반응형
내 맘대로 Introduction
이 논문은 NeRF로 이미 복원한 scene에서 선택적으로 특정 물체를 지우는 방법에 대해 생각한 논문이다. NeRF MLP가 implicit function이 un-interpretable이기 때문에 이미 학습 완료된 scene에서 특정 물체만 분리해낸다는 생각 자체가 사실 불가능한 것이라 이론적으로 풀진 않았고, 파이프라인으로 풀었다.
입력 이미지가 주어졌을 때 제거하고자 하는 물체를 모든 이미지에 대해서 마스킹한 뒤, NeRF를 다시 학습시키는 방법이다. 이 때 단순 마스킹할 경우 당연히 망가질 것이기 때문에 2d inpainting 알고리즘으로 빈 mask 영역을 채워서 복원한다.
개인적으로 task를 풀기 위해 이것저것 섞은 조립형 논문이라서 그렇게 매력적으로 보이진 않는다.
메모하며 읽기
 |
국룰. NeRF recap. |
 |
|
  |
전체 파이프라인은 1) 입력 이미지에서 마스킹 2) inpainting 3) NeRF reconstruction 이다. ---- 웬만하면 1) 2) 3) 모든 과정을 SOTA를 가져와서 썼으므로 조립형 논문이다. 정말. |
 |
맨 처음 입력 이미지 별로 물체 마스크를 따는 것은 LLaMa를 사용했다. 약간의 guide(point)만 있으면 mask를 따주기 때문에 이를 이용해서 1장에서 물체 마스크를 딴다. 매 frame 해주기엔 너무 수량이 많이 드니까 또 video를 가정해서 mask를 tracking해주는 알고리즘을 붙여서 나머지 frame에서도 마스크를 따준다. 이러고 나서 NeRF를 빈공간 있는 채로 일단 학습을 시키는데 semantic NeRF 방식을 차용해서 mask region과 unmasked region이 구분되도록 학습한다. |
  |
