반응형
내 맘대로 Introduction
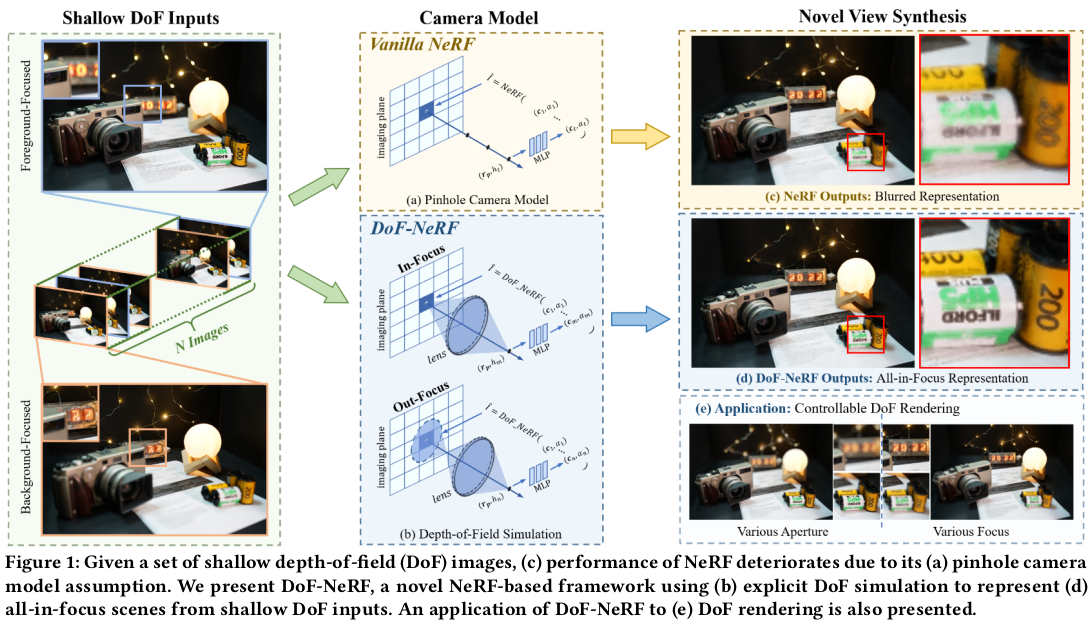
Depth of field NeRF라는 이름을 보면 단번에 알 수 있듯이, 카메라로 취득한 이미지라면 초점이 반드시 존재하는데 이 초점을 고려해서 NeRF를 학습시키는 방법을 소개한다. 기존 NeRF에서는 이미지의 모든 픽셀이 초점이 맞는 상태를 가정하는데 이 상황은 피사체가 depth of field 내에 들어와있다는 가정이다. 하지만 근거리부터 장거리가 모두 포함된 scene이나 피사체를 찍을 경우 depth of field를 벗어난 경우가 반드시 생기고 이 경우 성능 하락이 발생한다. 이 논문에서는 depth of field를 계산하고 이를 volume rendering 과정에 포함시켜서 이 문제를 해결한다.
화려한 논문은 아니어도 문제 정의가 좋고 방법론도 복잡하지 않아 좋은 논문 같다.
메모하며 읽기
 |
일단 시작은 각 이미지마다 DoF를 결정하는 aperture와 focus distance를 learnable parameter로 부여하는 것으로 시작한다. 학습 과정에서 이 두 파라미터가 학습될 경우, 이론 상 초점거리와 aperture를 바꾸어 가면서 다양한 DoF에 대한 이미지를 렌더링할 수 있게 된다. |
 |
|
 |
DoF를 NeRF에 학습시키기 위해서 2가지 개념을 사용한다. 1) (b)와 같이 한 pixel에 맺히는 빛은 ray의 여러 위치의 diffusion 값이 중첩된 값이다. 2) (c)와 같이 한 pixel에 맺히는 빛은 주변에서 넘어온 빛도 포함한다. 이 각각은 I_ray와 I_scatter로 나누어 모델링했다. --- 그 이론적 기반은 (4) (5) (6)과 같다. 요약하면 개념 1) 2)에서 빛이 퍼져나가거나 넘어오는 빛의 반경을 계산하는 방법인데 이는 렌즈까지의 거리, 초점거리, focal length로 계산할 수 있는 값이다. 퍼져나가는 빛의 세기는 CoC(circle of confusion) 안에서는 동일하다는 가정 하에 NeRF color 값과 엮어서 (6)과 같이 계산할 수 있다. CoC는 그림으로 보는 것이 편한데 아래 그림처럼 렌즈 굴절에 따라 빛이 한 픽셀에 안모아지는데 이 안모아지고 펼쳐지는 영역을 말한다. 이 영역이 넓을수록 이미지가 흐려진다. 초점이 나간다는 말. 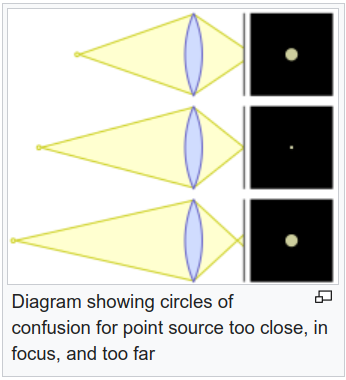 --- 이론적 기반을 이용해 개념 1) 2)를 수식으로 표현하면 (7) (8)과 같다. (7) 한 픽셀에 맺히는 값은 ray의 각 위치 h_i에서 각각 diffusion된 값의 합 (8) 한 픽셀에 맺힌 값은 주변 픽셀에서 넘어온 값의 합 (주변 픽셀은 각각 (7)로 계산이 되니까 이중적분이 필요함) |
