반응형
내 맘대로 Introduction

간단히 말해 3D GAN인데 multiview contraint가 맞아떨어지도록 이미지와 geometry를 생성해주는 3D GAN이라고 보면 된다. 단순히 2D GAN에서 쓰는 방식대로 3D GAN으로 확장했을 경우, 결과의 퀄리티를 떠나서 multiview contraint는 유지되지 않고 각각 독립적으로 생성되는 모양이다.
하지만 이 논문에서는 feature generation -> neural rendering 구조로 voxel grid를 이용하는 neural rendering의 기법을 가져와서 multiview contraint를 유지한 채로 generation을 할 수 있도록 설계했다. 위 이미지를 보면 직관적으로 이해가 될텐데 single image에서 생성한 결과를 다른 시점과 비교해봐도 상당히 유사하게 생성되는 것을 볼 수 있다.
이 논문의 강점은 위와 같은 컨셉을 구현해냈다는 것과 동시에 feature generation과 neural rendering이 분리되어 있는 구조이기 때문에 feature generation이 더 성능 좋은 네트워크로 교체될 수 있다고 한다. 따라서 generalization 문제도 같은 프레임워크 안에서 개선시킬 수 있다. neural rendering 쪽에서도 voxel grid를 통 volume을 쓰는 것이 아니라 tri-plane으로 나누어 씀으로써 속도를 많이 개선시켰다. 그리고 무엇보다 NVIDA에서 나온 논문이다.
메모하며 읽기
  |
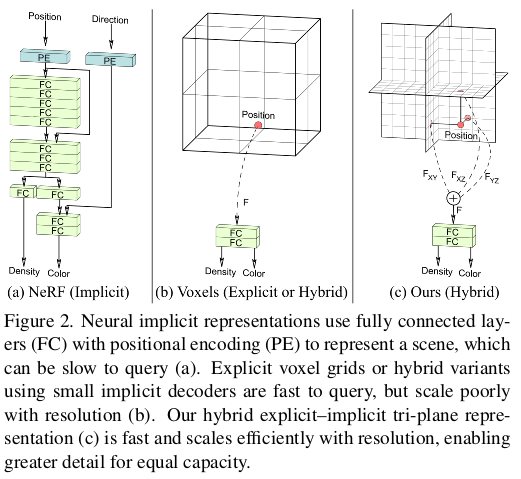 Tri-plane representation에 관한 설명인데 위 그림의 최우측과 같이 3D 공간을 표현할 때 세평면으로 표현하는 방법이다. 2D feature 3면으로 3D feature를 표현할 수 있으므로 O(n^3)에서 O(n^2)가 되는 장점이다. 뒤에 작은 MLP를 달아 NeRF포맷으로 맞춘다. |
  |
 Tri-plane represenation이 효과적인가를 먼저 보았는데 기존 NeRF에만 적용해도 효과가 뛰어났다. (tri-plane + NeRF 논문들이 꽤 있지만 이 논문이 2022년 논문이라 그렇다) |
 |
|
  |
전체 구조는 StyleGAN2 backbone으로 feature 추출 -> 채널 3단 분리 후 tri-plane 만들기 -> 3D feature 추출 -> Neural Rendering -> super resolution -> StyleGAN2 discriminator 이다. 3D consistency 능력은 Neural Rendering과 camera params conditioning에 의해 주어진다. |
  |
먼저 StyleGAN2 backbone으로 feature를 뽑는 부분 설명이다. 96채널로 single image에서 2D feature를 뽑고 32 채널씩 3등분 해서 각각 xy, yz, zx plane이라고 생각하며 분리한다. 그리고 3D feature로 만들 땐 각 3D 좌표를 각 평면 좌표로 변환해서 xy, yz, zs feature를 찾아내고 bilinear interpolation + MLP로 encoding해서 만든다. (이 때 MLP에 PE 안들어감!) 그리고 Neural rendering이 이어지는데, 독특하게 rendering의 결과를 RGB로 한 것이 아니라, Feature image로 했다. 어차피 중간 산물이기 때문에 채널을 더 두어서 풍부한 정보를 가진 feature 형태를 유지하는 것이 나을 것이라 생각해서 32 채널의 feature image를 생성하도록 했고 이중 맨 앞 3채널이 RGB다. |