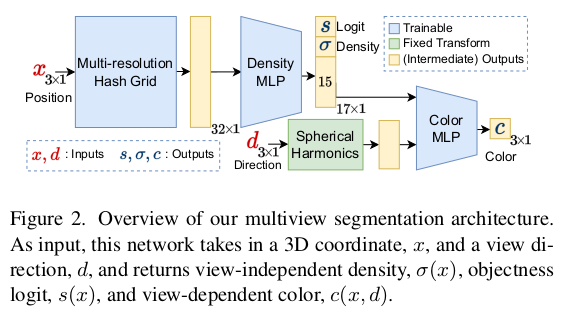 LLaMa + video tracking으로 딴 마스크는 3d consistent하지 않고 noisy하겠지만 NeRF 학습 과정에서 그래도 나름 multiview constraint에 의해 보정될 것이다. 따라서 학습 완료된 masked region을 각 이미지로 reproejction해서 updated mask를 얻는 것으로 최종 mask 확보를 마무리한다. ---- masked region을 구분하려고 새로 부여한 objectness는 sigmoid를 취해 0~1로 뽑아내는 값으로 masekd region이냐 아니냐만 구분하는 binary classification 용이다. ray 단위로 합쳐서 사용하므로 수식(3)을 보면 기존 color integral과 같다. binary classification이라 BCE loss가 쓰이는 모습. ---- updated mask를 얻은 뒤, updated mask로 또 NeRF학습하는 식의 iterative update를 했다고 적어두었다. (연산량, 학습 시간 따위...) |
 |
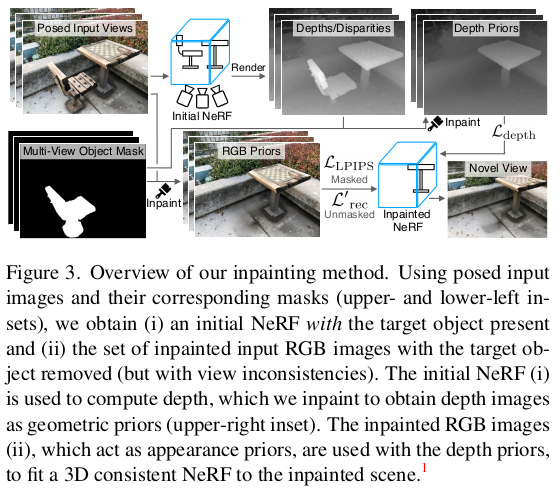 그 다음은 inpainting 알고리즘 각각 masked image에 적용해서 빈 곳을 자연스럽게 채워준다. 그리고 다시 inpainted image로 NeRF를 학습한다. |
 |
하나의 팁이, inpainted region, 즉 masked region같은 경우는 새로 채워져 있더라도 이게 3d consistent한지는 사실 보장할 수 없기 때문에 원래 color loss처럼 l2 loss로 학습을 하면 조금 망가진다고 한다. 따라서 이 inpainted region에 한해서는 l2 color loss가 아닌 perceptual loss를 걸어준다고 한다. 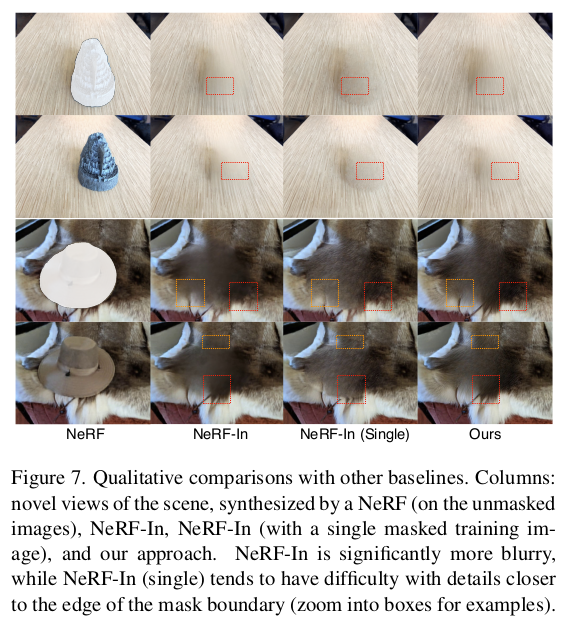 |
  |
