반응형
내 맘대로 Introduction

이 논문은 single image to 3D 논문 (EG3D 같은 논문)을 확장하여 text to 3D까지 나아가는 논문이다. 기존 single image to 3D가 D GAN을 썼던 부분을 diffusion+NeRF로 대체함과 동시에 single image 조차 text에서 만들어내는 방식이다. 요즘 핫하다는 것은 다 갖다붙여본 논문이다.
핵심은 ImageGen이라는 text to single image diffusion model을 고정해두고 NeRF MLP가 만들어낸 이미지가 diffusion model 결과와 갖도록 NeRF MLP를 학습해주는 것이다. NeRF의 입력 이미지를 diffusion model로 만들어낸 것을 사용한다는 컨셉이다. 그러므로 text가 새로 주어지면 새 NeRF를 학습시켜야하므로 속도는 엄청 느리다고 할 수 있다. 일반화도 없다.
메모하며 읽기
  |
| 이 부분은 diffusion process에 대한 리마인드라고 보아도 된다. 수식(1)까지 전개되는 과정은 stable diffusion 논문에 자세히 나와있다. 요점은 stable diffusion 수식 그대로 사용할 것이고 reverse process의 p()를 사용할 것이다. |
  |
| Differentiable image parameterization, DIP라고 이미지가 주어졌을 때 이를 생성하는 네트워크의 파라미터를 역 추정하는 과정이 필요하다. 왜냐면 diffusion model을 고정해두고 diffusion model이 생성한 이미지와 유사한 이미지를 생성하도록 NeRF를 학습함으로써 3D 결과물을 추정해낼 것이기 때문이다. 생성된 이미지에 알맞는 NeRF의 파라미터를 추정해야만 한다. 그래서 diffusion model + NeRF까지 붙였을 때 image-to-NeRF gradient를 따져보면 수식 (2)와 같이 구성될 수 있는데 저자들이 실험을 해보니 수식(3)과 같이 특정 term을 삭제한 것이 더 효과적이었다고 한다. 최종 정리하면 수식(4)까지 정리할 수 있다. 이러한 꼴의 gradient를 SDS loss라고 명명하고 이 논문에서는 학습에 사용했다. diffusion model을 고정되어 있다는 것을 잊지 말자. 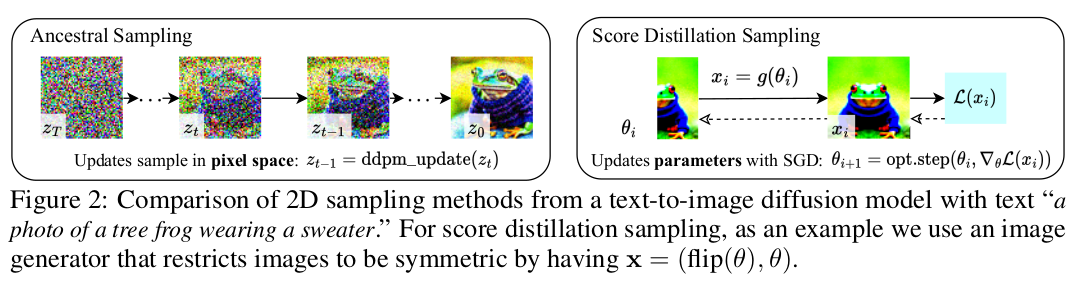 이 방식을 NeRF 대신 간단한 2D image generation model에 테스트해보았을 때 성능이 잘 나오는 것으로 검증도 했다. |
  |
| (그림이 복잡한데 위 공작은 처음부터 선명하지 않다. 학습이 진행되면서 3D volume 공간 내에 점점 선명해지는 것이다. 그림 상 처음부터 완벽해보이는 것.) 우측에 보이는 Imagen이 diffusion model conditioned by text 인데 이를 고정해두고 좌측의 NeRF로부터 이미지를 얻고 (처음엔 쓰레기 이미지) Imagen가 reverse process를 통과시켜 최종 이미지를 얻을 수 있도록 학습한다. NeRF에서 합리적인 noisy image가 나와줘야 Imagen이 보정을 하기 때문에 이를 많이 반복하면 NeRF가 어렴풋이 학습된다. |
  |
| NeRF의 개념에 대한 전반적인 리마인드와 함께 다양한 빛에 반응하는 3D를 만들기 위해 변경한 점들을 소개한다. 3D를 얻을 때 그냥 학습시키면 조명까지 반영한 색을 통째로 학습하는데 이를 막기 위해 albedo를 추정하도록 했고 빛은 따로 주어진다고 가정했다. 수식(6)처럼 color 대신 albedo가 나오도록, 수식(7)처럼 그냥 color 대신 주어진 light들의 조합으로 color를 얻도록 했다. |
 |
| 생성하고자 하는 3D의 제한은 사실 없다만 실험적으로 sphere로 감쌀 수 있을 정도의 형상들이 잘되었다는 결과가 있다. 추가로 형상 복원시 구름같은 노이즈들을 없애기 위해서 Ref-NeRF에서 썼다는 regularization을 추가했다. 이게 뭐냐면, 카메라에 충분히 가까운 위치 (multiview camera setting에서도 잘 안찍힐만한 위치)에서는 volume density를 낮게 추정하도록 하는 regularization이다. |
  |
| 전체 과정을 다시 보면 총 4단계다. 1) 일단 NeRF에 넣어줄 카메라 위치랑 빛 무작위 초기화 2) NeRF rendering 3) SDS loss로 parameter update 4) 반복 1)에서는 카메라의 무작위 초기화 범위를 조금 제한해주는 것이 필요하고 2)에서는 특별한 것은 없다. 3)은 경험적인 것인데 diffusion model 에서 이미지를 생성할 때 NeRF에 던져준 카메라 위치를 묘사하는 단어를 추가해주면 조금 더 잘 된다고 한다. 4) 반복학습 시에 TPU로 1.5시간 걸렸다. |
 |
 |
 |
| camera 위치를 대략 묘사하는 prompt를 넣었을 때 더 좋은 것을 비교해본 자료 |
반응형