Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance

내 맘대로 Introduction
2023.02.21 - [Reading/Paper] - [NeRF] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 이전 글에서 Inference tips에서 언급한 바와 같이 NeRF MLP에서 output으로 얻을 수 있는 volume density를 이용하면 3D geometry를 얻을 수 있다. density volume을 만들고 marching cube 알고리즘을 적용하는 방식이었다.
이 논문은 그 특징에서 착안한 듯하다. 어떻게 하면 3D geometry도 더 정확하게 얻어낼 수 있을까? 라고 고민한 것 같다. 엄밀히 말하면 volume density는 색깔을 결정하는데 활용되는 값으로 대략 공간의 탁한 정도를 말하는 것일 뿐이니 형상을 직접 결정하는 요인은 아니다. 통상적으로 물체의 표면이 위치한 곳은 불투명하기 때문에 volume density가 높을 수 밖에 없고 이러한 경향 때문에 volume density로부터 추출한 3D geometry도 합리적인 결과인 것이다.
따라서 volume density 갖고 있는 3D geometry 정보는 강화하면서 색깔에 기여하는 역할은 보존하는 방법을 이 논문에서는 소개한다. 결과적으로 NeRF인데 3D geometry가 정확하게 나오는 NeRF 를 만드는 논문이다. 실제로 본 제목보단 Implicit differentiable renderer 라는 이름으로 IDR로 많이 불리는 논문이다.
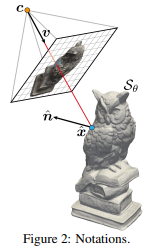
시작하기 전 알고 있어야 하는 notation 정보는 위 사진과 같다. S는 surface다.
핵심 내용
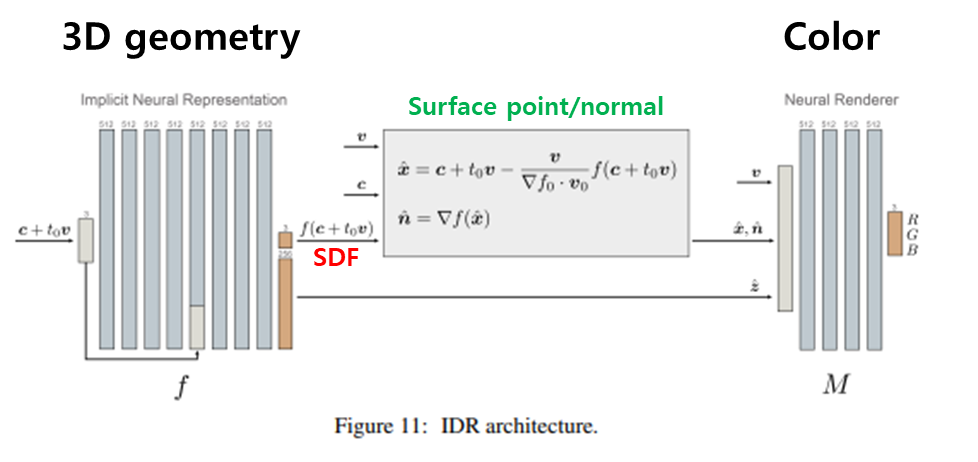
NeRF가 한 뭉치의 MLP로 끝이었다면 IDR은 둘로 나누어 3D geometry를 전담하는 전반부와 color를 전담하는 후반부로 나누어 설계되어 있다. (그래서 논문 제목에 disentangle이라는 단어가 들어가 있는 것이다.) 전반부는 SDF(signed distance function)을 추정하는 네트워크로 설계했고 후반부는 light field를 추정하는 네트워크로 설계되어 있다.
이 두 부분 사이의 bridging은 surface 정보를 이용한다. SDF는 surface를 직접적으로 결정하고 찾아낼 수 있게 하기 때문에 surface point, xˆ 와 해당 위치의 normal 정보을 손쉽게 계산할 수 있다. surface 위치 (동시에 카메라 위치)와 surface normal은 이미지에 담길 빛을 결정하는 중요한 요소이므로 연관성이 매우 짙은데 이 점에 착안해서 둘의 엮는다.
Implicit Neural Representation (SDF network)
그림의 앞부분만 봐도 알 수 있듯이 이 부분은 아주 단순한 MLP다. 그냥 입력으로 3D point (X,Y,Z)를 입력으로 받고 해당 위치의 SDF 값을 내뱉는 네트워크이고 추후에 활용을 위해서 SDF+ 256 크기의 feature z^을 추가로 내뱉을 뿐이다.
그게 전부이고, 출력 SDF의 범위제한도 없다. 즉, TSDF가 아닌 SDF다.
Surface point and surface normal (Bridging)

