반응형
내 맘대로 Introduction
한 줄 요약하자면 아무것도 없고 비디오만 (혹은 연속된 이미지만) 잔뜩 있을 경우, NeRF를 어떻게 적용할 것인지 고민한 논문이다. SfM 돌리고 뭐 이럴 수 있지만 end-to-end로 딥러닝을 이용해서만 어떻게 할 수 있는지 방법을 소개한다. intrinsic parameters, camera poses, neural volume 3개를 전부 다 추정해서 사용하며, generalization이 되도록 하는 것도 목표다. 사실 상 그냥 다 때려넣었다. 그래서 optical flow, pixelNeRF, FoV 등 각종 네트워크가 덕지덕지 붙어있어서 조금 지저분하다.
개인적으로는 intrinsic parameter를 구하는 것을 추가한 것은 살짝 오버인 것 같고 카메라 포즈를 딥러닝으로 추정하는 것도 사실 굳이 풀어야하는 문제인가 싶다. classic하게 잘 풀리고 있는 문제 그리고 그닥 어렵지 않게 풀 수 있는 문제를 다시 어렵게 푸는 방법으로 풀려고 노력할 필욘없는 것 같다.
그리고 읽고 나서 든 생각이, optical flow를 카메라 포즈찾는 핵심으로 쓰는데 무조건 rigid scene만 가정하는 듯한 느낌이다. 동적 물체라든지 형상이 변하는 물체가 있으면 절대 동작하지 못할 구조다.
메모하며 읽기
  |
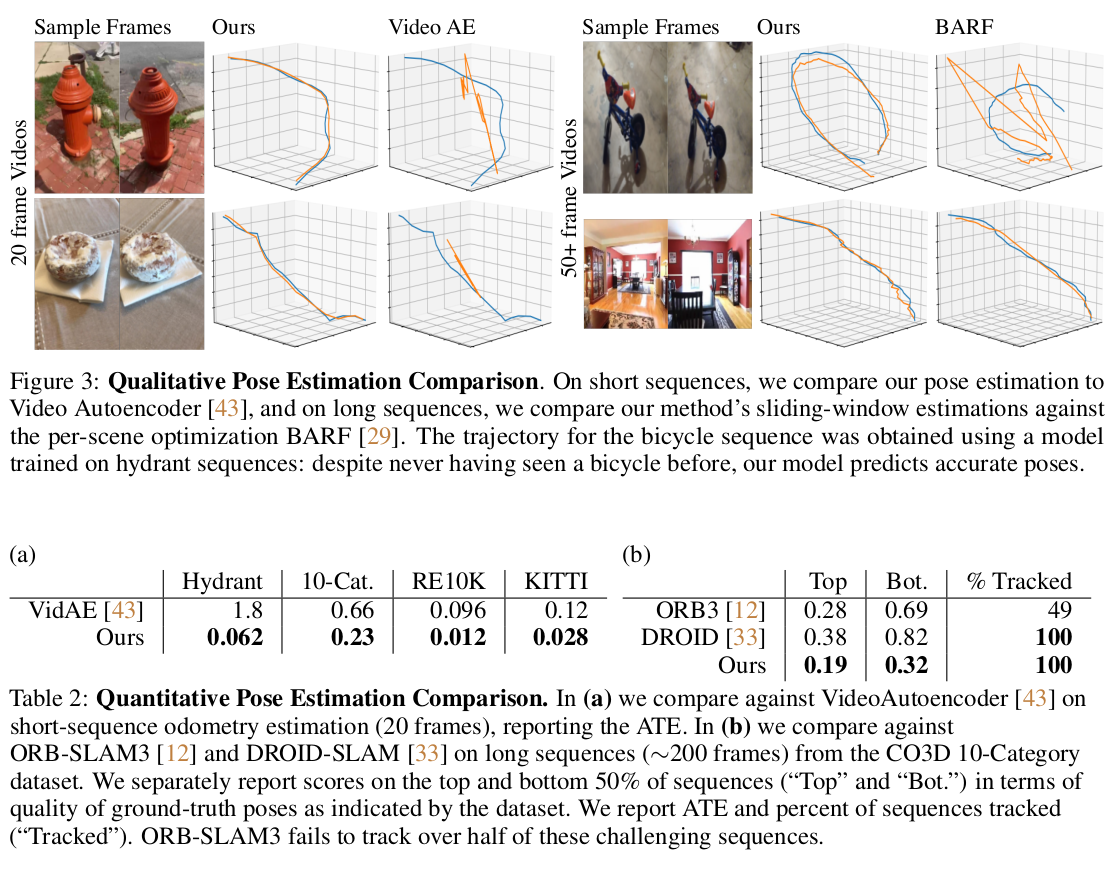
| 그림만 봐도 굉장히 복잡한데 조금 요약하면, 각 이미지마다 pixelNeRF로 3D point + color를 찾고 correspondence 매칭한 다음 predicted 3D point를 갖고 카메라 포즈를 역추정하는 구조다. pixelNeRF의 성능, 특히 generalization 성능에 전적으로 의존하는 구조다. correspondence를 찾는 과정 또한 optical flow SOTA 네트워크에 의존하기 때문에 불안한 면모가 많아 보인다. |
  |
| 이제는 안 나오면 섭섭한 NeRF 설명으로 공간 한 번 싹 채워주고, 마지막 줄에 띡 pixelNeRF 이용한다고 적어뒀다. pixelNeRF는 이미지 별 feature를 뽑아주는 부분, feature to color, volume density로 올려주는 부분으로 나누어져있는 네트워크다. feature의 힘을 믿고 적은 이미지로 NeRF를 학습시킬 수 있다고 소개한 논문이다. |
  |
