반응형
내 맘대로 Introduction

이 논문은 head parametric model을 implicit function 형태로 만든 논문이다. 어떻게 보면 imGHUM 과 맥락을 같이 한다고 볼 수 있지만 기존의 explicit mesh model을 implicit하게 변형하는게 아니라 애초에 처음부터 3D SCAN 데이터를 갖고 새로 만드는 것이기 때문에 차이점이 명확하게 있다.
PCA 기반 방식의 smoothing되고, 지나치게 평준화된 결과에서 벗어나 implicit function 형태 (deformable NeRF MLP들)로 표현함으로써 좀 더 디테일한 표현이 가능하게 됐고, 해상도 또한 자유롭게 조절할 수 있게 되었다.
아무래도 파라미터가 PCA 파라미터가 아니므로, 파라미터를 직관적으로 다루기가 어렵긴 하겠다만 어차피 전부 inversion 최적화로 다시 풀어낼 것이기 때문에 크게 문제는 아닌 것 같다.
이 논문은 기존의 모델 생성 방식을 Neural net.화하는데 완성도 있게 만든 것을 인정받아 게재되었다.
PCA 모델은 template -> shape 변형 -> expression 변형이지만 이 모델은 identity 부여 -> 해상 subject canonical -> expression 변형 순서다. shape이 identity에 들어가있다고 보면 된다.
메모
 |
|
 |
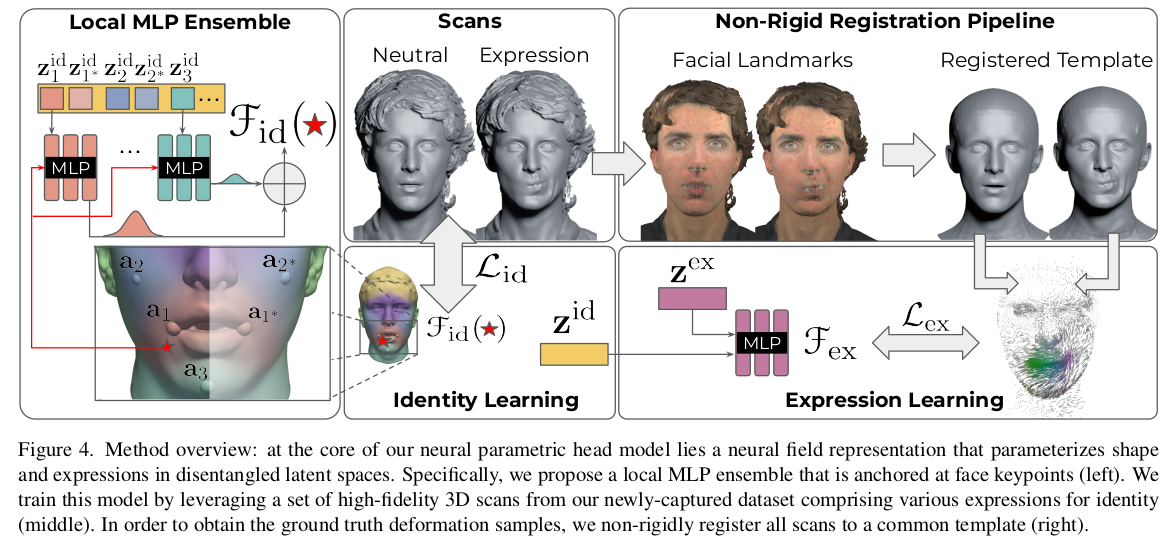
255명 남자 188 : 여자 67 비율로 직접 찍었고, 총 5200 스캔. 특이 사항은 neutral pose를 입을 닫고 찍었다는 것. 이건 바로 이해가 되는데, 뒤에 네트워크를 SDF를 내뱉도록 설계했기 때문이다. SDF는 안팎 구분이 명확히 되어야 정의할 수 있기 때문에 mesh가 water tight 형태여야 한다. 입 닫고 있을 때야 괜찮지만 표정 변화하면서 입이 떨어질텐데, 그 때 입술 사이에 mesh가 없다면 표정 변화 이루어진 애들의 SDF를 계산하기 난해하므로 무표정에서 입술 사이 공간을 미리 닫힌 공간으로 만들어 둘 수 있도록 입을 열라고 한 것 같다.  SCAN 퀄리티가 좋은 편인데, Artec Eva라는 2800만원짜리 센서 기반으로 했다... 개비싸네 |
  |
