반응형
내 맘대로 Introduction

NPHM 이 나온지 1년만에 같은 저자가 NPHM++과 같이 새 논문을 내었다. 제목도 그렇고 마치 주어진 비디오의 정보를 이용해서head model을 만드는 것 같지만 아니다. 모델은 NPHM처럼 따로 존재하고, 이걸 모든 비디오 프레임을 이용해 동시에 최적화+트래킹한 뒤, canonical model만 꺼내는 식으로 얻어내는 것이다.
핵심은 NPHM과 같은 모델을 학습한 것. 그럼 NPHM을 가져다 쓴 것이냐? 새로 학습했다. 그 생각엔 크게 없다. apperance(color)를 표현하는 texture space를 추가하고 싶어서 새로 한 것 같은데, 사실 비디오에 fitting할 때 keypoint만 갖고도 할 수 있으니 NPHM으로도 같은 결과물을 얻어낼 순 있을 것 같다.
canonical-to-deformed (forward deformation)이었던 NPHM을 deformed-to-canonical (backward deformation)으로 바꾼 것도, 직관적으로 deformed image 가 입력이므로 여기에 맞춘 것 같고 뒤집으나 안뒤집으나 어차피 나중에 inversion으로 풀어주는 거니까 큰 차이는 없는 것 같다.
NPHM 대비 향상된 부분은 texture space를 추가해서 photometric loss를 사용할 수 있게 됨으로써 tracking 성능이 조금 더 올랐다 정도인 것 같다.
메모
 |
|
  |
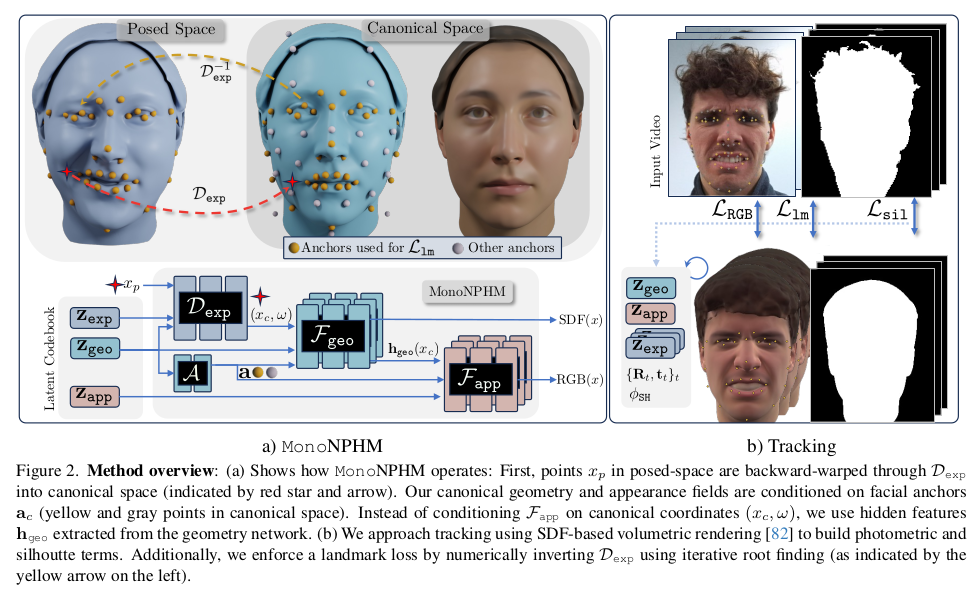
핵심이 되는 implicit model function, monoNPHM은 크게 3개로 구성됨 1) geo mlp : canonical geometry 2) app mlp : canonical appreance 3) exp mlp : defomred to canonical 특이점은 NPHM과 달리 exp mlp가 deformed query point를 입력으로 받고, canonical까지 이동하는 역방향 deformation을 뱉도록 학습된 다는 것이다. 4) kp mlp : canonical geo latent -> canonical keypoints. |
 사소하게는 NPHM보다 keypoint anchor 개수를 늘렸다. 늘어난 anchor 개수마다 MLP를 두면 네트워크가 너무 거대해지므로 여기선 8개씩 묶어서 MLP를 두고 ensemble했다. 이 때 추가된 additional keypoint(회색 위치)는 분포가 기존 keypoint(노란색)보다 넓으므로 blending할 때 사용하면 blend weight를 살짝 손질해줘서 멀면 먼게 더 명확하게 반여되도록 값을 업데이트해줬다. |
 |
 |
큰 NPHM과 차이점. 바로 appearance (texture) space가 추가됐다. 1) geo mlp에서 나온 마지막 layer feature 2) app latent를 입력으로 받아 색상을 구한다. |
