Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video

내 맘대로 Introduction
이 논문은 제목 그대로 Non-rigid 즉, 고정되어 있는 물체가 아닌 움직이는 물체에 대해서 NeRF를 어떻게 구현할 수 있는지 설명하는 논문이다. 가볍게 말한다면 움직이는 대상은 시간에 따른 변화가 있는 물체를 말하는 것이니 NeRF에 time을 더하는 방법이다. 기존 NeRF가 새로운 시점 물체 이미지를 얻을 수 있었다면, NR-NeRF는 새로운 시점의 물체 비디오를 얻을 수 있게 되는 것이다.
생각하기를, 물체는 NeRF와 마찬가지로 고정된 상태로 한 공간에 가만히 있는데 time, t의 이미지는 이 공간에 "특정하게 휘어진" ray가 통과하면서 렌더링한 이미지라고 보는 것이다. 즉 핵심 역할을 하는 것은 기존 NeRF와 동일한데 time, t frame의 ray를 canonical space의 "휘어진" ray로 변환하는 모듈만 앞에 추가된 것이다.
핵심 내용

Deformed volume이 time, t의 공간이고 canonical volume이 고정된 기준 공간이다.
Deformed volume에서 "직선" ray를 생성하고 그 위의 점 x를 만든다. 그리고 이 점 x들을 Ray-Bending Network를 통과시키는데 그 출력은 해당 x가 canonical volume에서 어느 위치로 가야하는지 그 offset (x, y, z) 이다. 단순히 x만 넣어주면 어느 time, t 인지 모르기 때문에 그 condition을 주기 위해 time, t 이미지를 auto-encoder를 이용해 latent code로 만든 l을 같이 넣어준다.
이렇게 offset, b'(x, l)을 구하고 나서 x+b'(x,l)로 만들면 이는 canonical volume에서의 위치이고 모든 "직선" ray에 다 적용한다면 결과적으로 canonical volume에서의 "곡선" ray를 얻을 수 있다. 이 "곡선" ray를 따라 기존 NeRF 학습을 진행하면 끝이다.

Rigidity Network 라고 위에 추가로 달려있는 부분은, 위의 과정을 구현해서 실험을 해보니 성능이 조금 떨어지는 것을 발견해서 이 문제를 해결하기 위해 추가한 것이다.
rigid part라면 deformed volume에서 위치나 cannonical volume에서의 위치나 같을 것이고, non-rigid part라면 다를 것이라는 가정을 이용해 offset, b'(x,l)을 구하고 나서 마스킹을 해주는 용도다.
defomred volume에서 rigid part인 곳이라면 w가 0에 가까울 것이고, non-rigid part라면 w가 1에 가까워 offset을 켜고 끄는 기능을 한다. 이렇게 하면 non-rigid part에 집중해서 offset을 더 정확히 추정하도록 학습할 수 있었다고 한다.
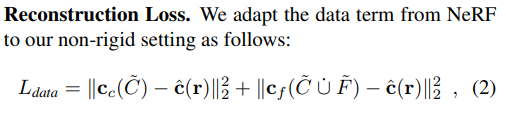
사용한 loss는 당연히 NeRF에서 사용한 loss 그대로 사용했다. 그리고 이게 메인이다.

offset 추정의 regularization하기 위해 위 loss가 추가되어 있는데 그 의미는 기본적으로 offset이 너무 커지지 않도록 억제하는 것이다. 기본적으로 움직이는 대상이 canonical volume 대비 많이 움직이진 않았을 것이라고 가정하는 것과 같다.
특징점은 L1 norm이든 L2 norm을 고정한 것이 아니라 2-w(r) 형태로 변하는 것을 볼 수 있는데 non-rigid part는 L1 norm, rigid part에서는 L2 norm이 적용되게 만들기 위함이다.

이유는 위와 같이 설명되어 있는데, non-rigid part는 offset이 크든 작든 항상 동일하게 loss를 줄이는데 집중하고, rigid-part는 offset이 작으면 약하게, offset이 크면 강하게 하는 식으로 loss를 줄여 멀리 날아가는 offset을 억제하는데 더 집중한다.
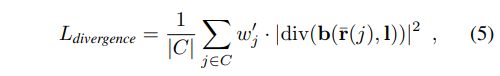
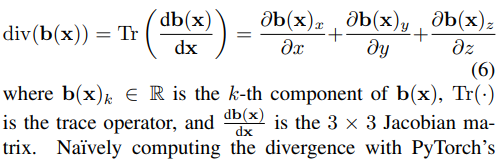
하나 더 divergence loss도 regularization용으로 추가했는데, 위 offset loss는 visible area, 즉 물체에 해당하는 부분에만 집중하기 때문에 물체에 해당하지 않는 부분에 대한 억제력은 부족하다고 한다. (아마 구름처럼 떠다니는 artifact들이 관찰됐었나보다.)
그래서 이를 억제하기 위해서 위와 같이 offset의 gradient들을 억제하는 term을 추가했다고 한다. (사실 잘 이해가 되진 않는데, 식을 보고 든 생각은 canonical volume에서 "곡선" ray가 smooth해지도록 하는 term인 것 같기도 해서 결과가 더 깨끗해질 것 같긴 하다.)
Results

목적한대로 움직이는 대상으로도 새로운 시점 이미지를 생성할 수 있게 되었고, rigidity 계산으로 인해 어디가 변형되었는지랑 그 correspondence를 찾을 수 있었다고 한다.


regularization이 필수적이었고 제안한 term들이 효과적이었다는 것도 보여주었다.
