반응형
내 맘대로 Introduction

이 논문은 keypoint-descriptor를 기반으로 한 SfM 파이프라인을 dense matching 네트워크 기반으로 변경한 논문이다. dense matching 논문이 matching 관점에서는 keypoint 뽑고 descriptor 갖고 matching하는 것의 성능을 넘어선지 오래지만 feature track을 형성하기 어렵다는 이유로 SfM 분야까지 넘어오진 못했다. 이 논문은 처음으로 dense matching으로 SfM을 돌려보고자 했다.

dense matching은 일단 2장의 이미지를 pair로 받아야 돌아가는 네트워크다 보니까 A-B에서 matching된 결과와 B-C에서 matching된 결과를 보고 A-C matching 결과를 예측하기가 어렵다. feature track 형성하기 어렵단 소리다. 게다가 dense matching 알고리즘들 (여기선 LoFTR 말하는 것 같다. 동일저자니까) 은 coarse-to-fine matching을 하는데 coarse한 과정이 끼면 discretization 이슈가 있기 때문에 난이도가 더 높아진다.
이 논문의 핵심 아이디어는 일단 전부 다 coarse 레벨에서 일단 하고 대충 완성한 뒤에 fine 레벨로 올리는 건 다른 네트워크 써서 하겠다는 컨셉이다. 일단 첫 초기화할 때는 coarse-to-fine 중 coarse만 이용하고 fine은 나중에 보정함으로써 달성한다는 구분 전략이다.
메모하며 읽기
 |
|
 |
일단 전부 다 coarse 레벨에서 matching하고 (coarse하니까 대충 matching이 쉬워짐) SfM기존 하듯이 incremental하게 해서 초기하 한다. 그리고 뒤에 네트워크 하나 붙여서 iterative refinement한다는 컨셉 |
 |
일단 dense matching에서 confidence를 이용해 keypoint와 같이 dominant pixel을 찾아 사용한다. 그 pixel의 continuous u,v 좌표계를 discretization하고, 1/8 스케일로 줄임으로써 coarse keypoint를 만든다. 그 다음부터는 Incremental 하게 two view initialization부터 시작해서 하나씩 registration하면서 모든 프레임을 돌고 멈춘다. 이렇게 하면 성능 저하는 당연히 있는데 대충 쓸만한 초기값을 얻을 순 있다고 한다. (naive하게 일단 한다는 이야기.) |
 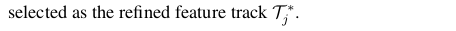 |
 핵심은 뒷부분인데 coarse로 얻은 camera pose와 3d point를 점점 정확하게 업데이트하는 방법이다. 3d point 하나를 잡고 초기화에서 얻은 track을 따라 각 이미지로 projection한 뒤, 해당 위치에서 패치들을 긁어모은다. p x p로. 각각 patch를 작은 CNN을 통과시켜 intial feature화 하고 이를 transformer로 encoding해서 최종 feature화 한다. query feature patch에서 pixel 하나씩 잡고 모든 reference feature patches에 similarity를 구해서 가장 값도 크고 variance가 높은 조합을 찾아내서 업데이트 하는 방식이다. 다시 말해 coarse point 주변을 patch 단위로 탐색해서 미세 보정하는 작업을 계속 반복하는 것이다. ---- 이 과정의 의의는 3d point와 camera pose를 어느 정도 보정해주는 것에도 의미가 있지만 초기화 때 버려진 keypoint matching을 추가할 수도, 버릴 수도 있는 작업을 동시에 하는 것이다. |
  |
과정의 디테일을 좀 짚어보면, 먼저 뭘 query로 쓰고 뭘 reference로 쓸 것이냐. query는 일단 모든 reference와 비교했을 때 유의미한 매칭이 많이 나올 확률이 가장 높아야 좋다. 이를 조금이라도 반영하기 위해서 저자들은 scale을 썼다. 직관적으로, 물체를 보았을 때 가까운 이미지부터 먼 이미지가 있다면 중간 거리에서 찍은 이미지가 close to far 모두 매칭이 잘될 확률이 높을 것이다. 따라서 주어진 이미지 중 keypoint depth를 추정해보았을 때 cam to point 거리가 전체 경우의 수 중 median인 이미지를 query 이미지로 정했다. |
 |
 네트워크 구조 설명인데 특별한 것 없이 shallow CNN + transfomer다. |
 |
학습이 필요한 부분은 MVF Transformer 하나다. 이걸 주어진 이미지셋에 대해서 학습시키는 것은 말이 안되니 megadepth를 이용해 사전학습시켜두는 방식으로 사용한다. |
  |
앞서 feature track refinement가 camera pose와 3d point를 업데이트 해주는 것이 맞지만 사실 BA처럼 전체적으로 큰 틀에서 잡아주는 loss가 존재해야 하는 것은 맞다. feature track refinement의 업데이트가 더 부정확한 방향일수도 있고, 추가된 feature가 outlier일수도 있기 때문이다. 따라서 여기서 BA처럼 지금 갖고 있는 모든 파라미터를 다 때려박아서 reprojection error를 최소화하는 loss를 넣어줘서 한 번 더 업데이트 한다. 실제 학습에서는 feature track refinement 한 번, geometric refinement 한 번 번갈아가면서 했다고 한다. |
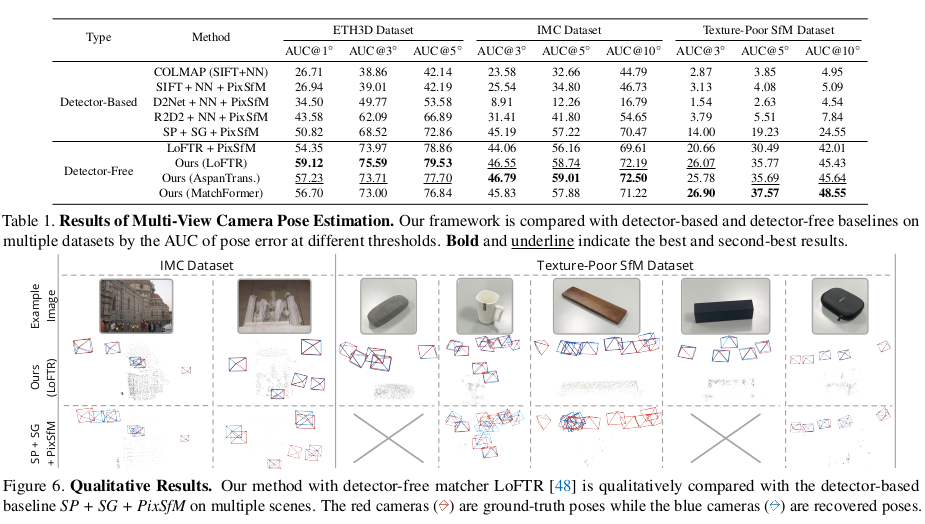 |
|
 |
 |
 |
 확실히 dense matching이 texture-less region에서도 잘 뽑아주다 보니 타겟 물체의 자유도도 많이 올라간 것 같다. |
반응형