반응형
내 맘대로 Introduction

우연히 발견한 논문인데, 오랜만에 원론적인 고민을 한 사람을 만난 것 같다. 이 논문은 "이미지가 비슷하다"를 집요하게 파고 들어 비슷함에 대한 metric을 만들고자 했다. 우리가 흔히 LPIPS나 CLIP/DINO/SAM 등 foundation model feature의 cosine similarity로 이미지의 비슷함을 가늠하곤 했는데 이 사람은 이게 효과적임을 인정함과 동시에 의문을 품었다. 비슷하긴 한데 어떻게 비슷한건데? 결국 사람이 보기에 비슷한 거랑 일치해야 하는거 아니야? 라고.
그래서 이 사람은 SD에서 같은 category로 만들어 낸 무수한 이미지 triplet을 갖고 "진짜" 사람한테 시켜서 데이터를 구성한 뒤, 이 데이터를 갖고 각 feature extractor들을 tuning해보았다. 그래서 정말 사람이 인식하는 비슷함과 cosine similarity가 비례하도록 만들어보았다.
이걸 어따 쓰냐고 할 수 있겠지만, 이런 원론적인 고민은 반드시 필요하고 분석과 실험이 쌓여나가다 보면 나중엔 정말 하나의 척도가 될 수도 있을 것 같다. 아주 훌륭한 질문을 던지는 논문이라고 생각한다.
메모
  |
사실 이 논문은 실험 논문에 가깝다. 사람의 직관을 반영한 데이터를 확보하고 이를 갖고 네트워크를 학습시켜보는 과정 뿐이다. 확실히 다른 알고리즘 제안 논문하고 컨셉이 다름. 1) SD 1.4 갖고 an image of a <category> prompt로 이미지 막 생성 -> 대충 보면, pixel level에서 변화도 아니고 객체가 바뀌는 수준도 아니고 딱 중간 수준, 비슷하게 보이긴 하지만 객체의 종류나 전체 구조, 색상톤 등은 다른 mid-level 차이로 생성이 주로 되더라 -> 비슷하긴 하나 인간 직관과는 아직 거리가 있다는 것을 시사. |
  |
|
  |
데이터셋을 구성하는 과정은 총 2가지 기준을 따른다. 1) 기준 이미지 1장, 비교 이미지 2장을 주고 더 비슷한 것 고르기 -> 더 비슷한 것이 1, 아닌 것이0 -> 여러 사람이 공통된 결과를 내뱉어야만 통과 -> 중간중간 낚시 사진 넣어서 틀린 사람 결과는 다 버림 -> 한마디로 개빡세게 검열함 |
 |
2) 0.5초 시간차를 두고 A-B-A'-B' 이런식으로 번갈아 보여주고 A-A', B-B'가 유사한지 아닌지 판단 -> 빠른 시간 안에 직관적으로 판단했을 때도 유사해야 함. -> 인간 직관이 동작해서 이미지가 비슷하다고 판단할 가능성이 높음 -> 생각없이 비슷하다고 고른 이미지들. |
  |
이렇게 선별 완료된 이미지를 갖고 DINO/CLIP 같은 Feature extractor들을 튜닝함. 일단 similarity measure는 cosie simlarity 그대로 사용함. |
