High-Resolution Image Synthesis with Latent Diffusion Models

내 맘대로 Introduction
diffusion 논문의 인기를 극단적으로 끌어올리는데 기여한 또 다른 기념비적 논문 중 하나다. diffusion model이 갖고 있는 문제를 해결하는 것은 contribution으로 주장하는 논문이다. diffusion model은 이미 기존 generative model의 단점을 상당수 개선했지만 여전히 문제점은 갖고 있다고 한다.
- 엄청나게 오래 걸리는 학습 시간
- 긴 inference 시간
2023.02.17 - [Reading/Paper] - [Diffusion] Denoising Diffusion Probabilistic Models 의 result 부분에서 해설한 바와 같이 diffusion model을 학습 양상을 보면 독특한 면모가 있다.
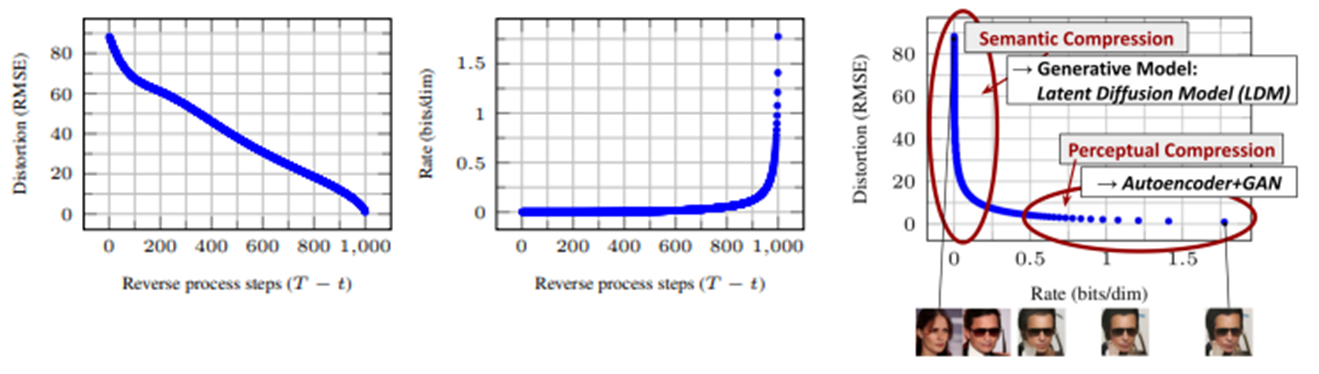
위 그림과 같이 reverse diffusion process 초반부에는 semantic 정보 위주로 복원하여 큰 틀에서 이미지 유사성을 폭발적으로 늘리고, 후반부에는 perceptual 정보 위주로 복원하여 디테일한 부분의 이미지 유사성을 천천히 늘리는 방식으로 학습된다는 것이다.
저자는 이러한 특성을 이용해 diffusion model의 학습 속도 및 inference 속도를 높이는 방법을 제시한다. 동시에 성능 또한 개선될 수 있음을 보여준다.
핵심 내용
1. Seperate semantic part and perceptual part
저자가 주장하는 핵심 아이디어는 diffusion model이 애초에 semantic 정보와 perceptual 정보를 따로 분리해서 학습하는 형태를 갖고 있으니 아예 이를 분리하자는 것이다. perceptual 정보를 찾는 것은 기존 모델이 강력하다는 것을 알고 있으니 perceptual 정보는 기존 방법에 맡기고, 오히려 기존 모델이 약한 semantic 정보 부분만 diffusion model에게 맡기겠다는 전략이다. divide-and-conquer 같은 전략이다.

