반응형
내 맘대로 Introduction

논문에 face가 들어가서 face recognition이 본체인 것 같지만 사실 additive angular margin loss가 본체다. triplet loss와 같이 positive 대상과는 가깝게, negative 대상과는 멀게 embedding해야 하는 상황에서 쓸 수 있는 loss다. 조금 오래 된 논문이기도 한데 뒤늦게 읽었다. 엄청 유명한 방식.
log-softmax와 비슷한데, 단순히 값을 input으로 넣는 것이 아니라, learnable embedding N개를 만들어두고, 가까운 embedding과의 "각도"의 cosine 값을 사용한다. 직관적으로 보면 feature 간의 각도를 벌리도록 설계하는 것. 여기다 마진을 조금 더 더해주면 분별력이 많이 향상된다는 것이 핵심
메모
|
|
|
classification을 푼다고 하면 softmax가 거의 정석이다. 하지만 이 방식은 N이 늘어날수록 효율이 감소하고, feature 혹은 embedding 간의 관계는 명시적으로 컨트롤하지 않기 때문에 비슷한 샘플의 feature가 가깝다고 보장할 수가 없다. ------------ 이 문제를 풀기 위해서 각도 개념을 제안한다. learnable embedding N개 (필요한 차원만큼 미리 생성) 과 feature 간의 각도 값을 softmax의 value 대신 사용하는 것 (수식2를 보는 것이 더 빠르다.) numerical 안정성을 위해서 scale factor s가 추가됐고, 각도 차이를 벌릴 때 margin을 두고 더 강하게 벌릴 수 있도록 각도 값에 margin을 더해주는 것이 최종 형태가 되겠다. 여기서 +0.5로 고정되어 있는 이유는 arccos으로 각도값을 구하는데 arccos는 0~pi 이기 때문이다. |
|
직관적인 그림을 보면 분명하다. feature가 margin을 두고 분리되도록 수렴함. |
  |
 비슷한 컨셉이 없진 않았따. 각도를 다루는 식의 논문이 여러개가 있고, 각각 margin이 어디에 들어가느냐 차이인데 m1, m3가 기존 논문이다. 하지만 m2 위치에 더하는 것이 효과가 뚜렷함. 3가지 margin을 조화롭게 조절하면 됨. |
 그림으로 봐도 m2 위치에 더해주는 것이 feature 간의 간격을 깔끔하게 가르는데 더 도움이 됨. |
  |
 |
추가적으로 같은 class끼리를 각도가 가깝게, 다른 class끼리는 멀게 보강할수도 있다. (뒤에 후술하는데 큰 효과는 없다고 함) |
  |
더 성능 향상에 기여하는 것은, N개의 learnable embedding을 NxK로 확장해두는 것. 같은 class 라도 K개 가능성을 열어두는 것. (얼굴 인식에서는 K개 중 일부가 가려진 얼굴, 선글라스 등을 담당하도록 수렴함. 나머지 가 더 집중하면서 성능이 향상됨) K dimension 방향으로 max pool만 추가해주면 됨. |
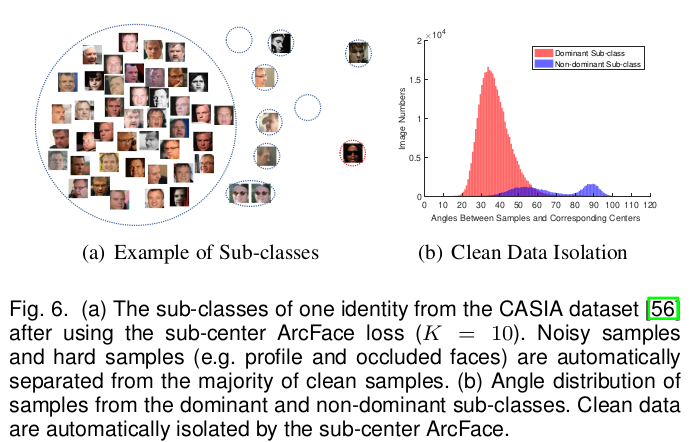 이렇게 하면 확연히 쓰레기 데이터들이 떨거지 K 에 할당돼서 분리가 극명하게 됨. |
 확연하게 noisy prediction이 줄어듦. |
 |
|
 |
 |
반응형