반응형
내 맘대로 Introduction

네이버랩스 유럽에서 얼마 전에 냈던 DUSt3R의 리마스터 버전 같은 논문. 내용 측면에서는 크게 달라진 점이 있다기 보다 feature matching까지 추가한 확장판이다. DUSt3R + addiontal head 느낌. pointmap을 뱉어주던 기존 DUSt3R의 마지막 부분에 feature descriptor를 뽑는 head를 추가했다. 이외에는 feature matching을 brute-force nearest neighbor로 하면 너무 오래 걸리니, 어떻게 속도를 빠르게 할 수 있을지 노하우를 기록한 내용. loss도 특별하지는 않다.
메모
 |
|
 |
짙은 회색만 보면 DUSt3R과 똑같다. 네트워크도 pretrained model을 가져왔을 것이므로 100% 동일함. 옅은 회색 부분 descroptor 뽑아주는 head가 추가된 것. --------------- 3d point head 결과 건, descriptor 결과 건 cam1, cam2 간의 matching이 필요한데, 이전에는 그냥 (H*W)**2의 연산량으로 냅뒀다면 이번엔 속도를 조금 개선하기 위해서 Fast nearest neighbor를 적용했다. 요약하자면 sampling해서 (H*W/16)**2 로 한 번 돌리고 탈락시킬 pixel 탈락시키고, 나머지에서 또 sampling 하는 식으로 matching candidate를 계속 줄여나가는 식이다. cyclic consistency 불만족 시 탈락 됨. |
   |
  긴 긴 DUSt3R recap. NeRF도 그렇고, Gaussian splatting도 그렇고, 파생 논문에서 이렇게 recap으로 분량 잡아먹는거 별로인 것 같다. 차이점은 1개. scale ambiguity를 없애기 위해서 DUSt3R에서는 point 예측 후 예측된 point들의 평균 depth로 normalization하는 1/z가 추가되어있다. 근데 여기선 만일 데이터가 metric scale이 주어져있을 경우, 예측 값의 평균 depth로 normalization하는 것이 아니라 실제 depth의 평균으로 normalization 했다. |
  |
새롭게 추가된 feature descriptor head는 설계 자체는 point map head랑 똑같음 학습하는 loss는 원래라면 cross entropy로 했겠지만, 그렇게 하면 정확히 매칭되지 않고 주변에 매칭돼도 대충 loss가 줄어듦으로 1대1 match가 잘 보장되지 않는 경우가 많다. 따라서 infoNCE 논문에서 차용한 loss term, 변형 CE같은 loss로 GT supervision을 가했다. 이렇게 하면 정확히 맞추지 않으면 loss가 없어지는 형태. |
 |
|
  |
