HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching

내 맘대로 Introduction
이 논문은 CVPR 2019년에 발표된 논문인데 일단 구글에서 쓴 논문이어서 신뢰도가 그냥 높다. Stereo depth estimation에 관한 논문이고 passive stereo를 딥러닝 써서 잘 해보자는 논문이다. 정확히는 stereo matching을 다룬다. passive stereo는 일반적으로 cost volume을 쌓는 형태가 많은데 이 때 감당해야 할 메모리 사용량과 느린 속도 문제를 해결하는 것에 주 목표를 둔 것 같다. 간단히 contribution을 정리하면 다음과 같다.
- A fast multi-resolution initialization step that computes high resolution matches using learned features.
- An efficient 2D disparity propagation that makes use of slanted support windows with learned descriptors.
- State-of-art results in popular benchmarks using a fraction of the computation compared to other methods.
다시 말하면 disparity initialization을 효과적으로 해서 cost volume을 local하게만 작게 만들어서 연산량을 획기적으로 줄인다는 것과 그 방법론을 pyramid 구조에 잘 녹여내서 coarse-to-fine 의 장점을 같이 취하겠다인 것 같다.
핵심 내용
1. 전체 파이프 라인 overview

left/right 이미지 2장에 각각 Unet을 이용해서 feature를 multi-resolution으로 잘 뽑아서 만들어 둔 뒤, low resolution의 feature부터 이용해서 disparity initial 값을 계산한다. high resolution까지 한다면 총 dispairty initial 값은 level 별로 L개 존재한다. 이후에 low to high resolution으로 아까 구한 disparity 값을 합쳐나간다. (propagation) 다 합치고 난 뒤에는 GT로 supervision을 걸어준다.
여기서 핵심은 어떻게 initialization을 하는가? 와 어떻게 propagation 하는가? 이다.
2. Feature extraction

모두가 알고 있는 Unet 구조이고 각 level 간 resolution 차이는 height, width 가 각각 2배씩 늘어나고 주는 구조다.
3. Disparity initialization

기본적으로 이 논문에서는 이미지를 tile로 쪼개서 다루는데 원본 해상도일 때 4x4 pixel을 한 tile로 정의했다.
각 tile마다 disparity와 feature가 있고 이를 concat해서 hypothese, h라고 정의한다. (논문 표기는 다음과 같다.)

여기서 두 개의 0이 들어간 부분은 각각 dx, dy 인데 disparity gradient을 의미한다.
disparity gradient 혹은 disparity space란 단어가 생소하다면 https://ieeexplore.ieee.org/document/4732105 논문을 참고하면 될 것 같다. 여기서 tile이 slanted plane이다.
이 hypothesis를 지속적으로 update해나가는 식으로 결과를 얻어내는 방식이다. (optimization으로 업데이트하는 것이 아니니 착각하지 말고 network한테 residual을 예측하도록 해서 더해줌으로써 update해나간다.)
Disparity 초기화 과정에서 disparity 초기값만 결정하는 것이 아니라 위 tile마다 hypothesis를 전부 초기화하는 것이라고 보면 된다.
방법은 다음과 같다.
Unet의 결과로 얻은 image feature는 이미지와 해상도가 같은데, 타일마다 feature가 있는 컨셉으로 만들기 위해서 stride 4x4인 convolution을 통해 tile feature를 만든다.
이 때 하나의 trick으로 reference image가 되는 left image는 stride 4x4, source image가 되는 right image는 stride 4x1로 convolution 한다. 결과적으로 left tile feature는 [H/4, W/4] 이 되고 right tile feature는 [H/4 W]가 된다.
그 이유는 reference tile feature은 원래대로 coarse 해도 되지만 비교 대상이 되는 source tile feature는 다양한 disparity에 대해 dense하게 표현이 되어있도록 하기 위함이다.
height 방향으로는 그럼 왜 left, right 차이가 없느냐라는 질문에는 스테레오 카메라가 좌우로 설치되어 있고 이미지가 recitification된 상태로 들어온다고 가정하기 때문에 비교는 수평 방향으로만 이루어진다. 따라서 수직 방향에서 더 많은 비교를 하기 위해 feature map 해상도를 높일 필요가 없다.
그림으로 보면 다음과 같다.


feature map을 얻은 이후에는 위 수식에 따라 cost를 계산해서 disparity initial 값을 찾는다.
왼쪽으로만 search하는 이유는 왼쪽 카메라 이미지에 보인 것을 오른쪽 카메라 이미지 상에서 찾을 때 무조건 더 왼쪽에 있다는 것을 알기 때문이다.
dx, dy (gradient of disparity)는 0, 0으로 초기화 한다.

