반응형
내 맘대로 Introduction

3D SCAN이 주어졌을 때, 이를 표현하는 implict morphable model을 만드는 방법. 3D SCAN -> canonicalize template mesh 간의 관계를 expression, identity parameter를 condition으로 학습해둔 뒤, 나중에 inference할 때는 3D SCAN query point 대신 voxel의 모든 query point를 inference 해서 결과를 얻어냄.
(학습 시에도 3D SCAN query point만 사용하는게 아니라 voxel 모든 query point를 사용함)
일반적으로 canonical to deformed 방향으로 파라미터를 찾는데, 이 논문은 deformed to canonical이라서 방향이 조금 헷갈리긴 한다. 근데 방향을 뒤집어서 학습한 건 독특한 것 같다. 이게 무슨 장점이 있어서 이렇게 했을까. 논문에는 안 나온다.
메모
 |
|
 |
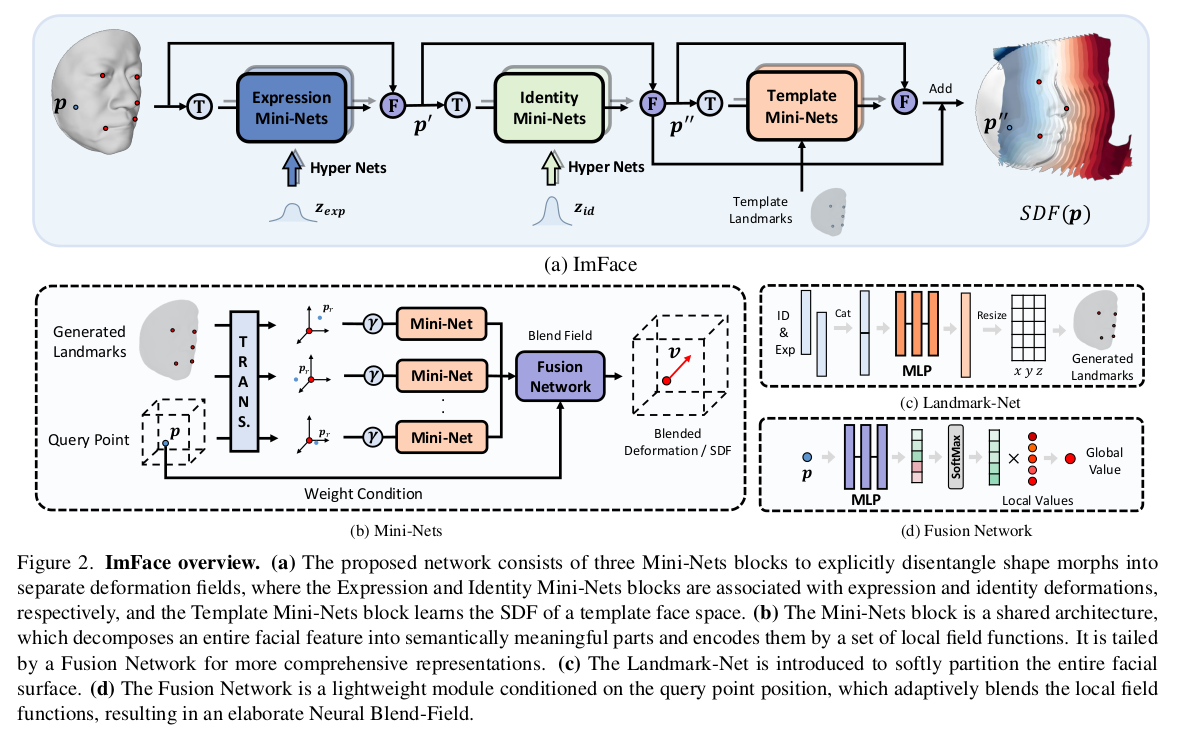
입력은 3D SCAN + SCAN을 감싸는 voxel 공간 출력은 expression, identity 파라미터를 조건으로 SCAN에 해당하는 sdf를 예측하는 implicit function 3D SCAN 공간의 query point -> sdf deformed - > canonical로 흐르는 방향이다. |
  |
3D SCAN -> expression/identity 파라미터 추가 -> canonical 로 가는 흐름인데 expression identity는 개념상 분리되어야 하기 때문에 파라미터를 따로 두고, 네트워크도 따로 두었음. -> 하지만 명시적으로 이를 분리한 결과에 걸어줄 supervision이 없기 때문에 완벽 분리는 안 될 것. -> 그렇게 되길 기대하는 방식. 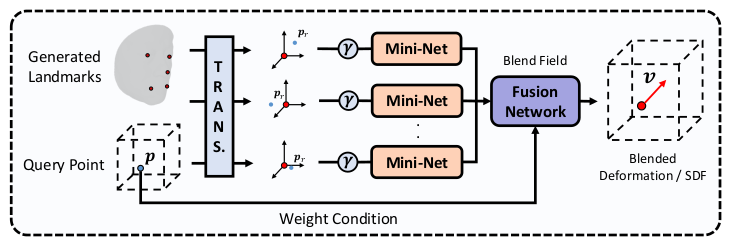 각 파라미터를 받아 canonicalize하는 구조는 위와 같음. (query point + 파라미터 처리하는 네트워크는 그림에 없음) 후술하겠지만, 그냥 query point + 파라미터 받아서 output 내면 난이도가 너무 높았는지 query point를 보조하기 위해서 현 SCAN에서 3D keypoint를 네트워크로 찾아서 넣어준 뒤, query point <-> 3D keypoint relative position을 입력으로 받는 네트워크가 추가로 붙음. |
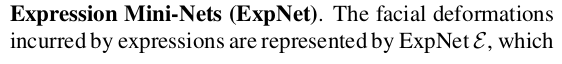  |
expression net은 1) 3D SCAN query point 2) expression param 3) 3D SCAN landmark를 입력으로 받아 표정을 없앤 무표정 query point를 내뱉도록 설계. 이 때 landmark는 expression, identity parameter를 받아 추정. |
 |
identity net은 1) 3D SCAN (no expression) query point 2) identity param 3) 3D SCAN (no expression) landmark를 입력으로 받아 개인 얼굴도 없앤 template mesh query point + displacement를 내뱉도록 설계 이 때 identity parameter만 받는 landmark 네트워크 새로 사용. ---------------- 마지막으로 무표정 template mesh query point 입력으로 받아 template mesh sdf 추정하는 네트워크 만들기. -> 이 때 template mesh sdf는 미리 계산 해두기. -> 이 sdf에 위 displacement를 더하면 무표정 개인 implicit model 완성. |
