반응형
내 맘대로 Introduction
 |
 |
이 논문은 google research에서 나온 논문으로, 이미지 to NeRF가 아닌 빛 to NeRF를 학습하는 논문이다. 다른 말로는 카메라를 이용해 센서에 담아내고 후처리를 다 해서 만든 이미지를 갖고 출발하는 것이 아니라, 센서에 담긴 raw 이미지를 갖고 출발하는 것이다.
카메라 기종마다 자체적으로 camera sensor cell에서 R, G, B, G 4개 신호 측정값을 섞어서 pixel(cell) color로 만들어내고, 이를 gamma correction 같은 후처리를 통해 이미지 빛의 세기를 반영한 보기 좋은 이미지로 바꾸어준다. 이 논문에서는 R, G, B, G 4개의 신호 측정값 그대로를 이미지(4/3배 되겠지)로 쓰고 NeRF가 R G B G 를 찾아내게 하는 셈이다.
이렇게 학습하면 좋은 점은 카메라 기종에 따라 이미지가 정해져 버려왔는데, 공간에 있는 빛 자체를 NeRF에 담은 셈이기 때문에 후처리 공정을 inference 할 때 정해주기 나름으로 새로운 이미지를 만들어낼 수 있다. 예를 들면, exposure time을 바꾼다거나 white balance를 바꿔서 전체 color tone을 바꿔준다거나, dynamic range를 바꿔주는게 가능하다.
한마디로 압축하면 이미지에서 카메라 하드웨어 특성을 빼고 빛을 담은 NeRF다.
개인적으로 역작이라고 생각하는 논문이고, 이미지만 다루는게 아니라 물리 현상까지 바라보면서 문제를 풀었다는 점에 박수쳐줄만 하다.
메모
 |
|
 |
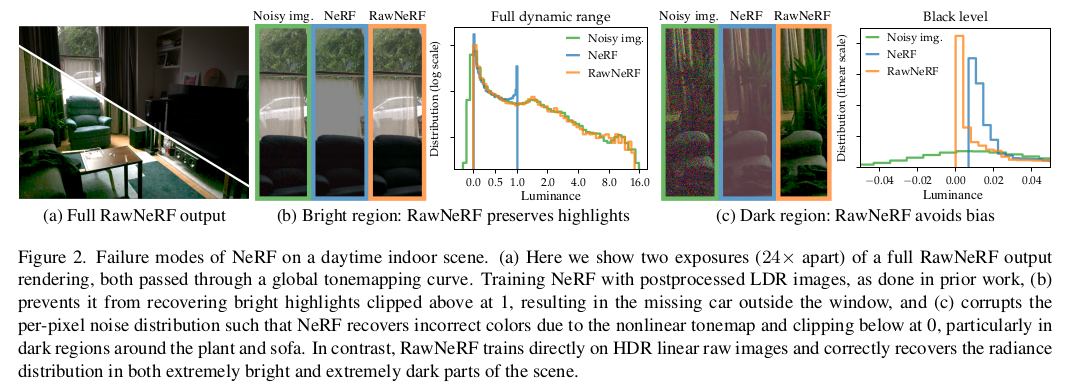
우리가 잘 얻어진 이미지를 그냥 쓰기만 했기 때문에 카메라가 어떻게 이미지를 얻는지, 그리고 잘 이미지를 얻기 얼마나 힘든지를 간과한다. 실제로 보면 너무 밝은데서는 이미지가 하얗게 (1로 포화돼서) 나오고 너무 어두운데서는 R, G, B pepper and salt noise처럼 이미지가 noisy하게 나온다. 이를 그럴듯한 이미지로 만들기 위해선 카메라의 여러 조작을 해야하는데 그런 것 필요없이 그냥 빛 자체 레벨에서 NeRF를 학습시키고자 했다. |
 sensor cell(RGBG)에 각 section은 실제 photon이 얼마나 부딪혔는지를 측정한다. 이 과정에서도 당연히 noise가 있다. photon이 부딪힌 걸 얼마나 정확하게 감지해내느냐는 센서 성능에 따라 다르기 때문이다. 빛을 담기 위해 알아야 할 첫번째 사실. 다행히도 누군가가 모델링해보길, 센서가 측정한 photon 충돌 횟수는 실제 측정된 값이랑 zero mean gaussian 관게로 표현된다고 한다. (이건 참고용 쓰진 않음) |
 pixel이 사실 은 R G B G 4개 센서 값을 모아서 만드는 값이라는 것도 알고 가야 한다. 인간 눈의 원추세포가 R, G, B에 대한 민감도가 다른 것을 반영해서 G가 2개 들어있는 구조인데 이 4개 값을 섞어 pixel color를 만든다. 따라서 pixel color만 보고 NeRF를 학습시킨 다는 것은 뭉뚱그려진 값으로 배우는 것이므로 실제 photon이 부딪힌 횟수와 물리적으로 관계가 있는 R, G, B, G 측정값과는 거리가 있다. (-> pixel color 안쓰고 RGBG 센서값 씀) |
  카메라마다 Color space가 다르다. 다른 말로 같은 대상을 찍어도 카메라 별로 색감이 다르다는 것이다. 이건 실제 측정된 R G B G 측정값의 차이도 있겠지만 이를 후처리하는 과정이 다르기 때문. 색감을 대충 통일시키기 위해서 white balance coefficient가 곱해지는데 이것도 카메라마다 다름 (pixel color로 학습시키면 안되는 이유 ++) |