 |
exp mlp 는 deformed position - > canonical positon을 예측함. 이 때 canonical position만 뱉지 않고 extra feature를 뱉도록 해주는 것이 뒤에 geo mlp에 도움이 된다고 함. |
  |
학습할 때 기존과 달리 2 stage로 나눠서 할 필요가 없다. 학습 subject id마다 이전에는 분리를 했었는데, 여기선 geometry라고 퉁치면서 subject 를 크게 분리하지는 않고 대충 알아서 geometry space를 배우도록 함 그래서 subject 가 좀 섞이더라도 어차피 geometry 표현력만 좋으면 되니까 굳이 나눠서 하지 않았음. sdf랑 pixel loss로 학습. |
 |
비디오 입력이 들어오면 이젠 모델에서 texture가 나오니까 photometric loss silhouette loss keypoint loss regularzation으로 최적화해서 geo, exp, app latent를 찾는 방식 이 때 geo latent가 이제 더 이상 subject id를 의미하지 않으므로, 모든 프레임에서 같아야 된다는 loss 도 필요없음. |
  |
아웃풋을 렌더링하는 방식은 NeuS 수식을 통해 sdf to opacity -> color accumulation -> image |
 |
실제 렌더링할 때 그냥 model albedo로 렌더링하면 부자연스러움. 따라서 렌더링할 때 조명이 존재한다면 색깔 앞에 SH(normal) 곱해줘서 자연스럽게 색상 변화 후 렌더링 |
 |
texture랑 silhouette이 있으니 2D level에서 사용한 loss |
 deformed keypoint를 deformation field로 옮겨오면 canonical keypoint랑 일치해야 함. |
 각 파라미터의 크기는 0에 가깝도록 하며, temporal 하게 값이 비슷해야 한다. |
 |
|
 |
 NPHM을 사용한 결과는 왜 없을까. |
 |
 |
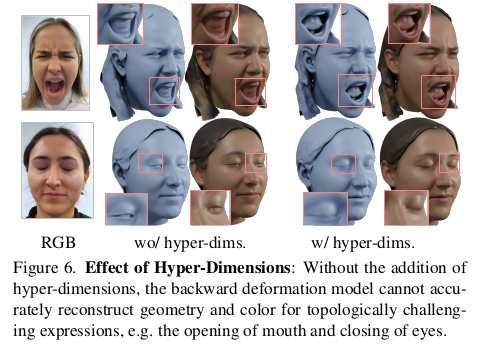 |
canonical point 예측 할 때 geo feature를 꺼내주는 사소한 트릭의 효과가 이렇게 크다고 한다. 마치 MLP에서 position feature 꺼내주는 것과 같은 듯. -------------------------------------------------------- 이게 실험 결과로 보면 효과적이긴 하다면, 그래도 5200 SCAN을 이용해 255명으로 만든 space여서 확실히 generalization 이슈가 있을 것 같긴 하다. 특히 hair까지 포함했기 때문에 모델 capacity가 많이 소모되었지 않을까. texture도 마찬가지. 따라서 조명이 SCAN 환경과 많이 다른 비디오 이미지에서 texture loss가 잘 동작할 수 있을지 모르겠다. 동양인 데이터로 테스트해보고 싶다. |
반응형