Nerfies: Deformable Neural Radiance Fields

내 맘대로 Introduction
2023.04.07 - [Reading/Paper] - [NeRF] Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video
2023.04.07 - [Reading/Paper] - [NeRF] D-NeRF: Neural Radiance Fields for Dynamic Scenes
2023.04.08 - [Reading/Paper] - [Human] Animatable Neural Radiance Fields for Modeling Dynamic Human Bodies
위 세 논문과 동일하게... 역시나 ICCV 2021에 발표된 NeRF에 time 축을 추가하는 방법에 대한 논문이다. 방법론 자체는 비슷비슷하지만 좀 더 완성도 있는 논문이라서 우위에 있는 논문이라고 생각한다.
observation-to-canonical 컨셉을 공통적으로 이용했다. 각 프레임을 canonical space로 옮기고 canonical space에서만 단 한 개의 NeRF를 학습시키는 방식이며 canonical space로 옮기는 deformation이 역시나 핵심인 논문이다.
핵심 내용
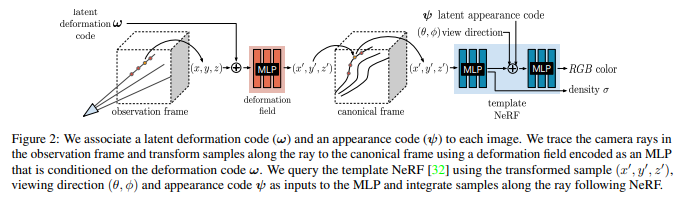
time, t 하나 하나를 observation frame이라고 정의하고, observation volume에서 뽑은 point, x를 deformation field를 통과시켜 canonical frame의 point, x'으로 옮긴다. 그리고 canonical volume에서 NeRF를 학습시키는 파이프 라인을 갖고 있다.
먼저 deformation field는 point, x와 latent deformation code, W를 입력으로 받는데 여기서 W는 learnable code로 각 프레임마다 부여된 code다. 입력을 x만 주면 deformation field network 입장에서 이게 어느 프레임의 3D point인지 모르기 때문에 구분력을 주기 위해 넣어주는 것이다.

출력으로 나오는 canonical space 상 point, x'은 단순히 x->x' offset이 나오는 형태가 아니라 조금 더 신경을 썼다. 이전 논문들에서는 그냥 offset을 사용했지만, 단순히 offset이 나오도록 설계한다면 offset이 복잡한 rotation과 translation을 커버해야하기 때문에 효율성이 떨어진다고 하여 다른 방법을 썼다.
네트워크가 x를 x'로 옮길 때 필요한 transformation을 screw axis representation으로 내뱉게 했다. 대충 rotation, translation 형태라고 보면된다. rotation과 translation을 분리한 형태로 deformation field를 추정하여 더 정확도를 높였다.
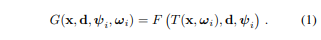
그리고는 canonical space로 다 옮겨지면, NeRF를 한 번 학습하면 된다. 여기서 마지막에 들어가는 term은 appearance code로 time, t마다 같은 대상이라도 색감 차이, 조명 차이가 있는 것을 커버하기 위한 code다. 역시나 learnable이다.
학습 방법론은 다음과 같다.

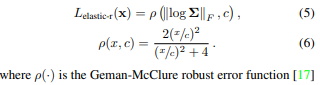
자르기가 어려워 통째로 가져왔는데, 요약하자면 deformation field가 별도의 regularization 없이는 날라다닐 수 있기 때문에 억제하는 방법이 필요했다고 한다. 그 방법은 observation space, x -> canonical space, x'로 옮겨질 때 jacobian, J(x)의 크기를 억제하는 것이다. 너무 큰 offset이 발생하지 않도록 하는 것이다.
자세히는 모르겠지만, screw axis representation으로 offset을 정의했기 때문에 x->x' 과정에서 jacobian을 쉽게 계산할 수 있고 이를 이용한 것 같다. 구체적인 수식은 위에 적혀있고 (증명은 잘 모르겠다.) 이를 loss에 추가했다.

추가로 background는 deformation field가 0이 나와줘야 되는데, 아무런 조치도 취하지 않으니 background도 deformation되는 효과가 있었다고 한다. 이를 억제하기 위해 배경에 해당하는 3D point에 직접 deformation을 0로 강제하는 L2 loss를 추가했다.
배경에 해당하는 3D point는 이미지에 대응되는 카메라 자세를 계산할 때 SfM 돌리고 나온 부산물을 이용했다고 한다. SfM 돌렸을 때 배경이 정적이므로 feature matching이 잘 될 것이고 배경에서만 3D point가 잘 나올 것이기 때문에 지금 상황에 이용하기 딱 좋은 정보인 것 같다.
마지막으로 내가 보기에 이 논문에서 가장 완성도를 높여주는 대목이 있는데 다음과 같다.

바로 coarse-to-fine training을 적용하는데 이미지 해상도를 건드리는 것이 아니라 positional encoding을 건드는 것이다.

2023.03.10 - [Knowhow] - Positional encoding 에서 짧게 언급한 바 있듯이,positional encoding을 짧게 했을 때는 low-frequency 정보 학습에 유리하고, 길게 했을 때는 high-frequency 정보 학습에 유리하다.
위 예시에서 positional encoding을 짧게 쓰면 low-frequency 정보에 해당하는 전체 얼굴 각도 정도만 배우는데, 길게 쓰면 high-frequency 정보에 해당하는 표정까지 배우는 것으로도 알 수 있다.
이를 이용하기 위해 학습이 진행되면 진행될수록 positional encoding이 길게 들어가도록 설계했다!! (대박)

수식(8)과 같이 positional encoding 각 term 앞에 곱해질 weight를 만들어 사용했다. 이로써 별도의 조치 없이도 coarse-to-fine 방식으로 low-frequency 정보부터 학습을 하고 high-frequency 정보를 뒤이어 학습하게 된다.
Results

deformation이 날라다니는 것을 억제하기 위해 추가한 elastic energy term의 효과도 출중했으며,

SfM에서 나온 배경 3D point를 활용하여 배경 부분 deformation을 억제하는 효과도 훌륭했다.

전반적인 복원 결과도 압도적으로 좋음을 보여준다. (NR-NeRF, D-NeRF가 부끄러워 질 정도...)



프로젝트 페이지 https://nerfies.github.io/ 에 동영상 결과물이 더 있으니 꼭 보길 추천한다.