 |
 |
   |
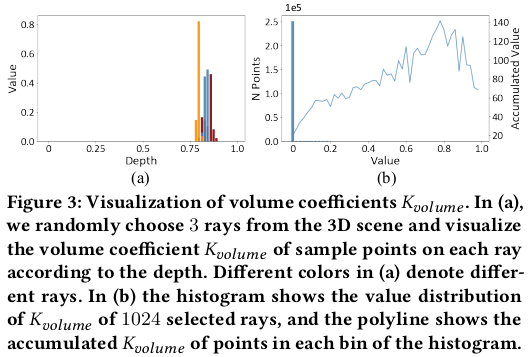
그런데 문제가 수식 (7) (8)을 그대로 사용하여 loss를 구현하기에는 연산량이 너무 많다는 것이다. (7)만 해도 각 위치 h_i마다 aperture diameter를 새로 계산해야하고 (8)은 (7)의 행위를 neighbor ray 개수만큼 반복한 뒤 또 적분해야 한다. 그래서 연산량을 줄이기 위해 관찰을 해보니, volume rendering에서 피사체의 빛을 결정하는 것은 형상 표면 근처 위주로 보면 된다는 것을 알 수 있다. 그림 (3)에서 표현한 것이 그 내용인데 ray 상의 무수히 많은 위치가 있지만 결국 특정 depth (표면 근처)에 몰려있다는 것을 알 수 있다. 따라서 전략을 세우길, 일단 표면 근처 위치만 보고 해당 위치들의 빛을 표면에 해당하는 h_i로 다 모으고, h_i에서 aperture diameter를 한 번만 계산한 뒤 모든 값을 h_i의 diameter로 흩뿌려준다. approximation하는 셈이다. 표면에서 먼 위치는 어차피 계산해본들 영향력이 없으니 말이다. 표면에 해당하는 h_i는 volume rendering에서 수식(10)과 같이 적분해서 간단히 얻을 수 있다. 모든 위치를 보아야하는 것은 표면 근처로 축소한 것 + 축소한 각 위치에서 diameter를 각각 계산해야되는 표면 위치로 퉁쳐서 한 번만 계산하는 것으로 연산을 줄인 것이다. |
 |
 ray selection도 약간 변화를 줘야한다. 왜냐하면 NeRF였으면 pinhole camera ray를 가정하니까 무작위 선별을 해도 되지만, DoF NeRF의 경우, 주변 픽셀에서 넘어오는 diffuse도 고려하기 때문에 ray를 뽑을 때 주변 끼리끼리 모아서 선별을 해주어야 한다. 근데 이걸 매 iteration마다 주변을 찾고 재배열하고 업데이트하면 느리니까 미리 N x N 구역으로 나누어두고 구역 센터만 ray로 뽑아서 학습을 했다고 한다. |
 |
근데 이렇게하면 예상되듯이 구역 센터 ray만 편향되게 사용하기 때문에 학습이 제대로 될리 만무하다. 실제로도 그랬는지 2 stage로 학습해서 극복했다고 한다. 첫번째 스테이지에서 그냥 기존 NeRF처럼 팽팽돌려서 학습해두고, 두번쨰 스테이지에서 learnable parameter다 활성화시키고 patch based ray sampling도 적용하면서 업데이트했다고 한다. |
 |
|
 |
 |
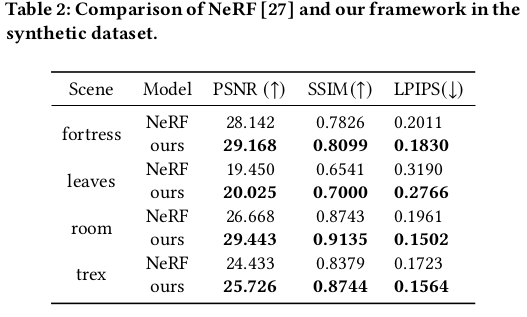 |
 |
 |
 |
|
 |
 |
반응형