p_init 은 앞서 구한 cost를 left tile feature와 concat한 뒤 MLP를 통과시켜 만든다.
3. Propagation
위 과정을 통해 각 level (각 resolution)에 대해 hypothesis 초기값을 갖고 있을 것이다. 근데 이미지에서 보면 같은 위치에 대해서 각 level 별로 초기값이 있으니 L개의 결과가 있는 것이다. 한 위치에 대해 존재하는 L개의 초기값을 "잘" 합쳐서 1개로 만드는 과정이 Propagation이다.
일단 "잘" 합치기 위해서 저자가 선택한 방법은 먼저 각 level이 갖고 있는 hypothehsis 초기값 중 어떤 것이 더 가중치가 높은지 cost를 계산했다.
이해를 돕기 위해 직접 그림을 하나 그렸는데 다음과 같다.
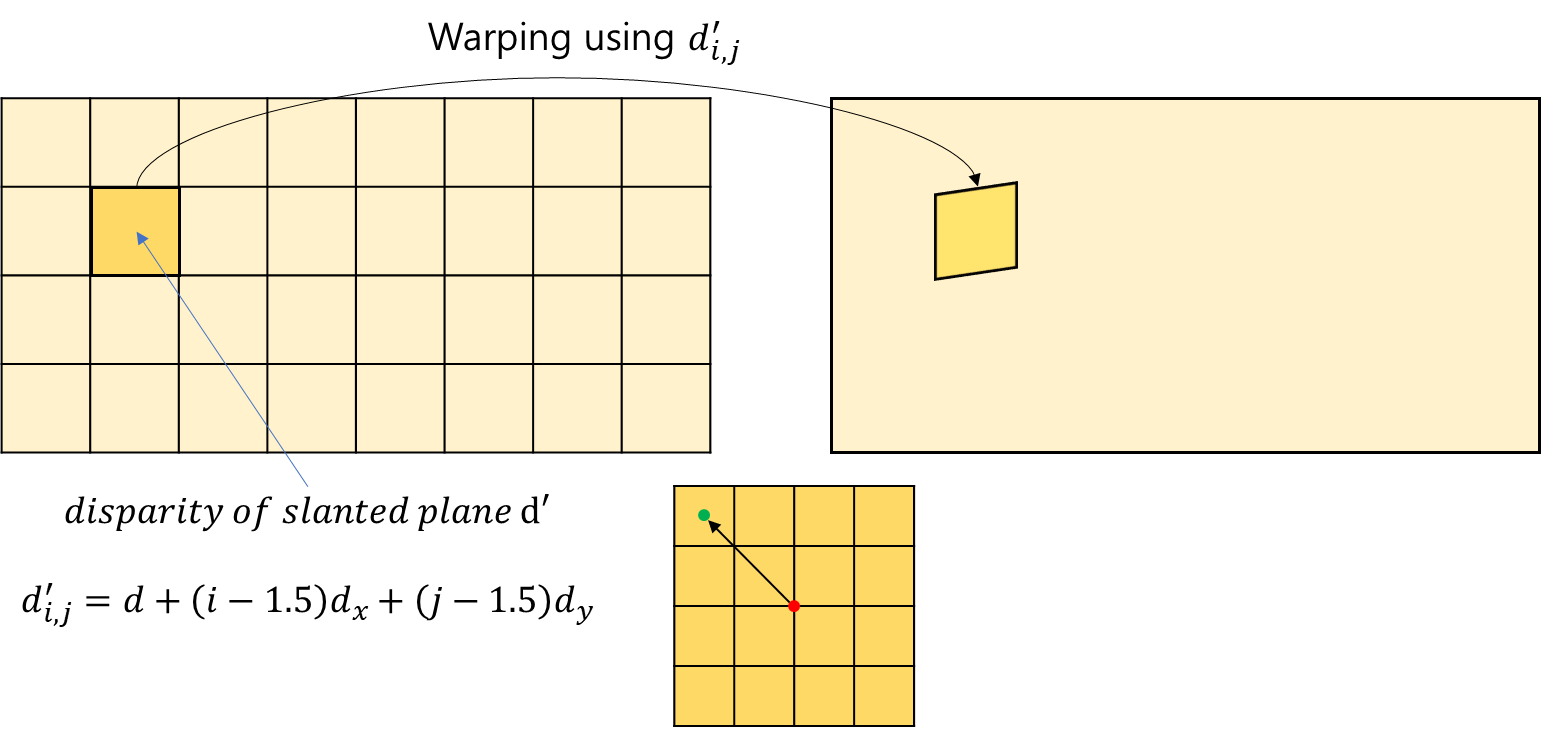
한 level에서 tile 하나를 기준으로 보았을 때, 해당 tile이 갖고 있는 hypothesis를 이용해 slanted disparity plane을 만든다. gradient of disparity를 알고 있으니 위 수식과 같이 구할 수 있을 것이다. 이 때 1.5가 등장하는 이유는 plane의 사이즈를 4x4로 정의했고 pixel의 중앙을 index가 가리키는 위치로 정의했기 때문이다.
이후 disparity를 이용해 이를 오른쪽으로 warping 하고 해당 위치의 feature를 가져와서 왼쪽의 자기 자신과 비교한다. 그리고 그 차이를 cost로 정의했다. hypothesis가 가정하는 disparity가 정확하면 이를 이용해 warping하고 비교했을 때 차이가 적어야 된다는 논리다.

