Transformer나 NeRF 중 하나라도 다루어본 적이 있다면 Positional encoding, PE를 본 적이 있을텐데 나는 이것을 도대체 왜 쓰는지 궁금했다. 단순하게는 위치 정보를 표기하는 특별한 형태 중 하나라고 볼 수 있는데 안 바꾸고 그대로 쓰면 안되는지, 안 바꾸면 성능 차이가 그렇게 큰 지 궁금해졌고 그 이유에 대해서 공부하게 되었다.
*먼저, 내가 공부할 때 참고했던 글은 https://towardsdatascience.com/master-positional-encoding-part-i-63c05d90a0c3 이다.
Positional encoding step-by-step
Postional encoding을 왜 쓰느냐? 정답은 "네트워크 편하라고"다. 사람의 입장에서 Positional encoding은 정말 아무런 의미도 없는 헛짓거리다. 같은 의미의 값을 굳이 길게 풀어쓰는 것에 불과하기 때문이다. 하지만 네트워크 입장에서는 형태 변환이 학습 과정을 안정화시켜주고, 입력 데이터의 분별력을 높여주는 행위다. 무슨 소린지 한 단계씩 설명하면 다음과 같다.
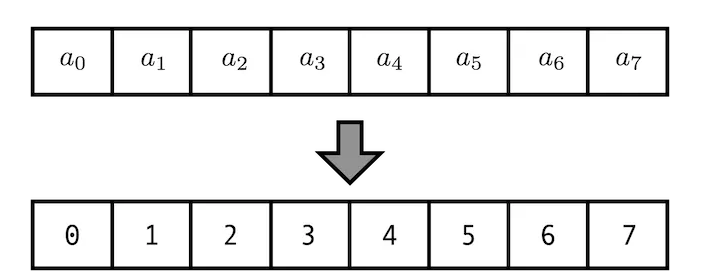
만약 a0~a7 의 위치 정보를 네트워크한테 입력으로 주고 싶다면 가장 먼저 생각나는 방법은 index를 던져주는 것이다. 위 그림과 같이 0~7 값을 사용하는 것이다. 하지만 네트워크는 -1~1 값을 좋아하지 이렇게 큰 값을 좋아하지 않는다는 것은 익히 알고 있을 것이다. 학습 안정성이 떨어지기 때문이다.

이를 해결하기 위해 normalization을 할 수 있겠지만 하나 아쉬운 것은 normalization 과정에서 데이터의 전체 크기 정보가 사라졌다는 것이다. 0~7이었다면 데이터 크기가 최소 8이라는 것을 알았을 텐데 normalized form에서는 알 수가 없다. 이 방법은 좋긴 하지만 최고는 아닌 듯하다.
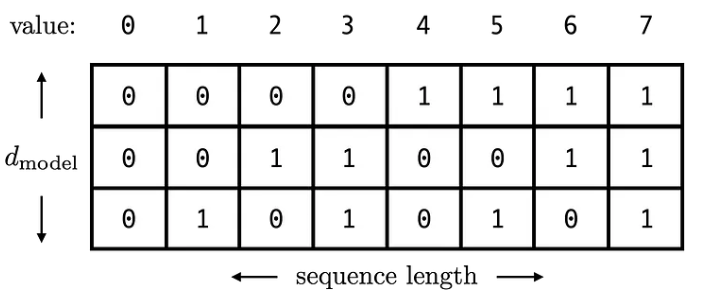
조금 더 잔머리를 써서 binary form으로 저장하는 것도 생각할 수 있는데 네트워크가 좋아하는 -1~1 범위를 유지하면서 몇 digit으로 표현할지 (위 그림에서는 dimension=3) 정해두면 데이터 크기도 가늠할 수 있어 괜찮은 방법 같다. 하지만 이 형태는 또 다른 이슈로 이진수 체계기 때문에 연속적이지 않다는 문제가 있다.
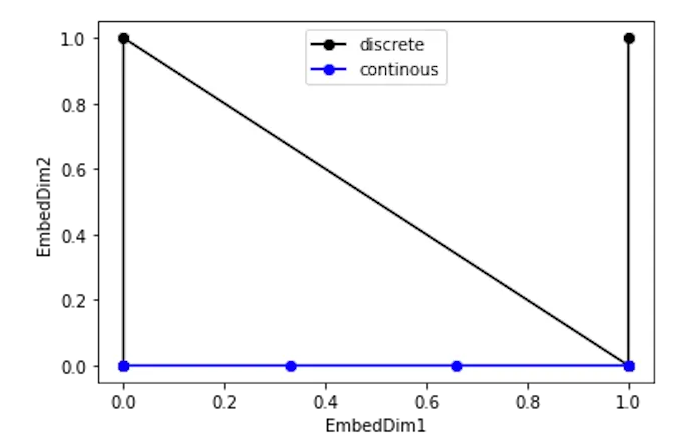
실제로 0~3 값을 binary form으로 변환한 뒤 그 중간값을 추측해본다고 생각해보면, (0,0), (0,1), (1,0), (1,1)은 의미가 연속적인 것이지 숫자 자체는 연속적이지 않다. 위 그림을 보면 직관적으로 이해할 수 있을 것 같아 더 이상 설명은 생략하겠다.

