반응형
내 맘대로 Introduction
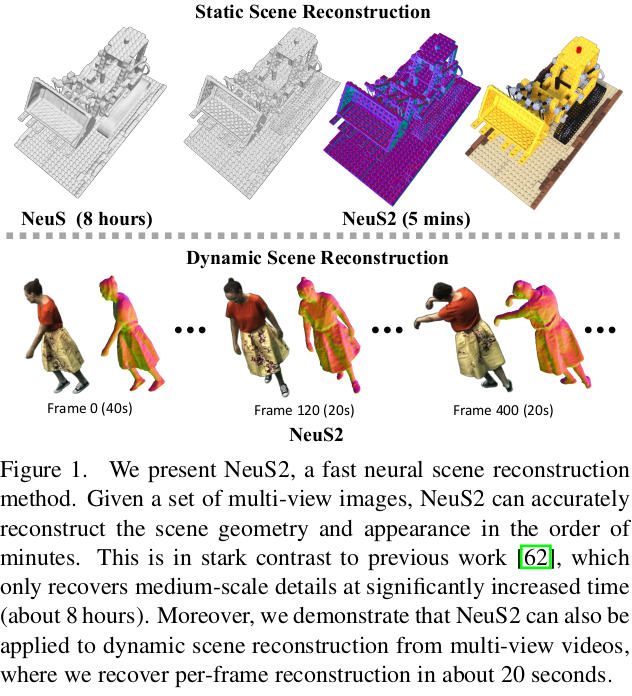
이 논문은 InstantNSR와 같이 SDF based NeRF + InstantNGP를 합친 논문이다. hash table + 2nd order derivative를 구현한 내용이 주기 때문에 부족해보이는 contribution 마저 InstantNSR과 같이 비디오에서 빠르게 하는 방법으로 정했다. NeuS2로 봄과 동시에 InstantNSR2로 보아도 큰 차이가 없다. 보다 나은 점은 더 간결하게 구현했다는 점과 성능이 있겠다.
메모하며 읽기
 |
|
  |
Static한 경우는 InstantNSR과 같이 크게 언급할 내용이 없다. 데이터 구조를 hash table 사용하는 방식으로 변경했다는 내용임으로 그냥 칸 채우기에 불과하다. Neus + InstantNGP recap에 해당함. |
   |
pytorch 에서 2nd order derivative 계산을 지원하지만 느린 점 + has table 구조에서는 사용할 수 없다는 점 때문에 직접 CUDA로 구현했다. 수식(5)와 수식(6)과 같이 전개가 되는데 이를 ReLU activation 했을 때만은 가정해서 단순화했다. (ReLU가 가장 간단해서 가능했던 것 같음) 수식(9) (10)까지 정리했다. 저걸 CUDA로 구현했다. |
 |
positional encoding이 low frequency부터 high frequency까지 점진적으로 포함하도록 하는 것인데 Nerfies에서 사용했던 방식과 동일하다. 새로 나온 것은 아님. 근데 래퍼런스가 안 달려있음. 이런 식으로 하면 네트워크가 low frequency부터 배워나가고 inductive bias가 줄어들기 때문에 수렴이 잘된다는 것이 밝혀져 있다. |
  |
비디오 처럼 같은 대상인데 약간의 움직임이 쌓여있는 경우, 이전 프레임에서 학습해둔 네트워크를 가져와서 fine tuning하는 식으로 하면 빠르다. (InstantNSR에서도 이런 컨셉을 쓰긴 함) 근데 InstantNSR에서는 deformation network니 뭐니 이것저것 붙여서 프레임워크가 거대해진 것이 문제지만 여기서는 크게 추가하는 것 없이 fine tune에 집중한다. |
  |
상대적인 모션이 클 경우, 이전 프레임 값을 가져왔을 때 local minima에 빠지는 문제가 관찰됐었고 최소한으로 모션을 커버하기 위한 SE3 matrix 정도는 필요했다고 한다. 큰 모션이라는게 보면 몸통이 돌아가거나 바라보는 방향이 아예 달라지는 정도의 변화인 것 같다. 이를 계산하는건 any given 3D position, x라는 걸 보니 네트워크로 하는 것이 아니라 프레임마다 3D point가 주어져 있어야 한다. 즉, 사전에 SfM이든 뭐든 3D point 몇개를 구해둬야하고 correspondence도 어느 정도 되어있어야 한단 소리 추측컨대, 3D point를 body joint로 구하기 쉬운 사람을 일부러 대상으로 고른 것 같다. SE3가 계산되면 대략 inv(SE3)로 돌려주고 fine tune한다. 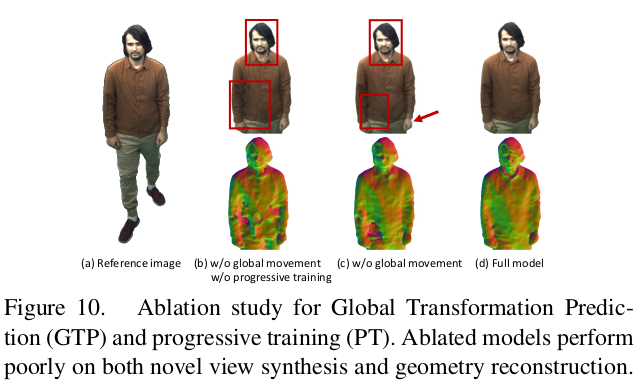 이거 없을 경우, 위 사진처럼 구멍이 자꾸 패임 |
 |
  |
 |
|
 |
 |
 |
 |
 |
반응형