 마지막으로 후처리로 만들어 낸 pixel color를 이젠 0~255 값으로 담아내야 하는데 그 범위가 애초에 너무 컸다면 255 개 값으로 표현하기 한계가 있으므로 이미지가 너무 밝게 나와버리거나 너무 어둡게 나와버릴 수 있다. 따라서 dynamic range를 보고 전체 색상값을 최대한 "예쁜 이미지"로 만들기 위한 clipping + non linear mapping을 한다. 여기서 clipping 때문에 빛은 얼마나 밝던 무조건 255가 돼버리고, 특정 빛 이하는 무조건 0이 돼버리기도 한다. 따라서 gamma correction + tonemapping까지 다 적용된 최후의 이미지는 맨 처음 카메라에서 얻은 빛과는 상당히 거리가 멀다. (pixel color로 학습시키면 안되는 이유 ++) |
  |
 그래서 어떻게 할 것이냐. 앞서 계속 언급한 것처럼 맨 처음 카메라 센서에서 pixel로 만들기도 전인 senser cell 측정값 R G B G 4개 값을 갖고 곧바로 NeRF를 학습시킨다. 아무런 처리가 되지 않은 날 것의 Raw value로 학습한다고 해서 RawNeRF다. NeRF가 날 것의 값을 만들도록 하고 후처리를 inference 때 하는 방식으로 분리해서 원하는 카메라로 찍은 듯한 이미지를 무한정 만들어낼 수 있다. 완전 공간의 빛 자체를 담는 것. |
  |
학습은 의외로 간단하다.  센서값 그대로를 사용한다면 gamma correction 전이기 때문에 값의 범위가 엄청 넓다. 따라서 MSE Loss 경향 상 큰 값이 더 크게 반영되고, 작은 값은 더 작게 반영되므로 "밝은 영역"만 잘 배울 가능성이 있다. 따라서 한 번 범위를 건드려 학습 균형을 맞추어줄 필요가 있는데, 이는 카메라에서 후처리로 색 범위 조정에 쓰던 tone mapping function을 씌워주는 것으로 해결한다. loss function에만 적용되는 것. log(y+eps) 형태로 그냥 log 임. ----- 근데 하나 문제가 함수가 log다 보니까 기존에 R,G,B,G 측정 값이 실제 Photo 충돌 횟수와 갖고 있던 zero mean gaussian 관계 (예쁘고 아름다운 관계)가 틀어진다. loss 측면에서 R G B G 예측 값이 실제 공간의 빛과 non linear 관계가 된다는 것. -> 학습 효율이 떨어질 수 밖에 없음 이를 또 해결하기 위해서 tone mapping function을 그대로 사용하지 않고 국소적으로 linearize해서 사용함. |
  exposure는 어떻게 담을 것이냐. 앞서 NeRF가 RGBG 값을 예측했다면 이걸 exposure time만큼 scaling해줘서 최종 값을 만들었다. 실제로도 shutter를 얼마나 열어두냐에 다라 해당 sensor cell이 photon을 더 취득하므로, NeRF 예측 RGBG값이 해당 공간의 단위 시간 당 photon 충돌량이라고 가정하는 것. |
따라서 여기다 exposure time을 곱해줘 버리면 카메라 shutter가 열려있는 동안 해당 공간에 지나간 photon의 총량을 알게 되는 것 (아주 멋있음...) 근데 아쉽게도 카메라 물리적인 한계로 shutter speed랑 exposuretime이 완전 일치하지 않는다고 함. 따라서 카메라마다 보정 가능성을 열어두기 위해서 exposure time 별로 time scailing factor를 learnable 로 추가!  |
 |
|
  |
 |
 |
반응형