연속성 문제를 해결하고자 등장한 것이 sine 함수의 도입이다. 입력이 어떤 형태든 -1~1로 mapping해주는 함수인데다 연속성을 갖춘 함수라서 장점이 있고 주기성 문제는 binary form과 같이 여러 digit으로 표현해서 해결할 수 있다.


위 그림은 원래 형태의 입력을 sine 함수가 도입된 positional encoding으로 그린 것인데 좀 뒤틀려있긴 하지만 어쨌든 binary form 보다는 부드럽게 연결되어 있는 것을 볼 수 있다.
여기서 멈추고 그대로 사용해도 되지만 연속적이긴 하지만 조금 뒤틀려있는 모양이 거슬려서 한 번 더 개선을 시도할 수 있다. 연속적이지만 뒤틀려있다는 것은 다른 말로 선형적이지 않다는 것인데 선형적이지 않을 경우 거리 계산이나 gradient 계산, inverse 계산 여러 측면에서 귀찮은 일이 많아지긴 하므로 분명한 단점이긴 하다.

위와 같이 선형 변환이 단순하게 linear transformation이 곱해지는 형태로 정리되도록 (선형적이도록) 바꾸는 것은 간단하다.
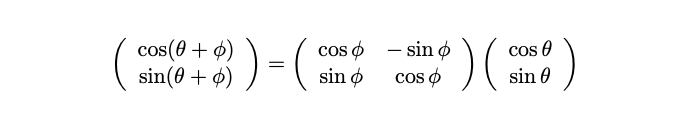
cosine 함수도 같이 쓰는 것이다. cos, sin을 pair로 사용하게 되면 그 변환은 rotation 형태를 띈 matrix 연산으로 할 수 있다. 친숙하기 까지하다.

따라서 최종적으로 위와 같이 우리가 알고 있는 Positional encoding 형태를 얻게 된 것이다.
Positional encoding discussion

position과 depth (encoding dimension)에 따른 encoding value 값을 시각화한 그래프다. 빨간 박스를 먼저 보면 low frequency cos,sin으로 encoding 된 값은 position 변화에 민감하게 바뀌는 것을 볼 수 있고, 녹색 박스의 high frequency cos, sin으로 encoding된 값은 position 변화에 민감하지 않고 항상 비슷한 것을 볼 수 있다.
이러한 양상의 영향을 생각해보면, transformer와 LSTM같이 sequence에 활용된다면 positional encoding에서 low frequency에 해당하는 녀석들은 특정 위치에 집중하도록 유도하는데 도움이 되는 부분이고, high frequency에 해당하는 녀석들은 일반적으로 보고, 오래 기억하도록 유도하는데 도움이 되는 부분이지 않을까 싶다.

또 가로축으로 보면 어떤 position이든 high frequency value는 비교적 균일하게 encoding된다. 그래서 high frequency 정보를 버리지 않도록 유도해야 할 경우에 유리할 것 같다는 생각도 든다.
이전글 2023.03.10 - [Knowhow] - Spectral bias of Neural Network 에서 spectral bias를 줄이는 방법 중 하나로 positional encoding이 효과있음이 보여졌는데 아마 연관이 있을 것 같다. 입력 x,y,z를 positional encoding을 하면 그 속의 high frequency 정보는 비교적 잘 살아남아있게 encoding되다 보니 네트워크가 spectral bias로 low frequency 정보부터 학습하는 경향이 있어도 골고루 배우게 되기 때문이지 않을까.
단순히 네트워크한테 어떻게 위치 정보를 던져줄지 고민하다가 나온 방법인데 다양한 해석이 가능한 것이 참 신기하다.
'Knowledge > Vision' 카테고리의 다른 글
| Trifocal tensor 이해하기 (0) | 2023.03.30 |
|---|---|
| Swish activation function (0) | 2023.03.10 |
| Spectral bias of Neural network (0) | 2023.03.10 |
| contiguous의 의미 (view, reshape, transpose, permute 이해하기) (0) | 2023.02.21 |
| Camera undistortion visualization(KB model, UCM, DS model) (1) | 2022.12.29 |