추가적으로 inpainted region 학습을 강화하기 위해서 depth loss를 사용한다. inpainted image로 학습되고 있는 NeRF에서 만든 rendered depth와 inpainting(rendered depth)를 를 비교해준다. 즉 여기서 depth inpainting을 한 번 더 한 뒤 pseudo GT로 이용하는 것이다. (rgb inpainting, depth inpainting 다 한다는 소리...) |
 |
구조를 보면 (내용을 봐도) 연산량이 어마어마 할 것 같은데, 실제로 여러번 NeRF를 태우고 inpainting도 태우고 해야해서 한 pixel당 gradient가 계산되는 횟수가 많다. 따라서 이미지 단위로 학습 (특히 perceptual loss를 이미지 단위로) 하게 되면 메모리 이슈가 있다고 한다. 따라서 이미지 단위를 낮추어 패치 단위로 학습했다고 한다. |
 |
이건 알고리즘 한 번 더 돌리란 소리 같아서 약간 개소리 같은데 최종학습 되고 나면 depth가 있기 때문에 mask pixel들을 하나하나 multiview constraint가 맞는지 안맞는지 확인해서 보정할 수 있다는 것이다. 그래서 mask를 좀 더 정확하게 깎을 수 있으면 inpainting 난이도도 줄어드니 성능이 좋아진다는 말. ----- 근데 source view에서 depth가 존재한다는 것은 이미 NeRF를 한 번 돌렸다는것인데 일반 NeRF를 한 번 돌려두라는 소리라서 너무 복잡해지는 듯... |
 |
데이터셋은 직접 만들어서 썼음. |
 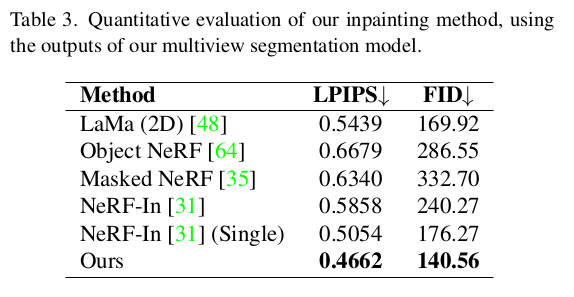 |
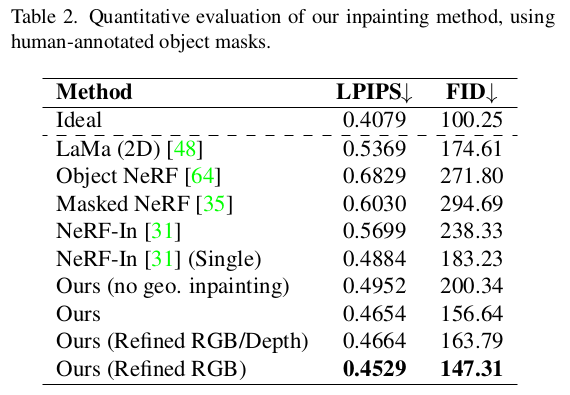 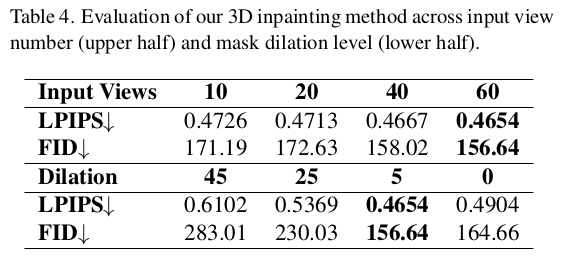 |
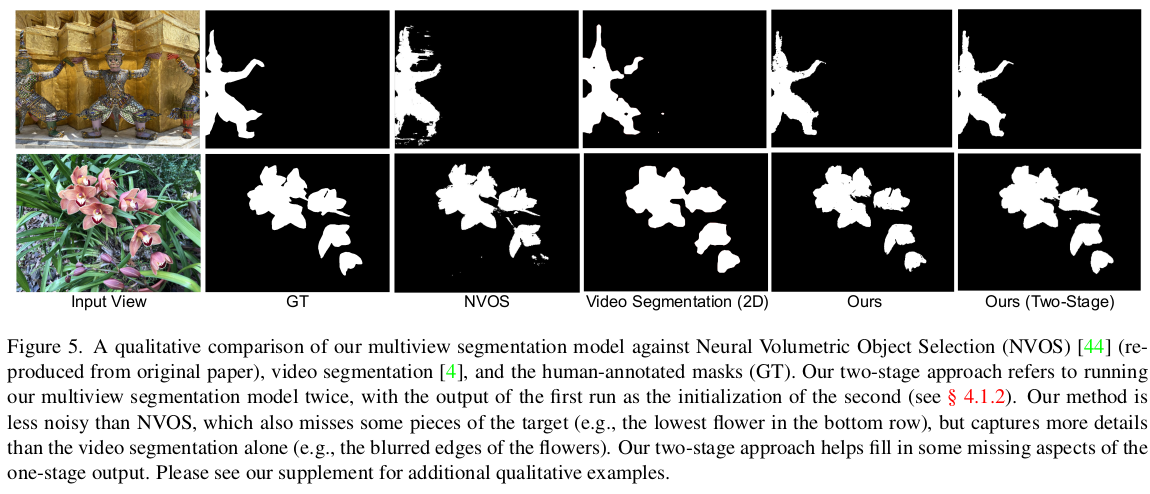 |
 |
반응형