반응형
내 맘대로 Introduction

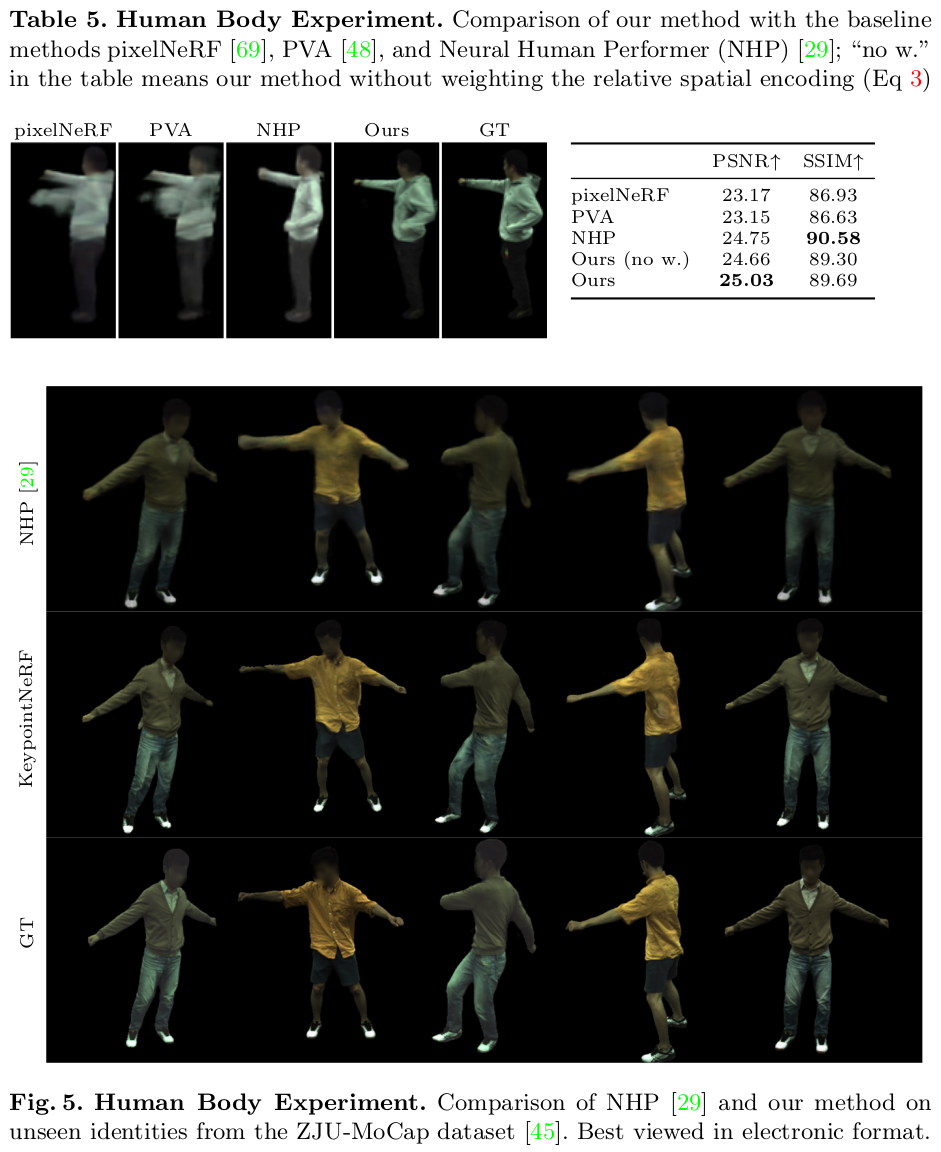
KeypointNeRF는 기존 NeRF에서 positional encoding을 global이 아닌 local하게 변경한 논문이다. 간단히 말해 anchor처럼 사용할 수 있는 3D point가 존재한다면 해당 point들 대비 상대적을 displacement를 positional encoding하는 식으로 사용하는 방법이다. 3D anchor point가 되는 point들은 어디서든 찾을 수 있지만 human keypoint에 대한 연구가 워낙 활발하다보니 사람으로 테스트한 것 같다. 방법론 자체는 3D point가 주어졌을 때 항상 사용할 수 있는 방식이다.
메모하며 읽기
  |
| 전체 파이프라인은 1) 3D keypoint 얻기, 2) image feature 얻기 (pixelNeRF) 3) positional encoding하기 4)NeRF 학습시키기 이다. 적은 이미지가 주어졌을 때도 잘할 수 있도록 pixelNeRF 컨셉으로 image feature 기반 NeRF다. 내 생각으론 대상 사람 머리인 이상 형상이 워낙 단순하기 때문에 image feature를 쓰는게 효과가 더 좋을 것 같다. image feature는 geometry용, appreance용 총 2개를 뽑는다. |
  |
| 핵심인 local positional encoding은 주어진 3D point 마다 그냥 (x,y,z) 그대로 쓰는 것이 아니라 K개 주어진 keypoint들과의 3D 거리값과 2D 거리값을 사용했다. rellatvie depth difference에 해당하는 2D term이 핵심인 듯. |
 |
| 이 부분은 큰 내용이 없다. encoder를 2개 사용해서 각각 geometry, appreance feature를 뽑았다는 내용과 multiview pose가 있으니 3D point마다 image feature들을 모아 aggregation했다는 내용. |
  |
| 여기도 크게 특별한 점 없이 앞서 만든 feature를 이용해 NeRF를 학습시키는데, multiview consistency를 좀 더 강조하기 위해서 color를 바로 추정하는 것이 아니라 이미지 color를 가져와서 weighted sum하는 식으로 학습하되 그 weight를 추정하도록 했다. 네트워크가 어디서 어느 색을 얼만큼 뗘와야하는 학습하기 떄문에 multiview consistency가 조금 더 유지되는 경향이 있다. (이 논문 외에도 많이 언급하는 트릭) |
 |
| 사소하게 VGG loss를 추가해주는 것이 high frequency detail을 살리는데 도움이 된다고 한다. |
 |
 |
  |
 |
 |
 |
반응형