Practical Stereo Matching via Cascaded Recurrent Network
with Adaptive Correlation

내 맘대로 Introduction
이 논문은 제목에 그대로 Stereo matching 논문인데 "rectification 후 epipolar line을 따라 search한다." 라는 기본 stereo matching pipeline 에서 "epipolar line을 따라"를 변경한 논문이다.
rectification은 완벽할 수 없기 때문에 (실제로 내가 해봐도 pixel 수준으로 align되도록 하는 것은 힘들더라) 하나의 epipolar line만 따라 search하는 것은 사실 실환경에서는 문제가 있는 접근법이라고 지적하며 rectification 오차를 고려하여 1D가 아닌 2D로 line 주변부도 본다.
또한 epipolar line을 따라 다 훑는 것도 낭비라고 한다. 보통 정해진 min-max disparity range를 정해고 이 모든 range를 다 loop를 돌면서 cost check하는 것이 정석인데 이 loop 중 상당수는 무의미한 loop이며 오히려 잘못된 결과를 만들기도 한다. 따라서 이 최대한 유의미한 loop만 남기고 정확성을 끌어올리기 위해 epipolar line 따라 훑지 않고 attention을 통해 활성화된 영역만 훑는다는 전략을 쓴다.
대충이라도 rectification을 한 데이터를 쓰기 때문에 완전히 epipolar constraint를 버렸다고는 할 수 없는데 기존과 조금 다른 방식임은 분명하다. 한 마디로 이 논문은 epipolar constraint + attention으로 search 효율을 높임과 동시에 2D search를 통해 noise까지 다룬다.
핵심 내용

전체 그림은 위와 같다. 독특한 점은 stacked 구조와 cascaded 구조를 둘 다 쓴다는 것이다. 다른 말로 image pyramid를 이용해 multi-resolution 을 활용하는 것도 하고 첫번째 추정 값이 다음의 초기값으로 들어가도록 하는 iterative update도 활용한다.
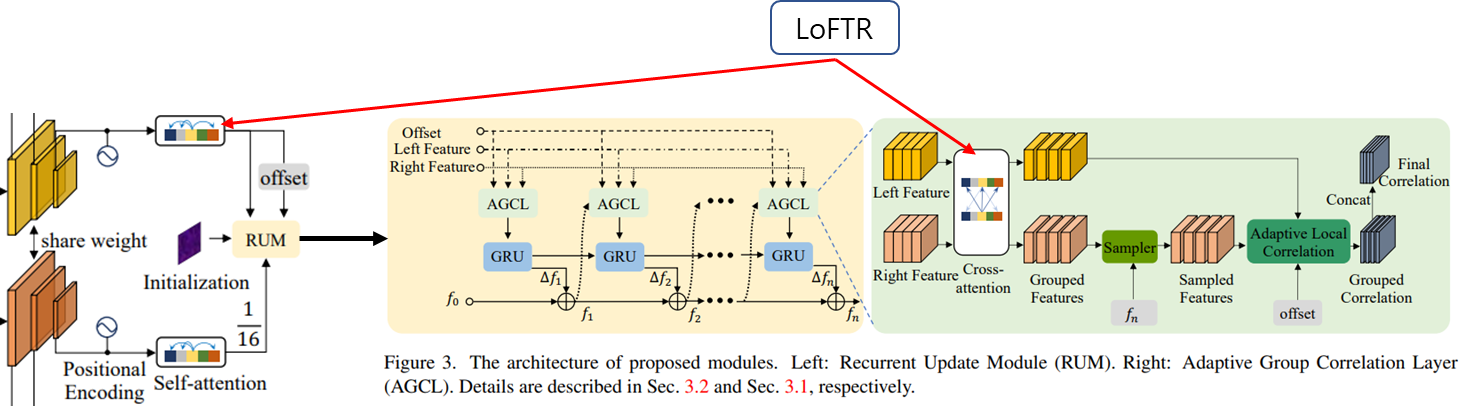
그림이 조금 아쉽긴 한데 일단 3가지 resolution으로 encoding된 image feature을 시작으로 LoFTR module이 따라 붙는다.
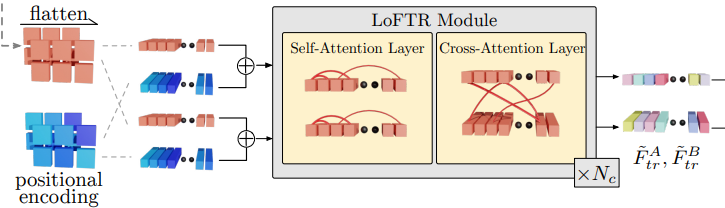
참고로 LoFTR은 위와 같이 생긴 모듈인데 self-attention에서 cross-attetion으로 이어지는 구조의 모듈이다. 여기서 앞의 self-attention은 RUM 밖에 그려졌고, cross-attention은 RUM 안에 그려져서 조금 헷갈린다. 우측 그림의 Left Feature와 Right Feature는 self-attention까지 적용된 feature라고 보면 되겠다.