이렇게 각 level마다, tile마다 전부 다 cost를 계산해서 level 간 hypothesis의 가중치를 비교하는 컨셉이다.
기본 컨셉은 그렇고 구현 상에서는 추가적으로 저자는 한 단계 더 나아가 더 강건한 비교를 위해서 hypothesis가 갖고 있는 disparity 값에서 -1, +1을 했을 때의 cost도 같이 보았다. 마치 local cost volume이라고 보는 것이다.
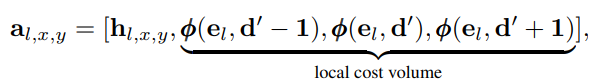
비교하는 방식은 단순히 cost를 argmin하지 않는다. end-to-end learning을 위해서 네트워크에게 맡긴다. 그래서 위와 같이 a 라는 augmented tile hypothesis를 만들고 이를 MLP를 태워 hypothesis residual을 계산한다.

여기서 a가 하나만 들어가는 것이 아니라 여러개 들어가는 이유는 아래 그림을 참조하면 된다.

가장 낮은 resoluton (가장 높은 level)에서는 하나만 들어가는게 맞다. 하지만 더 낮은 level과 합쳐질 때마다 1개씩 추가되므로 이 과정을 수식으로 표현하다보니 수식(8)에는 항이 여러 개인 것이다.
최종적으로 나온 n개의 hypothesis에서는 weigth가 가장 높은 winner-takes-all 전략으로 선택한다.
실제로 구현적으로는 각 level을 통과할 때마다 winner-takes-all 전략으로 합쳐서 매 level마다 항상 n=2가 되도록 유지한다.
4. Loss
Intialization Loss
일단 disparity에 supervision을 당연히 제공한다. 단 GT는 float disparity인데, 네크워크에서 disparity를 index로 활용했기 때문에 integer disparity다. float-int 간에 supervision을 효과적으로 제공하기 위해 interpolation을 이용한다.


형광펜으로 표시된 뒷부분은 핵심은 아니고 support하는 역할인데 의미만 해석해보면, 정확한 disparity gt 근처에서 오히려 loss를 더 발생시켜 완전 정확한 disparity가 아니면 수렴하는 일이 없도록 하는 것이다.
Propagation Loss
tile마다 갖고 있는 hypothesis를 이용하여 warping하고 cost 계산하고 이런 복잡한 과정을 했었는데 그 과정이 정확한지 supervision을 제공하는 것이다.


hypothesis로 만든 dispairty plane이 dense한 GT와 맞는지 l1 loss를 계산한다. 위 initialization loss는 tile이 갖고 있는 disparity 값만 loss에 사용했다면 이 loss는 tile이 갖고 있는 dx, dy도 사용한다고 보면 된다.
동시에 dx, dy에 대한 gt가 있다면 직접 추가 loss도 부여한다.
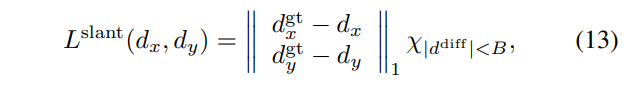
뒤에 붙는 X는 indicator function으로 값이 B보다 작으면 0이 곱해지도록 만들어서 loss를 무효화한다. dx, dy 는 값이 작을 때만 supervision이 동작하도록 유도했다.
마지막으로 cost를 계산할 때 가중치도 같이 예측하도록 했는데 가중치는 0~1 범위에 있어야 하고 binary로 나뉠 수록 좋기 때문에 다음과 같은 loss도 부여한다.

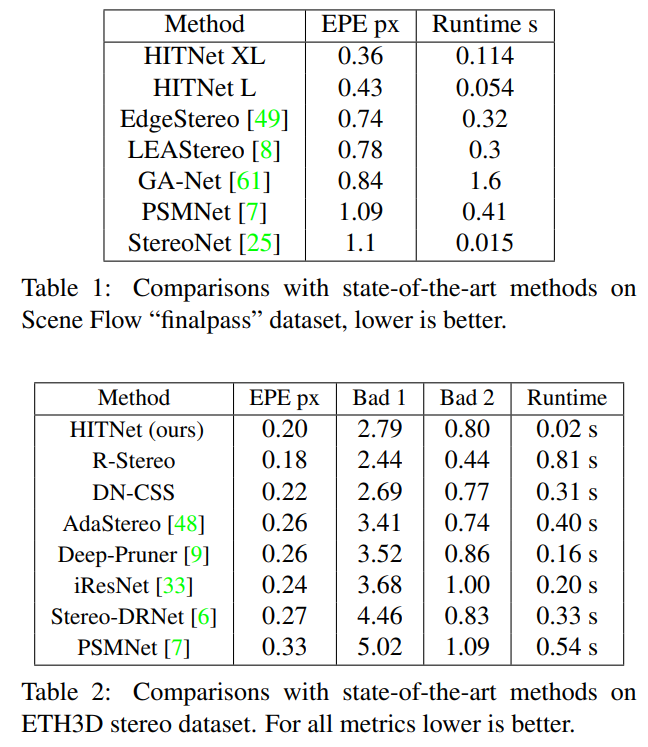
5. Result
결과는 보면 되니 설명은 생략한다.