반응형
내 맘대로 Introduction

이 논문은 기존의 COLMAP과 같은 SfM 파이프라인에 3D implicit surface reconstruction을 추가한 논문이다. SIFT를 이용한 feature matching으로 시작하는 방식은 완전히 버리지 못했지만, triangulation이나 reprojection error를 계산하는 곳곳에 SDF network output을 박아넣어서 결과적으로 camera pose, 3D point, surface가 다 나오도록 설계했다.
딥러닝임에도 optimization에 가까운 NeRF 컨셉과 진짜 optimization인 SfM을 잘 섞은 듯하다. 속도가 엄청 느릴 것이 걱정되고 안정성이 떨어질 것 같은데 새로운 방식을 제안한 것이 의미가 큰 것 같다. 성능을 바라보고 쓴다면 그냥 COLMAP쓰는게 나을 것 같긴 하다.
메모하며 읽기
  |
전체 프레임워크에서 사용하는 implicit function은 VolSDF와 같은 형태로 디자인해서 사용했고, 그 내용을 다시 짚고 시작한다. |
  |
ray sampling할 때 기존 방식들은 uniform sampling + weighted sampling하는 식으로 coarse to fine 형태로 sampling한다. 하지만 지금과 같이 복원 대상 공간이 막연하게 넓을수도, 엄청 좁을수도 있는 애매한 경우, 이러한 방식이 효율이 떨어진다. 왜냐면 첫 uniform sampling은 사람이 구간을 잡아주기 때문이다. 이런 비효율 문제를 없애기 위해서 sphere tracing이라고 불리는 새로운 방식을 제안했다. 시작 위치만 대충 짚어주면, 그 다음부터는 짚어준 위치의 SDF값을 보고 그 만큼 앞으로 진행하는 방식이다. SDF라는 것이 본래 표면에서 떨어진 거리를 의미하는 값이다 보니 이 값만큼 전진하면 표면을 만날 확률이 높다. 따라서 이 값을 믿고 sampling해주면 대충 표면을 찾아가면서 sampling할 확률이 높다. 그림으로 보면 다음과 같다. 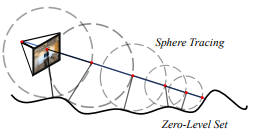 SDF값 크기만큼 전진하는 방식인데 그려보면 이렇게 원 범위를 그리기 때문에 sphere tracing이라고 부르는 것 같다. 여기서 sdf 값을 사용하더라도 sampling 위치를 뽑는데만 사용하는데 (gradient는 끊겨있다는 말인가?? 싶었는데 아닌듯) 간접적으로 loss에도 영향을 주기 때문에 SfM 구현할 때 도움이 됐다는 이야기가 적혀있다. |
 |
notation을 따로 짚어주는데, 기존 SfM에서 등장하는 image feature, matching, track 동일한 의미다. 크게 어려운 부분 없음. |
 |
|
  |
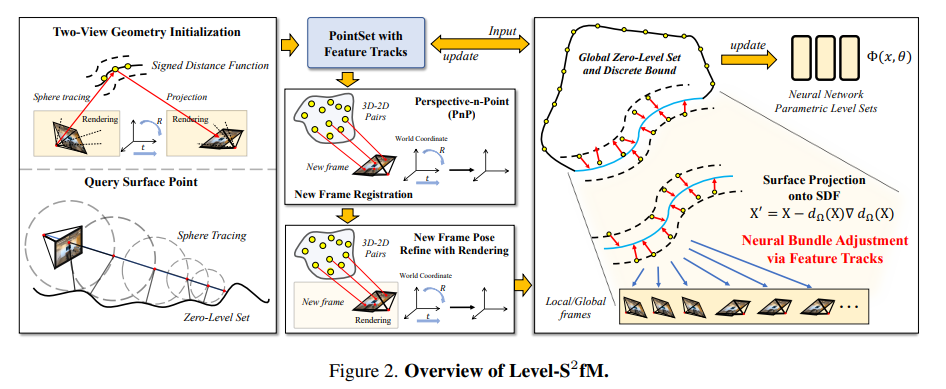
전체 과정 역시 기존 SfM과 거의 동일한 순서다. 먼저 1) two view geometry로 초기화하고 2) 계속 2D-3D correspondence로 frame 추가해 나가면서 3) 다 추가되면 bundle 돌면서 전체를 최적화한다. 다만 intrinsic 까지 같이 추정하는 것은 포기했다. |
 |
two view geometry initialization은 사실 기존방식 그대로다. 추가적으로 neural net loss로 bundle 돌 수 있도록 뭐가 더 붙은게 특별한 거지 초기화 자체는 원래 방식대로 5 point algorithm + RANSAC으로 푼다. 초기화 하고 나서 camera 간 R|t 의 정확성을 평가하기 위해서 VolSDF rendered color가 correspondence 간에 일치하도록 loss를 걸어준 것이 추가되어 있다. 초기화 이후 학습을 거듭하면 VolSDF color consistency로 인해 pose가 업데이트 된다. (물론 VolSDF도 학습이 잘되어있어야 하는데 그건 추후 다른 loss가 그걸 도와주므로 여기선 pose 업데이트하는 기능이 더 크다) |