 |
구체적으로 여러 feature extractor를 동시에 ensemble로 씀 feature를 죄다 concat하고 concat된 거대 feature를 갖고 cossim을 계산하는 식 trimplet loss처럼 margin을 두고, 더 인간직관에 가까운 sample에 가깝도록 유도하는 방식 LoRA를 붙여서 학습하는 방식으로 해서 본 모델이 먹었던 데이터를 훼손하지 않도록 했다. |
 |
확실히 인간 직관 데이터를 먹인 애로 학습을 하면 "비슷함"을 인간 기준으로 계산할 수 있게 학습이 된다. 당연할 수도 있는데, 그냥 검증 수치 뽑아서 보여준 것. 이게 갖는 의미는 튜닝된 앙상블 모델은 인간 직관에 대응되는 feature를 뱉도록 되었다는 것. ->이미지를 대표하는 feature로 훌륭하다. |
 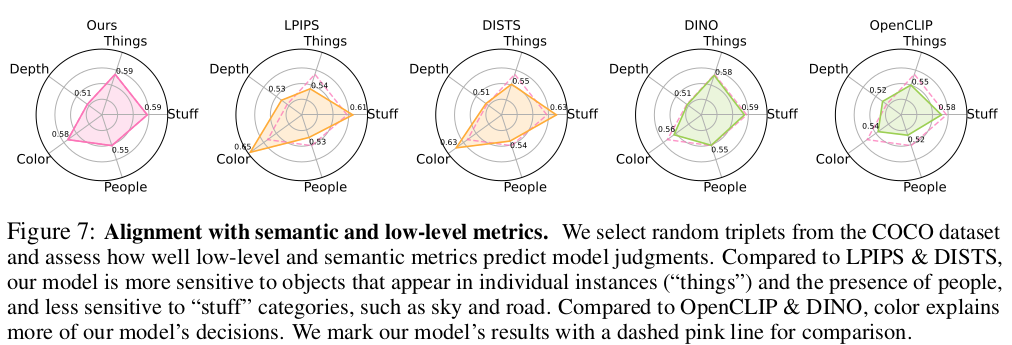 이렇게 보면 큰 차이 없어보이지만, 어떻게 인간 직관을 그림으로 표현할 수 있겠는가. 위 정성적 결과를 더 참조하는 것이 좋아보인다. |
 user study에서 압도적 차이가 있다는 건 확실히 인간이 보기에 비슷했다는 것. |
 |
나중에 이미지 similiarity measure를 loss로 써야 하는 상황에서 참조하기 좋은 연구가 아닐까.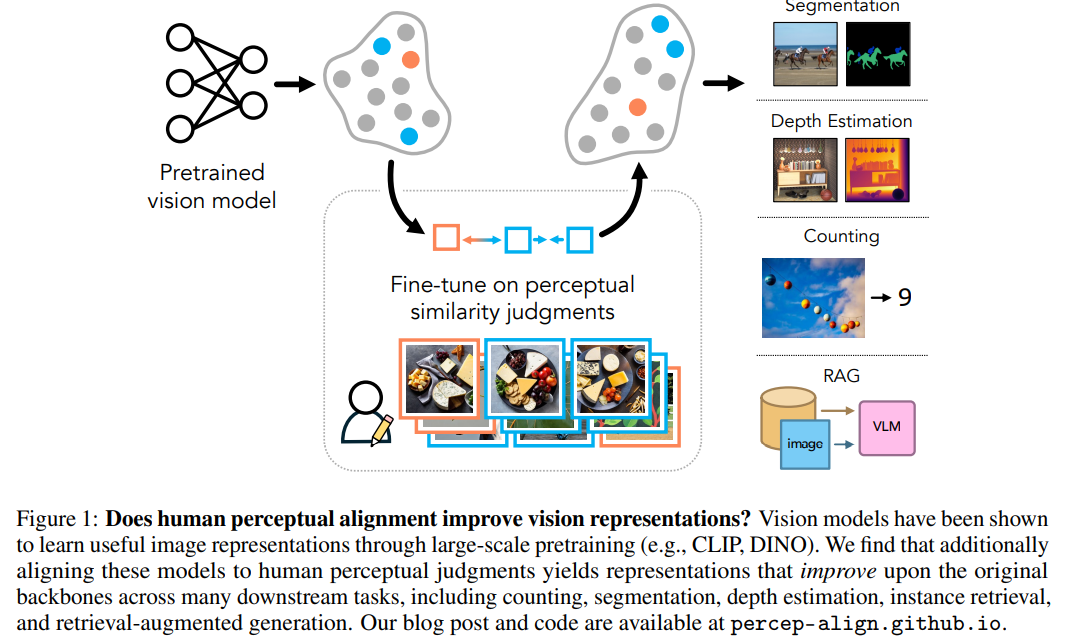 참고로 When Does Perceptual Alignment Benefit Vision Representations? 라는 제목으로 후속 연구가 있는데, 인간이 이미지를 이해하는 방식과 유사하게 학습된 backbone은 실제로 다른 task에 좋은 영향을 미치는가? 라는 질문을 검증해본다. 논문 주장으로는 도움이 된다는 것 같은데, 참 깊은 의미의 연구를 하는 사람이다 싶다. |
반응형
'Paper > Others' 카테고리의 다른 글
| Neural Implicit Surface Evolution (0) | 2025.06.10 |
|---|---|
| Harnessing the Universal Geometry of Embeddings (0) | 2025.05.30 |
| AM-RADIO: Agglomerative Vision Foundation Model Reduce All Domains Into One (1) | 2025.04.08 |
| PointMamba: A Simple State Space Model for Point Cloud Analysis (2) | 2025.04.04 |
| Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling (0) | 2025.03.27 |