cross-attention까지 끝난 feature에서 현재 disparity, fn을 이용하여 재배열한 sampled feature를 만든다. 이 의미를 해석해보면 introduction에서 말한 epipolar geometry + attention을 이용해 right feature 중 정말 보아야 할 곳의 feature들만 뽑아 left feature와 pixel aligned된 형태로 변형했다고 볼 수 있다.
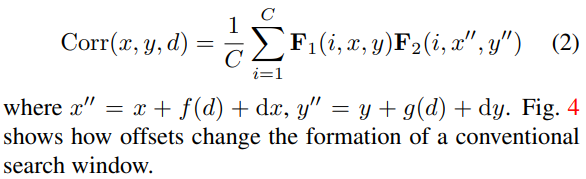
그리고 나서 aligned된 feature 간의 correlation을 위 수식을 이용하여 계산한다. 주의할 점은 notation, d 가 disparity를 의미하는 것이 아니라 feature의 d th channel을 의미하는 index이다. x" = x + f(d) + dx 같이 pixel aligned 시켜놨는데 굳이 주변도 보는 이유는 rectification이 잘 안됐을 것이라는 가정을 했기 때문에 주변도 약간 살펴주는 것이다.
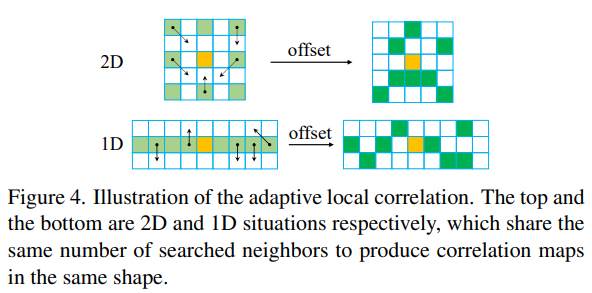
주변 범위 f(d)와 dx는 각각 고정된 값, 네트워크가 추정하는 값이며 위 그림에서 f(d)는 왼쪽 연두색처럼 정해진 위치까지의 변위이며 dx는 네트워크의 의견에 따라 연두색에서 녹색으로 약간 보정하는 변위이다. 이런 방식으로 주변부를 고정+가변적으로 효율적으로 비교하여 rectification 오차가 있음에도 correlation 비교가 잘되도록 했다.
참고로 2D와 1D 방식을 동시에 썼다. 추정컨대, feature channel dimension이 D 인데 0 ~ D-1까지 어느 채널은 1D, 어느 채널은 2D로 하고 1D 중에서도 stride를 다양하게, 2D도 stride를 다양하게 했을 것 같다.

이 짓을 iterative 하게 여러 번 돌려주고 최종 disparity, fn을 취하는 형태다.

실제 inference 때는 여러 해상도로 입력을 조절하여 넣고 결과를 합치는 식으로 해서 multi-resolution 효과를 극대화한다고도 한다.
Results
일단 benchmark에서 성능은 타 논문 대비 어마어마하게 높다. Oral paper로 선정된 이유 중 하나가 이러한 큰 성능 차이이지 않을까 싶다.
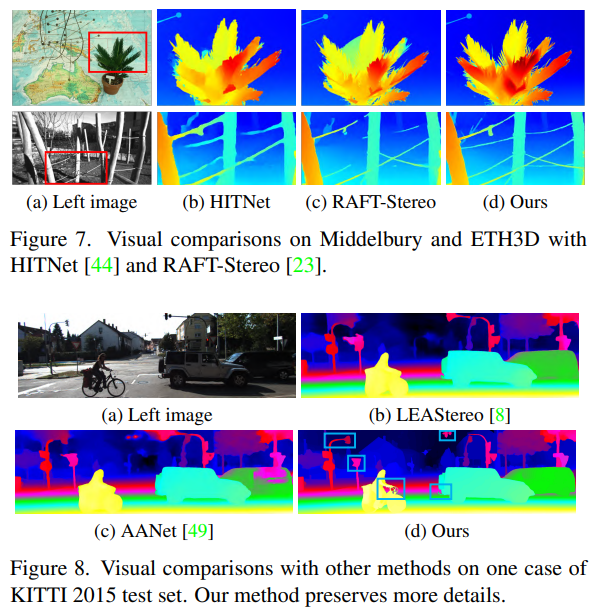


디테일한 부분까지 depth를 잡아내는 것이 눈에 띄는데 generalization이 얼마나 잘 되는지만 확인이 되면 매우 뛰어난 알고리즘이 확실한 것 같다.