반응형
내 맘대로 Introduction

2022~2023 나온 논문이라서 조금 옛 것(이젠 1년만 지나도...)이지만 요즘 나오는 Virtual Try-on는 전부 다 diffusion인데 반해 이 논문은 그래도 warping + generation으로 방식이 차이가 있어서 기록해둔다. diffusion으로 넘어온 이후 이제는 굳이 다루지 않아도 되는 부분들이 있지만 그냥 간단히 기록해둔다.
메모
 |
|
  |
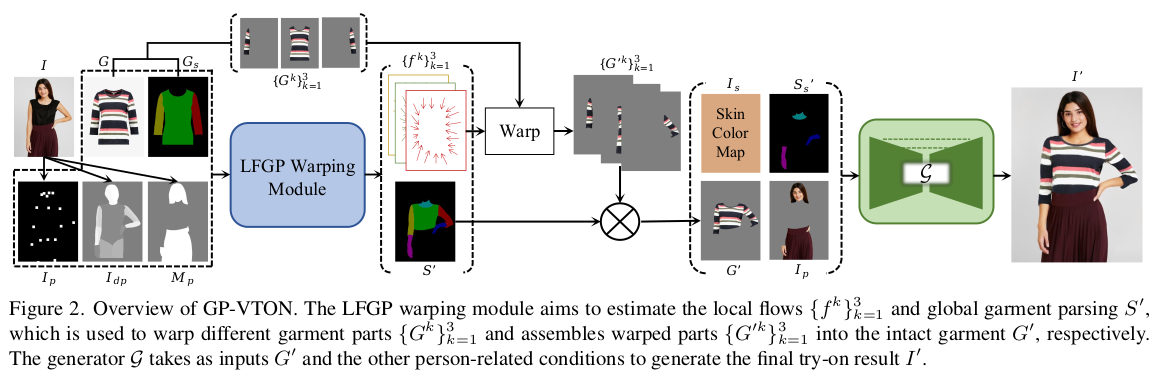
큰 컨셉은 옷 파트 별로 warping field를 예측 한 뒤, warped image를 기준으로 generation하는 것이다. 어설프게 나마 초기값을 잡아줘서 generation 난이도를 확 낮추는 것. DGT 학습 방식은 옷을 넣어입냐 빼입냐, 같은 차이를 반영하도록 유도하는 학습 방식. |
 |
|
  |
 말이 길다. 하지만 핵심은 1) pose, segmentation, mask에서 뽑은 pose feature 2) 옷, 옷 segmentatino에서 뽑은 garment feature로 coarse-to-fine, cascade 방식으로 1) 옷 warp field 2) 새로운 자세 옷 segmenation을 예측하는 모듈. flownet2 방식을 따라 구조를 설계했다는데 이제는 굳이 참고하지 않아도 되는 구조. |
  |
 위 그림처럼 옷을 넣어입는 경우는 옷이 짧게 표현되어야 하는데, 입력 옷 mask가 클 경우 무조건 mask에 맞춰 크게 (혹은 늘어난 것처럼) 표현된다. 이를 방지하기 위한 gradient truncation을 넣었다는 얘기. -> 해당 샘플에서 나오는 gradient로는 업데이트 안한다는 얘기 ------------- 입력 옷의 aspect ratio와 출력된 이미지 상의 옷 aspect ratio 차이가 클 경우, 넣어입는 옷이라고 생각하고 gradient가 크게 발생해도 가끔 무시해주는 식으로 학습 시키는 것. 비율 차이가 크면 50% 확률로 무시해서, 네트워크가 넣어입는 것도 생성하도록 함. |
 |
generator는 요즘과 달리 처음부터 학습. diffusion 없을 시기; |
 논문에서 상의만 다뤘는데 하의나 드레스도 가능하다는 내용. |
 |
 |
|
 |
 |
 |
반응형