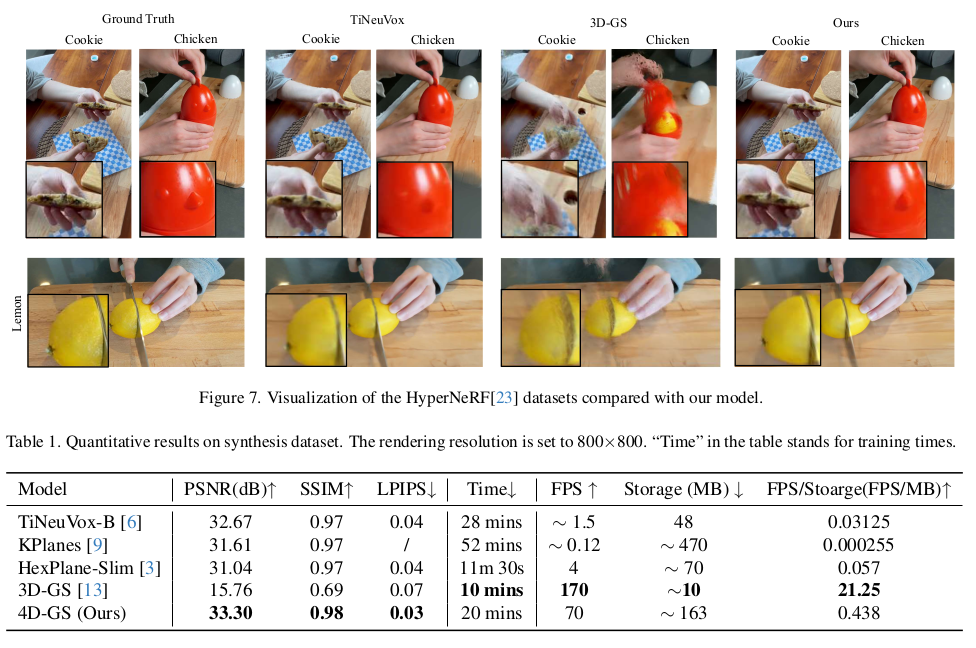 |
 |
|
 |
 |
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| SuperGlue: Learning Feature Matching with Graph Neural Networks (0) | 2023.11.05 |
|---|---|
| SuperPoint: Self-Supervised Interest Point Detection and Description (0) | 2023.11.05 |
| Detector-Free Structure from Motion (0) | 2023.11.02 |
| DeDoDe: Detect, Don’t Describe — Describe, Don’t Detectfor Local Feature Matching (0) | 2023.11.02 |
| 3D Gaussian Splatting for Real-Time Radiance Field Rendering (0) | 2023.11.02 |