registration부터 적어놔서 편하다. 보통 건너뛰는데. media pipe로 keypoint 48/68 개 잡고 3D Keypoint랑 projection error 최적화하는 방식으로 대충 맞춤. 이 때 3D Keypoint도 없을텐데, 이건 SCAN을 렌더링해서 만든 이미지를 갖고, 2D-to-3D backprojection해서 만들었다고 함. -> 정면 샷이 잘 뽑히므로 정면 이용함. |
  |
일단 머리 영역은 FLAME 모델이 대머리이므로 masking out. 여기서 identity, expression, jaw pose 파라미터를 구했다고 하는데 이건 전부 FLAME 모델 파라미터다. 뒤에 NPHM에서 쓰는 identity, expression과 다름. 일단 FLAME을 최대한 fitting했다는 뜻. keypoint loss vertex to SCAN surface distance loss parameter regularization ( toward 0)  |
  |
FLAME이 vertex가 적긴 해서 이렇게 만 하면 결과가 고해상도를 못따라감 따라서 FLAME을 subdivison 2번해서 16배 upscale 진행. as rigid as possible surface modeling 이라는 논문에서 vertex 간격은 최대한 유지하면서 rotation만 움직여서 registration하는 최적화 수식을 제안함. -> 이게 효과가 좋다고 함 많이들 reproduce해서 쓰고 있음 이걸 사용해서 최종 fine tuning. 이때는 FLAME 파라미터를 건들지 않는다. 최후 보정이라서. |
  |
앞서 말한 입벌리고 찍은 이유 등장. SDF 써서 그런게 맞았다. |
 |
|
 |
이제 vertex + id + expression -> SDF를 추정할 것인데 얼굴의 모든 영역을 각각 다 개별적으로 고려하지 않고 얼굴이 웬만하면 좌우 대칭이라는 점을 이용해서 search space를 좀 줄였다. FLAME 피팅 결과를 기준으로 정중앙 + 왼쪽/오른쪽을 나누고, 왼쪽, flip(오른쪽)를 vertex 입력으로 사용했다. 입력만 flip했을 뿐 parameter를 share한다거나 이런건 아니지만 네트워크 입장에서 입력 vertex space가 절반으로 줄어드는 효과이기 때문에 수렴이 더 잘 될 것 같다 --------- 대칭으로 옮기는건 vertex 위치만이고 나머지는 다 개별적이다. --------- vertex 위치를 네트워크에 넣어줄 때는 nearest keypoint와의 relative distance로 넣어준다. keypoint에 따라 미리 영역을 나눠두고 anchor처럼 사용함. |
  |
