D-NeRF: Neural Radiance Fields for Dynamic Scenes

내 맘대로 Introduction
이 논문도 NeRF를 움직이는 대상으로 확대하는 방법에 대한 논문이다. 이전에 읽었던 2023.04.07 - [Reading/Paper] - [NeRF] Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video 논문과 목적이 같은 논문이고 사실 상 아이디어도 같다. 같은 해 같은 학회에 제출된 논문들이기 때문에 서로에 대해 몰랐고 선점권 또한 없어서 같은 방법 두 개의 논문이 생긴 것 같다. 개인적으로 이 논문이 더 깔끔하게 작성한 것 같다.
방법은 NeRF에 time, t를 추가해서 학습하는 것인데 역시나 canonical volume을 이용한다. time, t volume에서 ray를 생성한 뒤, offset을 계산하여 canoncial volume에서의 ray로 만들고 canonical volume 상에서 NeRF를 적용하는 순서다.
핵심 내용

문제를 정의하길 하나의 카메라로 움직이는 대상을 찍어서, 움직이는 대상을 새로운 시점에서 바라본 이미지를 생성하는 것으로 정의했다. (사실 카메라를 1개를 쓰든 N개를 쓰든 어차피 카메라 파라미터는 사전에 계산을 해둬야 하기 때문에 큰 의미는 없는데 있어보이기 위해 추가한 듯 하다.)

그림이 직관적으로 잘 그려져 있어서 더 설명이 필요없는 것 같기도 하다. Deformed volume에서 "직선" ray를 생성하고 이 위에서 점 x를 뽑는다. 그리고 이 점 x를 time, t로 condition으로 주어 deformation network를 통과시키면 dx, 즉 점 x를 canonical volume 상 대응되는 위치로 옮기는 offset이 나온다.
"직선" ray 상 모든 점 x에 대하여 이것을 반복하면 canonical volume 상 "곡선" ray가 생성되고 이 "곡선" ray를 이용하여 NeRF를 학습하는 방식이다. deformation network에서만 time, t를 사용하고 뒷단에는 완전히 NeRF와 같은 것이다.


학습은 당연하게도 NeRF loss 그대로 썼다. volume rendering loss다.
이전 NR-NeRF와 달리 큰 regularization term 추가없이도 학습이 잘 되었다고 하는게 신기한 부분이다. NR-NeRF에서는 deformation network만 썼을 때 결과가 안 좋아서 rigidity network를 추가하고 각종 regularlization term을 추가한 것인데 D-NeRF에서는 deformation network 하나만 써서 잘 학습을 시켰다고 하니 어떤 차이가 있는건지 궁금하다.
추측컨대, 학습 대상으로 삼는 물체가 D-NeRF에서 쓴 것이 더 단조로워서 학습이 잘 되었나 싶다. NR-NeRF는 결과 그림들을 보면 실환경 이미지가 대다수인데 D-NeRF는 synthetic이 더 많기 때문이다. 그래서 NR-NeRF가 더 나을 것 같다는 생각이다.
Results

NR-NeRF와 마찬가지로 deformation offset을 이용하여 correspondence를 찾을 수 있었는데 그 결과를 보아하니 정확성이 꽤 높다는 것을 볼 수 있다.
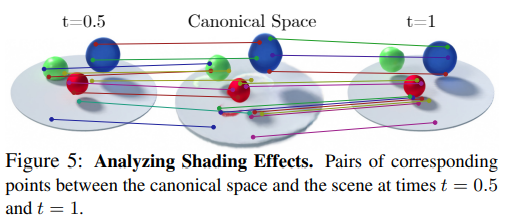
단순히 time, t를 positional encoding해서 추가하고 offset을 구할 때만 반영했기 때문에 시간에 따른 변화가 잘 반영된 view가 만들어질 지 의심이라고 했었는데 그림자로 미루어보아 충분히 잘 반영된다고 한다.

NR-NeRF는 없지만 초창기 NeRF 대비는 잘된다고 한다. (지금은 수두룩하게 쏟아져 나와서 사실 이 논문 결과는 이제 더 이상 의미가 없긴 하다.)