 |
tri-plane을 사용해서 O(n^2)로 만들긴 했지만 3D 공간을 커버해야하기 때문에 연산량 문제를 여전하다. 따라서 충분한 n을 쓰진 못한다. 따라서 중간 산물들은 다 n=128 로 다소 작은 dimension을 사용하고 superresolution함으로써 처리했다. superresolution 모듈은 이전 backbone에서 나온 feature image(첫 3채널은 RGB 나머지 채널은 support feature) 를 upsampling하면서 동시에 aggregation 해서 고해상도 RGB를 만든다. |
 |
superresolution이 끼면서 두 해상도의 산물이 존재하게 되어 마지막 단계인 discrimination도 두 해상도를 타겟으로 한다. 그래서 이름이 dual discrimination이다. neural rendering에서 나온 feautre image에서 첫 3채널을 분리해서 얻은 저해상도 RGB 이미지와 superresolution까지 거쳐 만드어진 고해상도 RGB를 대상으로 둘 다 discrimination 한다. 근데 단순히 각각 돌리는 것은 아니고 저해상도 RGB 이미지를 bilinear upsampling 후 고해상도 RGB 이미지와 concat해서 6채널 이미지를 만들고 이 6채널이 미지를 StyelGAN2 discriminator에 넣어준다. (채널이 바뀌었기 때문에 discriminator는 완전 새로 학습했을 것으로 보임) 추가적으로 styleGAN2가 condition을 잘 처리함으로 camera parameter를 condition으로 넣어주었다. 참고로 cam param 추가하는 김에 그림 4.보면 여기 저기 다 넣어준 걸 볼 수 있다.  두 해상도 RGB 이미지를 모두 discrimination하는 것의 추가적 효과로 multiview consistency가 강화된다. 왜냐면 저해상도 RGB 이미지는 consistency가 유지되는 neural rendering의 결과물인데 이 저해상도 RGB 이미지와 비슷하도록 강제하기 때문이다. |
   |
이건 데이터셋의 문제인데... 정말 예상도 못했다.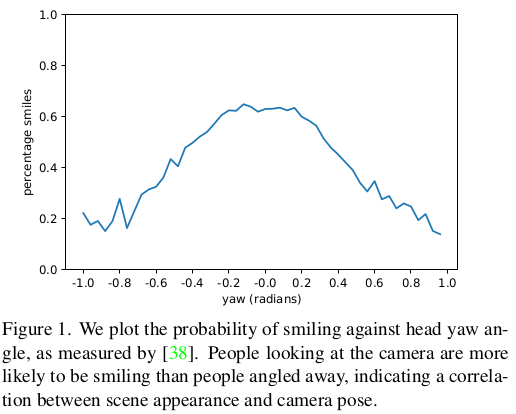 사람들이 카메라를 정면으로 보면 웃고, 뒤돌아서 찍으면 안 웃는 경향이 있기 때문에 보통 웃으면 카메라 향 이미지고 안 웃으면 카메라 반대향 이미지다. 따라서 네트워크가 볼 때 웃는 모양을 보고 카메라 방향을 유추할 수 있게 되는 것이다. 따라서 이 문제를 완화하기 위해서 맨 처음 backbone에도 cam param을 condition으로 제공한 것이다. ----- 추가적으로 single view만 쓰다보니 사실 cam param condition을 준다해서 웬만하면 정면 cam param condition이게 되는데 이러면 네트워크에 bias가 생긴다. 이게 2D bill board angle 문제를 만든다고 한다.  bill board angle이 자세히는 모르겠는데, 위 그림으로 유추해보건데 정면에 워낙 bias되어 있다보니, 회전각을 만들라고 했을 때 형상 까지 고려해서 3D rotation 그대로 잘 돌리는 것이 아니라 위 그림과 같이 형상은 평면 상에 그대로고 고개만 돌리는 rotation으로 돌리는 문제 같다. 결과적으로 아래와 같은 효과가 생기는 듯.  |
 |
|
 |
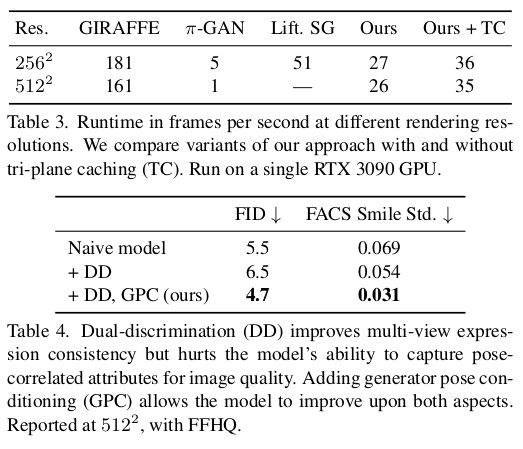 |
 |
 |
 multiview consistency를 평가하기 위해 COLMAP 태워봤는데 복원이 잘된다...! |
 데이터셋의 카메라 포즈 정확도가 절대적으로 받쳐주어야한다. |
반응형