 앞서 vertex 위치를 anchor relative 형태로 anchor 개념을 도입해서 처리했는데, 이를 확장해서 id latent도 anchor 별로 만들었다. MLP를 여러개로 쪼개서 각각이 anchor 영역만 담당하도록 분리해서 풀었다. ensemble이라고 하는데, scope를 지속적으로 줄여주는건 수렴에 도움이 될 것 같다. 나중에 특정한 위치의 최종 id latent를 만들고 싶으면 각 anchor id latent를 거리 기반으로 blending해서 사용하는 방식이다. |
 |
expression은 anchor 단위로 분리하지 않았다. (이건 anchor 부분만 움직여서 표정 짓는 식으로 데이터가 존재하지 않기 때문에 수렴이 쉽지 않아보여서 그런 듯) 대신 앞선 anchor id latent + anchor position을 새 feature로 압축해서 global expression latent를 보조할 수 있도록 설계함. |
  |
네트워크를 학습시킬 때, id, expression을 한 번에 다 풀면 당연히 id-expression coupling 문제가 생기므로 먼저 푼다. 먼저 expression MLP를 무시한 체 무표정 데이터만 싹 긁어서 id 뽑아내는 것만 먼저 학습시킨다. canonical-to-deformed 방향이므로 canonical만 먼저 학습시키면 됨.  |
 |
그 다음은 expression에 의한 deformation 만 따로 학습 이 때 저 delta는 registration 결과를 이용해 canonical<->deformed 간의 거리를 vertex 단위로 미리 계산해놓은 것이다. vertex 중간 position들은 interpolation 으로 처리. ------------------- 이 때 앞의 id 네트워크를 freeze했다는 말이 없다. 근데 z_hat_id가 loss에 들어가있으므로 id latent도 여기서 같이 업데이트되는 것으로 보인다. id가 같은 대상에 대해서 변하지 않도록 억제하는 loss가 있는지는 모르겠다. 설명 안되어 있는 걸로 봐선 그냥 열어둔 것 같기도. --------------------- 아니면 id network freeze한 것 같다. |
 |
 |
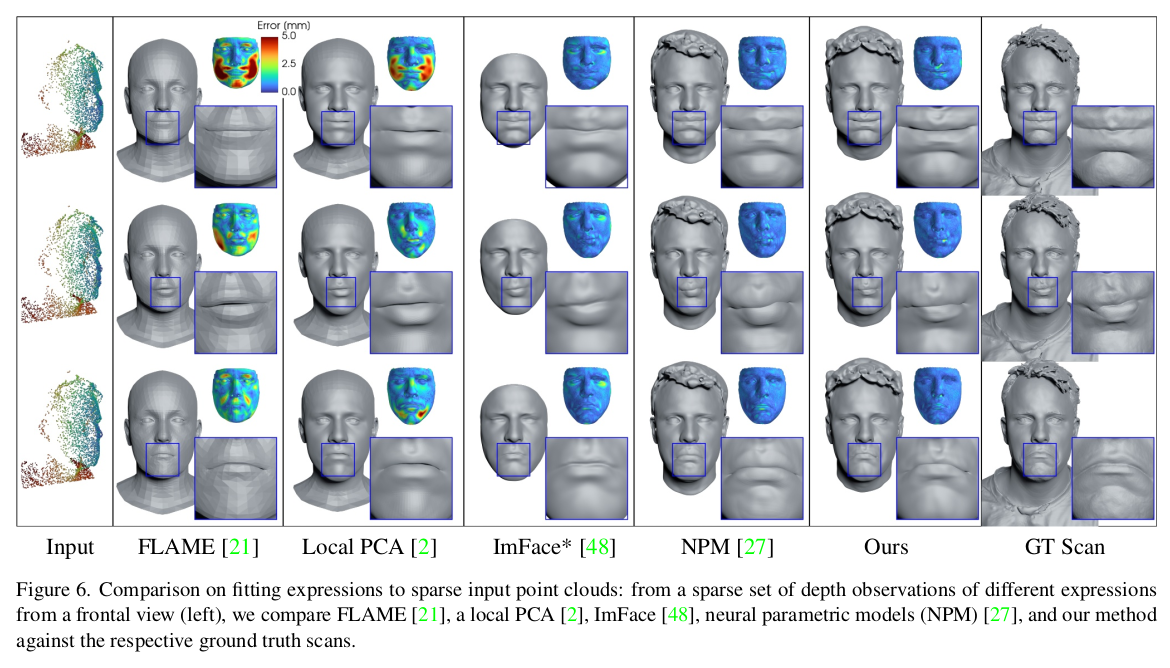
 fitting을 어떻게 했는지 그 방법론이 궁금하긴 한데. query point의 sdf가 0이 되도록 inversion한게 아닐까. |
|
 |
|
 |
 |
반응형