feature descriptor head가 학습이 완료되었다면, 이제 이걸 matching point 화 해야 한다. 이건 descriptor끼리 nn match 하면 찾을 수 있음 (근데 이렇게 하면 discrete matching 밖에 안되지 않나) nn match를 근데 모든 pixel 간의 통째로 하면 당연히 엄청 느릴 것. 따라서 무식하게 하지 않고, 1) stride를 두어 1/16배 sampling을 하고 먼저 적은 수의 nn을 일단 무식하게 함 (forward match, A->B) 2) B, forward matched point 를 다시 backwrad matching 수행 (B->A) 이 때 제자리로 가지 않는다면 backward matching에 참여한 pixel B들은 NN candidate에서 삭제 3) 이를 반복하면서 nn 대상 군을 줄여나감 다시 말하면 A -> B forward-backward를 거치면 일부 B의 pixel이 탈락하고 B -> A backward-forward를 거치면 일부 A의 pixel이 탈락함. 계속 줄여나가면 나중에는 nn 연산량이 엄청 줄어들걸 |
  |
transformer 고질병, 입력 해상도가 고정되는 문제. Croco를 기반으로 했으므로 입력을 224x224를 받고 있다. 근데 이미지를 224x224로 resize해서 matching 하면 discrete matching으로 나오는 형태이므로 성능이 나락갈 것. 따라서 이미지를 resize하지 않고, croco stereo나 croco flow처럼 tiling해서 승부한다. ----- 1) 주어진 이미지가 224x224보다 크다면 해당 이미지를 224x224 크기로 쪼개되 서로 overlap이 50% 정도 되게 쪼갠다. 2) 주어진 이미지를 224x224로 resize해서 matching 대충 수행. 3) coarse match 결과를 보고 위 쪼갠 cropped window 중 어떤 것끼리 matching을 수행할건지 pair 생성 4) pair 따라 matching 반복 5) 이미지 전체 90% 이상 커버했다면 중지 |
 |
 |
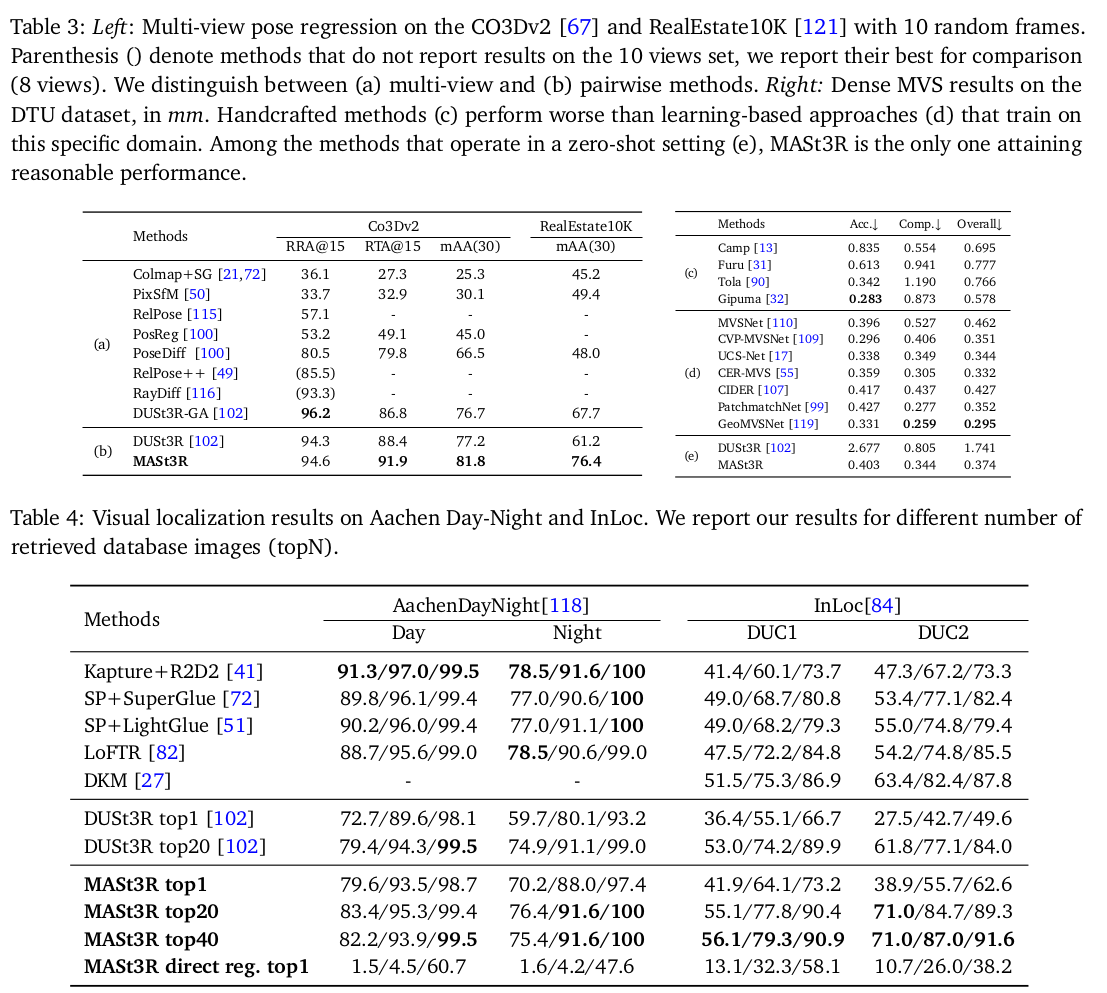 |
| DKM을 이겼다는게 사실 좀 안 믿긴다. 그정도인가...? DUSt3R가 대단하긴 대단한가 보다. |
 |
 |
 |
 convergence basins라는 용어가 좀 생소하지만, 그냥 correspondence를 찾을 때 point at A가 이미지 B 상의 어디에 매칭될지 시각화 한 것. 영역이 좁을수록 1대1 matching이 되는 것 (성능 좋아짐) 넓을수록 1대 다 matching 되는 것 (성능 하락) fast nn으로 후보군을 계속 버려가면서 (harsh)하게 loss를 먹인 효과로 basins가 좁아지는 효과가 있었다고 함. matching 될게 없는 넓은 영역은 바로 버려졌을테니 학습이 잘안됨 -> basins 넓어짐 matching 되어야 하는 대상 영역은 집중 받았을테니 학습이 잘됨 -> basin 좁아짐. |
반응형