surface point는 특정 위치의 SDF값을 알고 있기 때문에 아주 쉽게 구할 수 있다. SDF의 의미 자체가 표면으로 떨어진 거리(부호 포함) 이기 때문에 어떤 위치 (c+tv) 에서 해당 SDF 만큼 이동해주면 표면에 다다를 수 있다. 이 때 SDF가 떨어진 거리만을 의미할 뿐 방향은 외부/내부 수준으로 밖에 못 알려주기 때문에 SDF의 gradient를 이용하여 표면까지 방향을 추정하고 이동한다. 이게 수식(3)의 의미다.

normal은 위 수식(3)으로 찾은 surface point 위치에서 다시 SDF 값을 읽고 그 gradient를 계산해주면 된다.
Neural Renderer (Color network)
NeRF와 달리 volume density와 color 조합이 아니고 SDF, surface point, surface normal, color (+geometric feature) 조합이기 때문에 pixel color를 만드는 방법이 조금 달라야 했다.

그 방법은 BRDF다. (나도 정확히는 BRDF가 뭔지 아직 잘 모르지만) 대충 surface point(혹은 초근접)에 특정 색깔을 내뿜는 조명이 있다고 생각하고 이 조명의 빛이 이미지에 맺혀 pixel color가 된다고 모델링한 것이다. 결국 network가 추정하는 숫자 추정하는 것은 똑같지만 그 숫자의 의미가 BRDF이도록 했다.
이전 NeRF는 ray를 따라 쭉 공간의 volume density와 color를 누적하여 pixel color를 만들었지만, IDR는 오로지 surface color를 찾아 pixel color를 만든다. (내 생각이지만 이렇게 color도 허공의 영향을 안받고 물체 표면에만 영향을 받도록 모델링한 것이 3D geometry를 찾는데 더 도움이 되었을 것이라고 생각한다.)

저자가 강조하는 것은, surface normal과 camera pose에 따라 같은 조명이라도 다른 pixel color로 만들 수 있는 것이 당연하므로, surface normal와 camera pose (특히, view direction)이 중요하다고 한다. 그래서 네트워크 입력으로 꼭 surface normal과 view direction을 포함하라고 한다.
Tips

3D geometry에 초점을 맞추어 촬영한 물체의 3D 복원을 목표로 한다면 이미지에서 물체만 예쁘게 mask를 따서 사용할 수도 있다. 그렇다면 마스크에 해당하지 않는 부분은 학습할 필요도 없다. 마스크에서 벗어나 있다면 표면에서도 벗어났다는 의미다. 따라서 indicator를 두어 만약 3D point (X,Y,Z)가 마스크를 벗어났다 싶으면 제외하는 식으로 학습하면 더 좋다고 한다. 0,1 binary로 만들어버리면 differentiable하지 않아 귀찮으므로, 수식(7)과 같이 재정의하는 식을 추천한다.
Loss

loss는 별 볼 것 없다. NeRF 기반은 어쨌거나 저쨌거나 입력 이미지의 pixel color 로 supervision을 제공하기 때문에 동일하다. SDF-light field로 이어져 만들어진 색깔과 이미지의 색깔이 갖도록 하면 된다. 학습 부스팅을 위해 마스크가 있다면 tips에서 설명한 마스크 활용을 loss화 해서 추가하면 좋다.

마지막 텀은 eikonal loss라는 것인데 하나의 regularization term이다. SDF gradient 크기를 1로 제한해서 급변하는 surface를 막고 안정적으로 수렴할 수 있도록 도와준다. (추후 논문에서 강조되겠지만 이 loss term의 효과가 엄청 좋다.)
Results