  |
 구현적 문제인데, query point를 보조할 목적으로 추가되는 landmark는 각각 relative position으로 표시된 뒤, 새로운 네트워크의 입력으로 들어가 N개의 guide feature를 만든다. guid feature는 blending 하듯이 weighted sum 되어서 합쳐짐 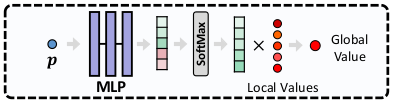 |
 |
defomration vector는 단순히 dx, dy, dz로 하지 않고 SE3로 표현함. (이게 더 추정 난이도가 쉬움) rot 3 trans 3 총 6dimension으로 다룸. -------------- 이부분이 마음에 안드는데 위 수식에서는 v만 써놓고 (w, v)로 썼다고 뒤에 와서 설명하는게 이해가 안간다. 그림에도 v라고 썼으면서 w가 여기서만 등장하고 심지어 어떻게 계산했는지 설명도 없음. 실제로는 v = (w, v)로 썼다는 듯. |
 |
파라미터 embedding은 거창하게 heper net라고 불렀다. |
  |
expression 파라미터 만들 때 그냥 무지성 gaussian 하면 파라미터 끼리 구분력이 떨어지니까 촬영할 때 사용한 6가지 표정을 애초에 분류해서, anchor 처럼 사용해서 보강했다고 한다. -------------------- 어떻게 했는지 설명이 안되어 있는데  supplementary 그림으로 추정해보자면, 대충의 centroid를 미리 지정해두고 그 주변에서 gaussian sampling해서 사용한 것 같다. -------------- 무표정일땐 expression conditioned 결과가 아무런 효과가 없도록 regularization 추가. |
  |
 loss는 다 알만한 loss라 생략. |
 |
|
 |
sdf를 사용하는 순간, mesh의 안팎 구분이 명확해야 하고, 3D SCAN처럼 watertight 형태가 아닌 경우 사용이 어려움. 그렇다고 UDF를 쓰기엔 gradient가 step function으로 나타나므로 학습이 어려움. ------------- 따라서 3D SCAN을 둘려 싸는 sphere를 만들고 , 안팎경계가 없을 경우 sphere껍데기를 경계로 사용해서 SDF를 예쁘게 정리함. |
 |
 |
  |
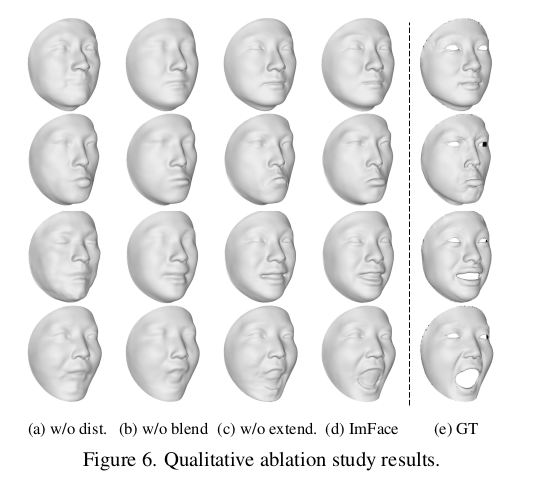 |
반응형
'Paper > Human' 카테고리의 다른 글
| Learning Neural Parametric Head Models (10) | 2024.07.11 |
|---|---|
| Reconstruction of Personalized 3D Face Rigs from Monocular Video (0) | 2024.07.10 |
| Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis (0) | 2024.07.08 |
| EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars (0) | 2024.07.08 |
| Face Reconstruction in the Wild (0) | 2024.07.07 |