 |
위에 color를 이용한 학습이 VolSDF가 아직 불안정한 단계에서는 약간 어려우므로 depth consistency loss도 추가했다고 한다. (이건 뭔가 잘 안돼서 추가한 loss 같은 느낌) sphere tracing (현 sdf로 찾아낸 표면) 결과와 rendered depth와 동일할 것. 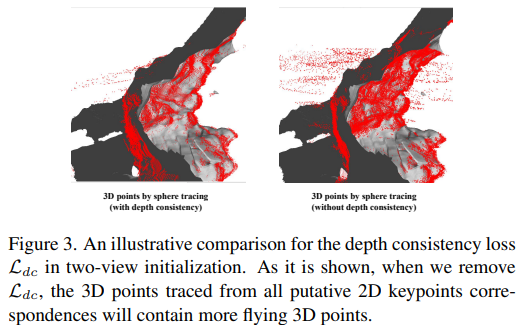 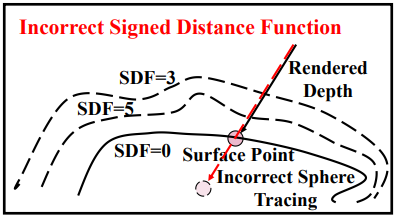 이게 있으면 noise가 가 많이 줄어든다고 한다. |
  |
새로운 프레임 추가하는 것도 기존 SfM과 동일하다 2D-3D correspondence matching한 다음에 PnP 푸는 정해진 방식으로 한다. 이후에 자세 업데이트는 two view geometry init.과 같은 loss로 진행하되 depth consistency loss는 뺐다. (역시 two view 초기화가 잘 안돼서 추가한 loss가 맞았던 것 같다.) |
  |
Incremental 하게 프레임을 추가해 나가면서 3d point도 계속 올리는 것을 할텐데 이 과정에서 그냥 일반 point triangulation할 수 있지만 VolSDF도 학습이 되긴 해야 하니 SDF-based triangulation을 개발했다고 한다. st라는 notation이 설명이 안돼있어서 이해하기가 좀 까다로운데, 내용은 2D correspondence를 각각 sphere tracing해서 얻은 3d point들은 registration에서 얻은 3d point들과 일치해야 한다는 것이다. (SfM 결과물은 카메라 포즈 + 3D point) |
 |
4.3 까지 loss들로 학습되면 업데이트 되는 값들은 카메라 포즈와 VolSDF이다. 3d point는 처음 registration할 때 올려진 값으로 남아있다. 전체적으로 3d point 관점에서 업데이트해주는 loss가 하나가 존재해야 카메라 포즈 + VolSDF+ 3d point까지 한 번에 최적화가 될 것인데 (SfM에서는 3d point reprojection error를 이용한 BA) 여기서 BA를 돌려버릴 수도 있지만 차이점이 없고 3d point 관점에서 VolSDF와 엮이는 것이 너무 적어서 3d point, VolSDF가 따로 놀 수 있으므로 3d point 관점에서의 loss 하나를 추가했다. 3D point 위치를 sdf 값만큼 normal 방향으로 이동시키는 것인데 ( 3d point를 VolSDF가 말하는 surface 위로 이동) 이렇게 하면 위에 말한 이슈들이 조금 완화된다. ------------------- 전체적으로 이거 학습 엄청 복잡하고 안정성 매우 떨어질 것 같다. 그리고 핵심은 기존 SfM과 동일해서 기존 SfM 쓰는게 나은 부분이 더 많아 보임. |
 |
|
 |
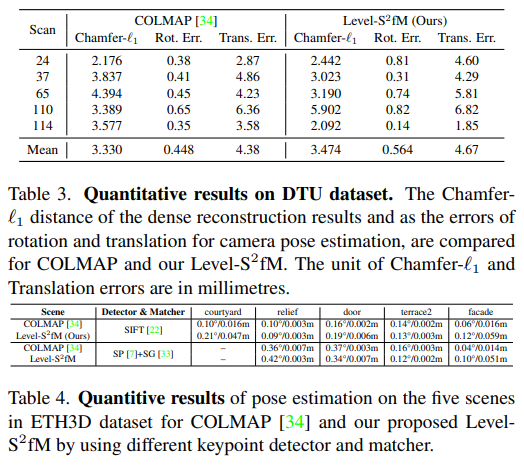 |
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| BARF : Bundle-Adjusting Neural Radiance Fields (0) | 2023.10.30 |
|---|---|
| Self-Calibrating Neural Radiance Fields (0) | 2023.10.30 |
| Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields (0) | 2023.10.25 |
| Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields (0) | 2023.10.24 |
| Progressively Optimized Local Radiance Fields for Robust View Synthesis (0) | 2023.10.23 |