반응형
내 맘대로 Introduction

Virtual try on, CVPR2024에서 가장 유명세를 탄 논문. SD Freeze하고 각종 컨디션으로 fine tuning하는 방법이 고정되어 있으므로 구조적 특성은 크게 없다. 하지만 fine tuning의 핵심인 cross attention 과정에서 어떻게 하면 attention을 옷 위치로 유도할 수 있을지 augmentation과 loss function을 고민한 점이 눈에 띄는 논문.
깔끔한 코드 공개로 확인도 쉬우니 신뢰성이 높다.
메모
 |
|
 |
1) 입력 masked image mask denpose CLIP(cloth) VAE(cloth) noise(model) 독특하게 SD encoder만 붙여서 tuning을 했다. decoder는 왜 안 썼을까. 메모리 문제였나. |
  |
zero mlp로 초기화된 cross attention layer를 넣어서 tuning하는 방식. 독특할 건 없음. 주목할 점은 cross attention layer로 해결했다! 가 아닌 일단 해결하려고 했고, 그럼에도 불구하고 분석해보니 성능이 안 좋아서 추가 조치를 취했다 <- 이부분. 다른 논문보다 그래도 좋은 부분. |
 |
|
  |
첫번째 조치는 입력 augmentation을 random shift를 포함해서 빡세게 해주면 나아진다는 것. 위 그림 처럼 cross attention으로만 하면 (a)처럼 퍼지고 대충 attnetion 됨. random shift augmentation 넣으면 조금 더 완화된다는 걸 발견함.  supplementary에 적어뒀다길래 뭐가 더 있을 줄 알았으나 진짜 random shift가 핵심. |
  |
augmentation으로 줄어들긴 했지만 그래도 아쉬운 결과. 두번째 조치는 mask 영역(옷 채워넣을 영역)의 token query로 attention을 관찰해보았을 때, attention의 중심 위치가 이미지 전반에 걸쳐서 고르게 펼쳐져 있도록 유도함 -> query point 하나에 대해서 attention이 저 멀리, 저 가까이 중구난방으로 펼쳐질 수 있도록 자유도가 열려있다 보니 (b)처럼 attention이 1개로 모이진 못하는 느낌 -> 주변 query point의 attention과 영역 나누기를 잘 하도록 제한해서, query point 하나가 한 영역만 보고 나머지는 주변 query point가 보도록 유도하는 느낌. -------------- 이 loss function은 좋은 것 같음.  이렇게하면 확실히 잘 되나봄. |
 |
 |
 |
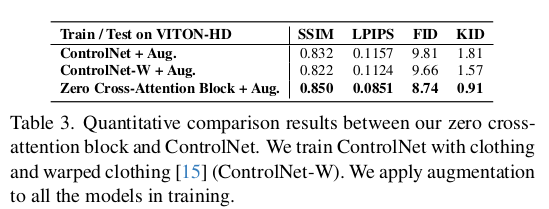 |
 |
 |
반응형