| 카메라 포즈를 찾는 내용이다. 일단 연속된 이미지 2장씩 묶어서 RAFT를 통과시켜 optical flow를 얻어낸다. 그리고 optical flow로 correspondence들을 생성한 뒤 해당하는 pixel들을 pixelNeRF를 통과시켜 3D로 올린다. 3D로 올리는 디테일은 Eq.2 보라고 하는데 ray 별로 sample point 여러개 만들고 pixelNeRF 태워서 전부 volume density 계산한 뒤, 적분해서 depth로 바꾸는 식일 것이다. 3D correspondence가 (정확성이야 어찌됐든) 얻어졌으면 상대적 rigid transformation을 푸는 것은 쉬운 문제가 된다. 뒤에 설명 더 나온다. 여기서 2D to 3D 디테일은, 2D correspondence를 믿고 쓰기가 조금 불안하긴 했는지 네트워크 하나 붙여서 correspondence에 대응되는 pixelNeRF feature를 보고 confidence를 추정하도록 해서 활용했다. (이게 맞나... 추정값으로 추정값을 구한다...?) 마지막 intrinsic은 FoV 계산해주는 네트워크 통과시켜서 FoV 값 얻고 focal length로 역계산해서 썼다. (불안하다...) |
 |
| 이미지 별 3D correspondence를 갖고 reprojection error minimization 문제를 풀면 카메라 포즈가 나온다. 이 때 그냥 풀어도 되지만 앞서 confidence를 한 번 뽑긴 했으니 여기서도 갖다 붙여서 풀어줬다. 이 문제는 그냥 SVD로도 풀리는 것이니 굳이 설명할 필요없어 보인다. |
  |
| 학습시킨 loss다. 먼저 color loss 다른 말로 photometric loss인데, 시점이 여러개 있긴 하니까 multi로 color loss를 거는 것은 당연하고 (multi context loss), pixelNeRF가 단일 시점에서도 좋은 성능으로 돌아줘야 성공하는 파이프라인이다 보니 단일 시점으로도 color loss를 걸어주었따. (single context loss) pose induced flow loss는 optical flow로 pose 계산했는데 지금 3D point와 pose를 알고 있으면 역으로 optical flow를 계산할 수 있기 때문에 optical flow level에서 supervision을 제공해주는 것이다. 사실 상 RAFT optical flow가 GT처럼 쓰이기 때문에 RAFT가 정확도의 상한선인 느낌이다. |
  |
| 실제 활용하고자 할 때는 약간의 트릭이 필요하다. 학습 여건 상 엄청나게 많은 프레임을 사용하지 못하는데 비디오를 처리하려면 엄청나게 많은 프레임을 처리해야만 한다. 따라서 이를 다루기 위해서 슬라이딩 윈도우처럼 15 프레임 정도씩 끊어서 처리했다고 했다고 한다. 또한 generalization이 잘되는 것을 목표로 했지만 아쉬운 것은 당연한 사실이라서 비디오마다 finetune을 조금 돌려주면 더 잘 된다. BARF와 차별점이라고 주장하는게 조금 웃기긴 하지만 모델의 Weight가 바뀌는 것이라서 bundle adjustment처럼 global하게 맞추는 finetune하고는 다르다고 한다; |
 |
 |
 |
 |
 |
 |
반응형