첫번째로 위와 같이 auto-encoder 구조로 모든 이미지에 대해 perceptual 정보를 잘 압축하는 모델을 사전학습시킨 뒤, 고정한다. 이 모델은 CNN 기반으로 latent variable, z 는 spatial information을 그대로 들고 있는 형태로 맵핑된다.
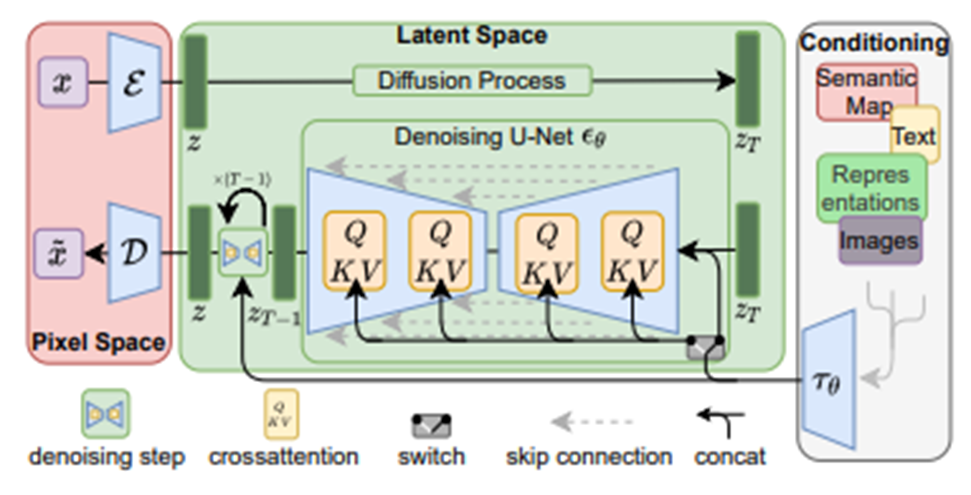
그리고 이 z가 기존 diffusion model의 이미지 입력 들어가듯이 입력으로 들어가는 것이다. 즉, 이미지 대신 latent image가 들어가는 것이다. 이 때 latent image를 만들 때 downsample이 포함되기 때문에 원본 해상도보다 width, height가 줄어든 상태가 된다. 이에 대한 긍정적 효과로 네트워크 속도가 빨라진다.
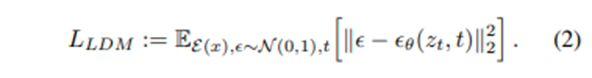
loss 또한 기존 diffusion model이 사용한 수식과 동일하지만 이미지 입력 x가 아닌 latent 입력 z가 사용된다는 차이가 있다.
단순해보이지만 이러한 접근이 파워풀한 이유는 latent image, z가 이미 perceptual 정보를 고도로 압축한 입력이기 때문에 diffusion model은 semantic 정보에만 집중해서 학습할 수 있다. 학습 효율이 높아짐과 동시에 perceptual 정보 복원에 기여했던 reverse diffusion step을 없애거나 줄일 수 있기 때문에 전체 소요 시간이 줄어드는 효과도 있다.
물론 latent image, z를 섬세하게 만드는 것이 중요하다. auto-encoder가 너무 무거워 과하게 perceptual 정보만을 압축할 경우, 원본 이미지가 갖는 정보를 손실한 상태로 맵핑될 수 있고, 너무 가벼워 얕게 perceptual 정보를 압축할 경우, 나머지 perceptual 정보는 diffusion model의 몫이 될 수 있기 때문에 적절한 설계가 필요하다.
나머지는 거의 동일하다.
2. Conditioning Mechanisms
추가적으로 stable diffusion 논문에서는 condition을 제공하는 방법을 소개한다. 기존 diffusion model 같은 경우는 초기 GAN 처럼 modality가 한정되어 있는데, 후기 GAN처럼 modality를 부여하는 시도를 했다.
방법은 1) auto-encoder를 사전학습시킬 때 condition (semantic segmentation, bouding box, text 등) 을 같이 입력 받는 형태로 학습을 해두고 2) reverse diffusion process일 때 중간 중간 cross-attention layer를 집어넣어 주는 방식이다.
이 때 2)에서 중간 중간 입력으로 들어갈 때는 2D 형태로 편집되어서 들어간다.
여기서 굳이 attention layer를 집어넣은 이유는 기타 논문에서 modality를 부여할 때 효과적인 layer임이 밝혀졌기 때문이라고 한다.

condition을 더하면 loss function은 위와 같다. 간단한 추가다.
*Note
Unet이 CNN 기반이기 때문에 초기 논문에서는 inductive bias (spatial info.를 잘 함축)가 높은 장점이 있다고 주장한 바 있는데, 이렇게 inductive bias가 낮은 attension layer를 넣으면 inductive bias가 높은 장점을 잃는 것이 아니냐는 생각을 한 적이 있다. 하지만 논문에서는 Unet의 장점인 inductive bias를 그대로 가져간다고 한 것이 이상했는데 내 생각은 다음과 같다.

일단 위 Unet 내부가 전부 attention layer가 되는 것이 아니다. 여전히 Convolution layer가 존재하며 attention layer의 결과도 다시 2D 형태로 변환되기 때문에 inductive bias가 유지된다고 할 수 있다.

또한, pyramid 구조인 Unet의 구조 상 이미지 block이 다양하게 나뉘어져 있기 때문에 inductive bias가 여전히 유지된다고 볼 수 있을 것 같다. (틀렸을 수도 있다)
3. Result
다양한 condition에서 압도적으로 잘 됨을 볼 수 있다. 속도 또한 줄었다고 하는데 수치는 그냥 논문 보는 것을 추천한다.




'Paper > Generation' 카테고리의 다른 글
| SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields (0) | 2023.11.16 |
|---|---|
| DreamFusion : Text-to-3D using 2D Diffusion (0) | 2023.07.26 |
| PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360◦ (0) | 2023.07.12 |
| Efficient Geometry-aware 3D Generative Adversarial Networks (3) | 2023.07.11 |
| [Diffusion] Denoising Diffusion Probabilistic Models (1) | 2023.02.17 |